Two years into a major financial services engagement, I got paged at 2am because a developer had SSH’d into a production Kubernetes worker node, installed htop and a few debugging tools, and accidentally corrupted the container runtime. The node started making strange decisions: pods were scheduling but not starting, and the kubelet logs were full of errors that had no business being there. It took six hours to figure out that an inadvertent apt upgrade had bumped a shared library that containerd depended on. The node was silently running a different version of reality from every other node in the cluster.
That incident crystallized something I had been circling for years: the traditional mutable Linux server model is fundamentally incompatible with how Kubernetes is supposed to work. Kubernetes assumes homogeneous nodes. The moment any one of them has a different kernel, different cgroups behavior, different library versions, or different configuration from a manual SSH session, you have a fleet that is only nominally homogeneous. The drift is invisible until it kills you.
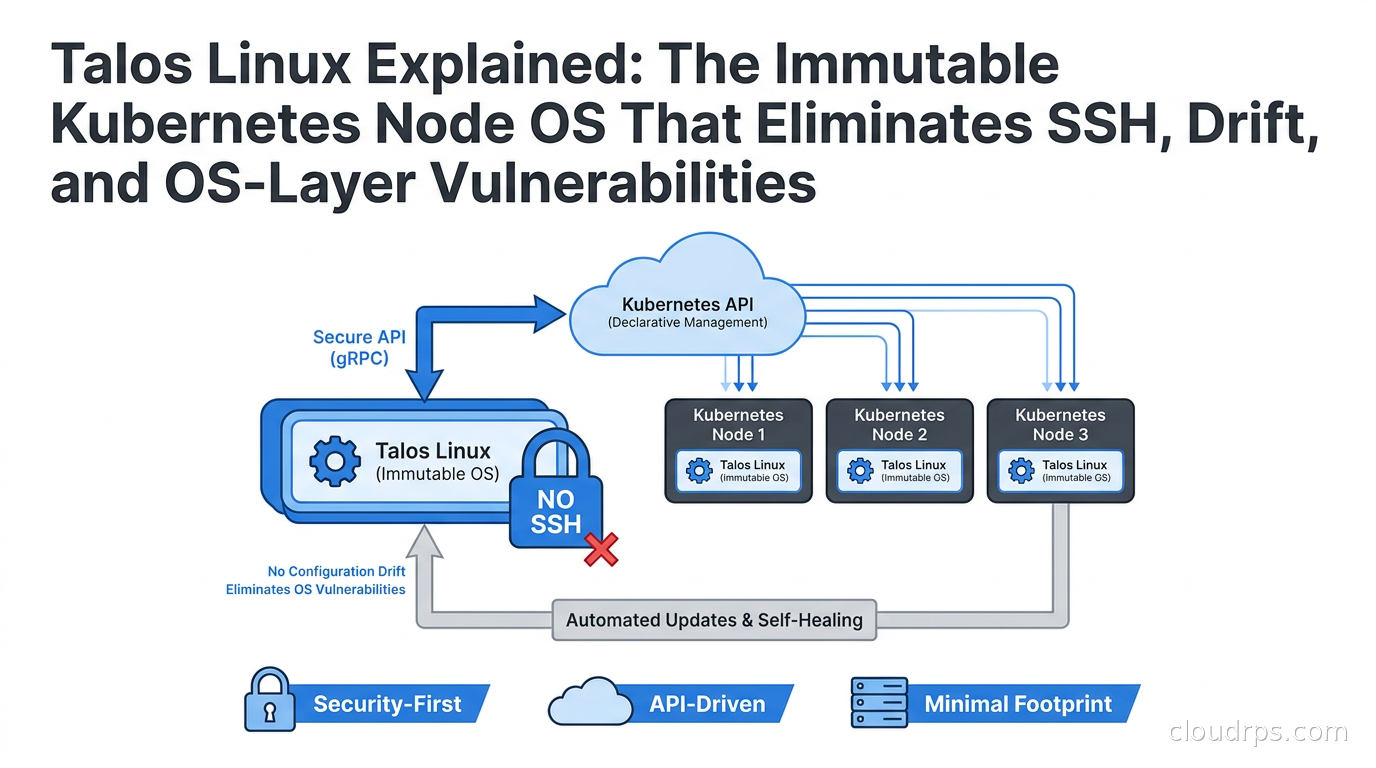
Talos Linux is the most radical answer to this problem I have seen in twenty years of building infrastructure. It eliminates the problem by removing the entire attack surface: no SSH, no shell, no package manager, no mutable filesystem. Just Kubernetes, an API, and an immutable image. This article explains how it works, where it fits, and how it compares to the other serious options in this space.
Why Traditional Node OSes Break at Kubernetes Scale
When you run Kubernetes at any meaningful scale, you stop thinking about individual nodes and start thinking about fleets. A node should be a fungible unit of compute; if it misbehaves, you cordon it, drain it, and replace it. This mental model breaks completely if your nodes are pets instead of cattle.
The problems with running Kubernetes on a general-purpose Linux distribution like Ubuntu or RHEL are well-documented but still underappreciated in practice.
Drift. Every time someone SSH’s into a node to debug something, the filesystem accumulates state that is not tracked anywhere. Package installations, configuration changes, temporary files, kernel module loads: all of it creates invisible divergence between nodes. Two weeks later, one node behaves differently from the rest, and you spend a day bisecting the problem. I have seen clusters where nodes in the same node group had three different kernel versions because patching had been done incrementally and inconsistently over eighteen months.
Attack surface. A full Ubuntu installation has thousands of packages, many with no relevance to running containers. Each one is a potential vulnerability. The NSA Kubernetes hardening guide dedicates entire sections to minimizing the OS footprint on worker nodes for exactly this reason: if an attacker compromises a container and breaks out to the host, the richness of a full Linux userspace is their playground.
Patching latency. Kernel CVEs happen constantly. On a general-purpose OS, patching means SSH, apt update, apt upgrade, reboot, and pray the node rejoins the cluster cleanly. At scale, this process is error-prone and slow. Teams skip patch cycles because the coordination overhead is too high, and vulnerability windows stay open for months.
No auditability. There is no clean way to verify that a fleet of traditional Linux nodes matches a declared desired state. Tools like Ansible help, but they are eventually-consistent at best and cannot account for manual changes made between runs.
What Immutable OS Actually Means
The term “immutable OS” gets thrown around loosely. For Kubernetes purposes, it means a few specific things.
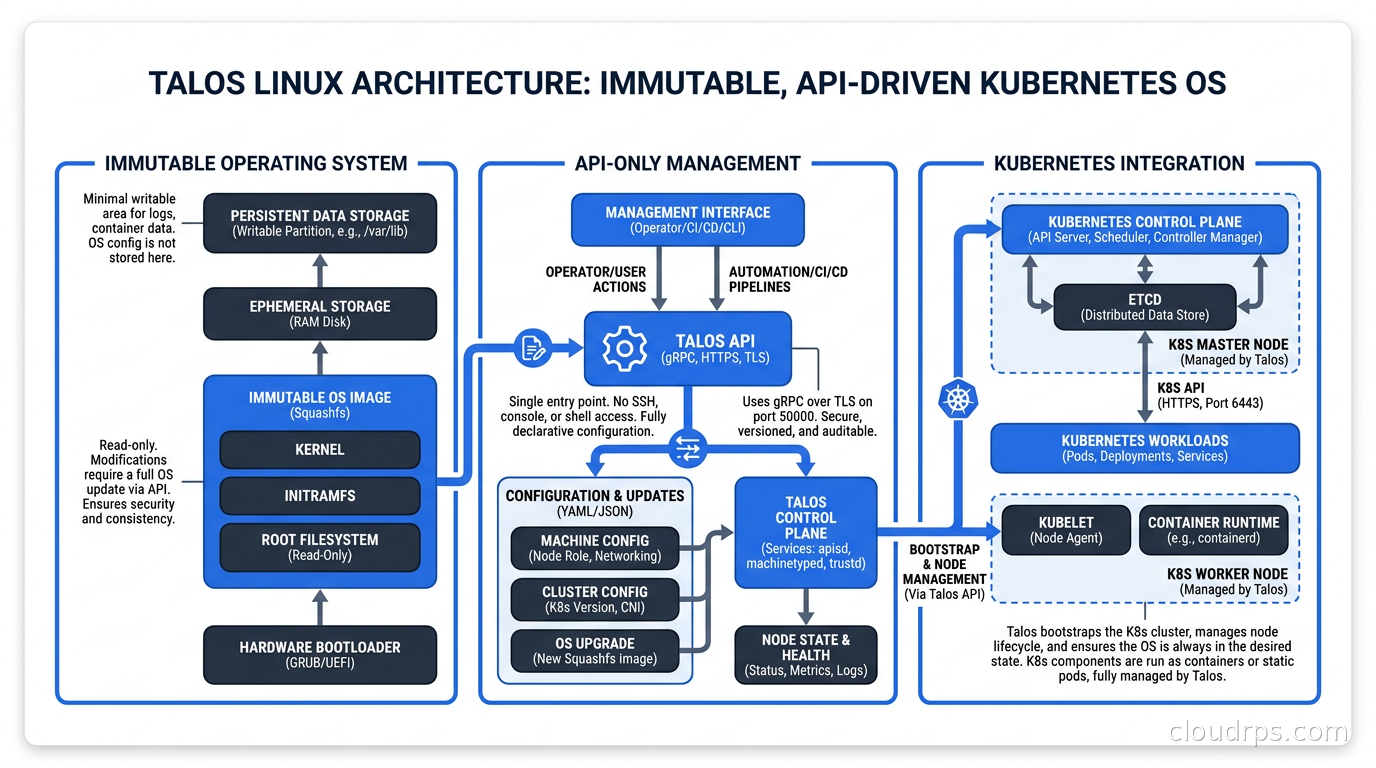
Read-only root filesystem. The OS partition cannot be written to at runtime. Configuration changes require either a machine config update applied via API or a full OS image update.
No package manager at runtime. You cannot install software on the running node. If you need a debugging tool, you run it as an ephemeral container in the cluster. If you need a kernel module, it must be baked into the image.
Atomic updates. OS updates are applied as a whole image swap, not as incremental package upgrades. The node boots the new image or falls back to the previous one. There is no partial-upgrade state that leaves the node in an unknown configuration.
Managed via external tooling, not SSH. The operational model is declarative: you describe what you want, an API applies it, and the node converges. You do not interactively manipulate the running system.
This model trades the flexibility of a general-purpose OS for operational predictability and security. For Kubernetes nodes, that tradeoff is almost always worth making.
Talos Linux: The Radical Approach
Talos Linux, developed by Sidero Labs, is the most opinionated implementation of the immutable OS concept I have worked with. It does not try to be a general-purpose OS that happens to support immutability. It was designed from scratch to run Kubernetes and nothing else.
The key design decisions set it apart from everything else in this space.
No SSH. Full stop. There is no SSH daemon, no sshd, no remote shell of any kind. The only way to interact with a Talos node is through its gRPC API, using the talosctl command-line tool with mutual TLS authentication.
No shell. There is no bash, no sh, no interactive shell you can drop into. The system binary count is minimal by design. Sidero Labs has cited twelve core binaries in some versions of the OS.
API-driven configuration. Every aspect of node behavior is expressed as a YAML machine config document. Network configuration, Kubernetes component flags, extra kernel arguments, user data: all of it goes into the machine config and is applied through the authenticated API. The configuration is version-controlled, diffable, and reproducible across your entire fleet.
Immutable filesystem with overlays. The root filesystem is read-only. Ephemeral state lives in a separate partition. Persistent state (kubelet data, etcd data) lives on a designated data disk. There is no way to accidentally pollute the OS partition during normal operation.
Working with Talos for the first time feels genuinely disorienting if you are used to traditional Linux administration. You cannot ssh root@node and poke around. When something goes wrong, you read logs via talosctl logs -n <node> kubelet. When you need to upgrade the OS, you run talosctl upgrade --image ghcr.io/siderolabs/installer:<version>. The mental model shift takes a week or two, but the operational confidence you gain afterward is significant and measurable.
The Talos API requires a bootstrap secret (the machine config), which is typically generated per-cluster and stored securely. Control plane and worker nodes receive different configs with different roles. The config includes the Kubernetes version, API server endpoint, network settings, and any extra manifests to apply at bootstrap time.
One practical limitation: Talos does not support running arbitrary processes outside of Kubernetes. If you need a node exporter, you run it as a DaemonSet. If you need a disk encryption daemon, there is a Talos extension for it. This is the correct model for dedicated Kubernetes nodes, but it means Talos is only appropriate for machines that are purely Kubernetes workers or control plane nodes.
Flatcar Container Linux: The CoreOS Successor
Flatcar Container Linux is the spiritual successor to CoreOS, which was the original production-focused immutable OS for containers. After Red Hat acquired CoreOS and pivoted toward Fedora CoreOS and RHCOS for the OpenShift ecosystem, the Flatcar project (originally from Kinvolk, now maintained by Microsoft) kept the original CoreOS design philosophy alive.
Flatcar is less radical than Talos. It still has a read-only root partition and atomic updates via the update-engine and locksmith daemons, but it does have SSH, it does have a shell, and it supports running non-Kubernetes workloads. It uses systemd for service management and ignition for initial provisioning.
The update model is particularly good: nodes update in a rolling fashion, with locksmith coordinating reboots across the cluster to avoid taking down too many nodes at once. You can run etcd on Flatcar control plane nodes and have them update safely over time without manual coordination.
I have used Flatcar extensively on bare-metal clusters where we needed to run a small number of system services outside of Kubernetes: hardware monitoring daemons that needed direct device access, out-of-band management agents, that sort of thing. In those cases, Flatcar’s slightly less restrictive model was the right call. For pure Kubernetes nodes where all workloads run as pods, the additional flexibility comes at a cost that is hard to justify from a security standpoint.
Flatcar supports AWS, Azure, GCP, VMware, Equinix Metal, and bare metal. The update system is solid and battle-tested, having evolved from CoreOS Container Linux which was running in production clusters as early as 2014.
AWS Bottlerocket: The Cloud-Specific Option
AWS Bottlerocket is Amazon’s container-optimized OS, designed primarily for EKS but also available for ECS workloads. Like Talos, it uses a read-only root filesystem and an API-driven configuration model. Unlike Talos, it is tightly integrated with AWS services and carries AWS’s operational support model.
The design is similar in spirit to Talos: no package manager, no SSH by default (though an admin container is available for break-glass access), atomic updates via A/B partitions. Bottlerocket maintains two partitions per disk: the current and the fallback. An update swaps the active partition; if the node fails to check in after reboot, it automatically falls back to the previous known-good image.
The compelling feature for AWS shops is EKS managed node groups with Bottlerocket: AWS handles OS updates, node replacement, and version alignment with the EKS Kubernetes version. You get immutability without owning the operational model for it. For teams that do not want to think about node OS management at all, this is a real value proposition.
The downside is portability: Bottlerocket is an AWS product. Running it on GCP or bare metal is technically possible but unsupported and operationally painful. If you are building a multi-cloud or on-premises Kubernetes fleet, Bottlerocket is not the right foundation.
For pure AWS shops running EKS, Bottlerocket is often the correct default. It removes a significant operational burden while delivering the security benefits of immutable nodes.
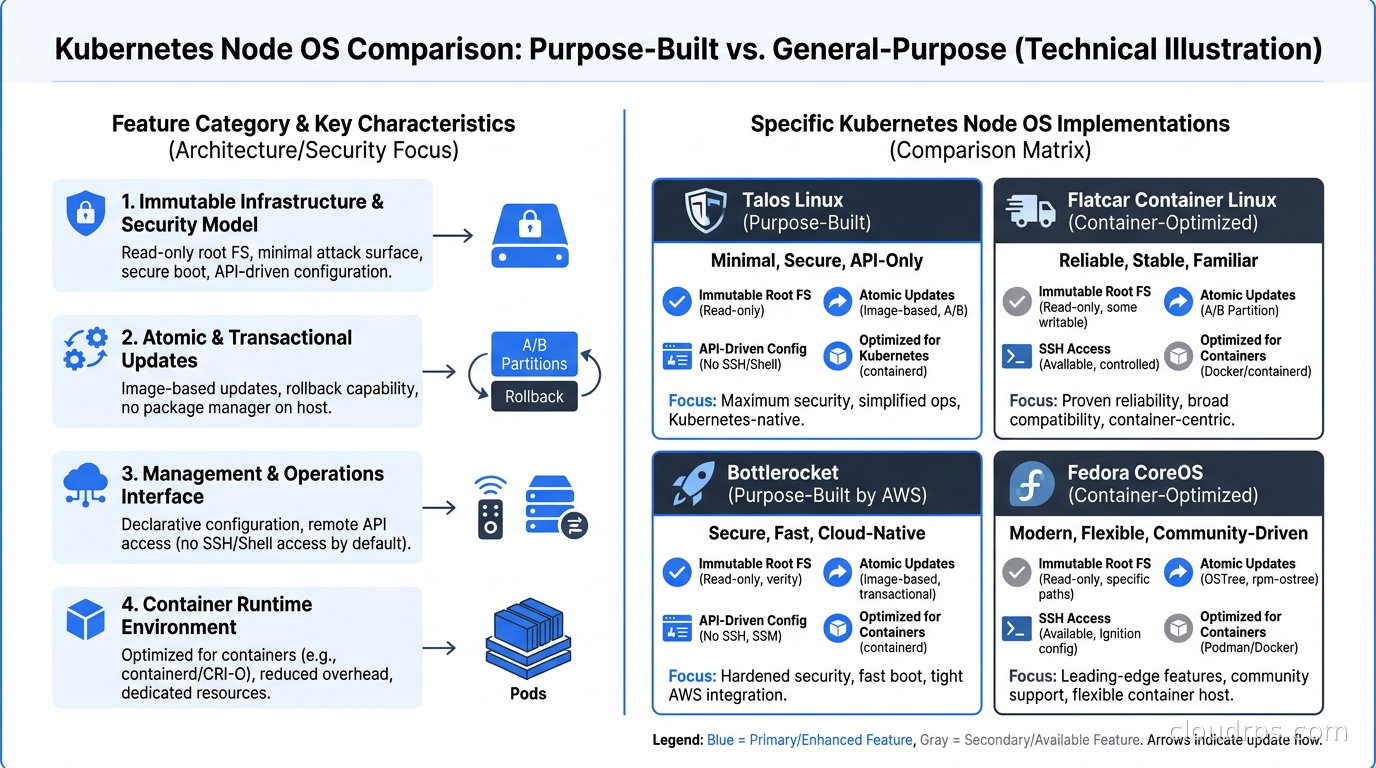
Fedora CoreOS: The Red Hat Ecosystem Choice
Fedora CoreOS (FCOS) is the community upstream for Red Hat’s RHCOS, which is the node OS for OpenShift. If you are running OpenShift or want the Red Hat operational model for node OS management, FCOS or RHCOS is where you land.
FCOS uses rpm-ostree for layered package management (which allows adding packages to an immutable base image) and ignition for provisioning. The update stream model (stable, testing, next) aligns with how Fedora releases work.
The rpm-ostree model deserves a specific call-out: you can layer packages on top of the immutable base, which gets committed as a new tree. This gives you more flexibility than Talos’s strict “no packages ever” approach, but at the cost of needing to manage those layers deliberately. I have seen teams abuse this escape hatch, layering so many packages that the immutability guarantees become meaningless in practice. The discipline to keep the layer minimal is organizational rather than technical, which is a weaker guarantee.
FCOS is the right choice if you are standardizing on the Red Hat ecosystem, running OpenShift clusters, or need the FIPS-validated OS images and long-term support that RHCOS provides for regulated industries.
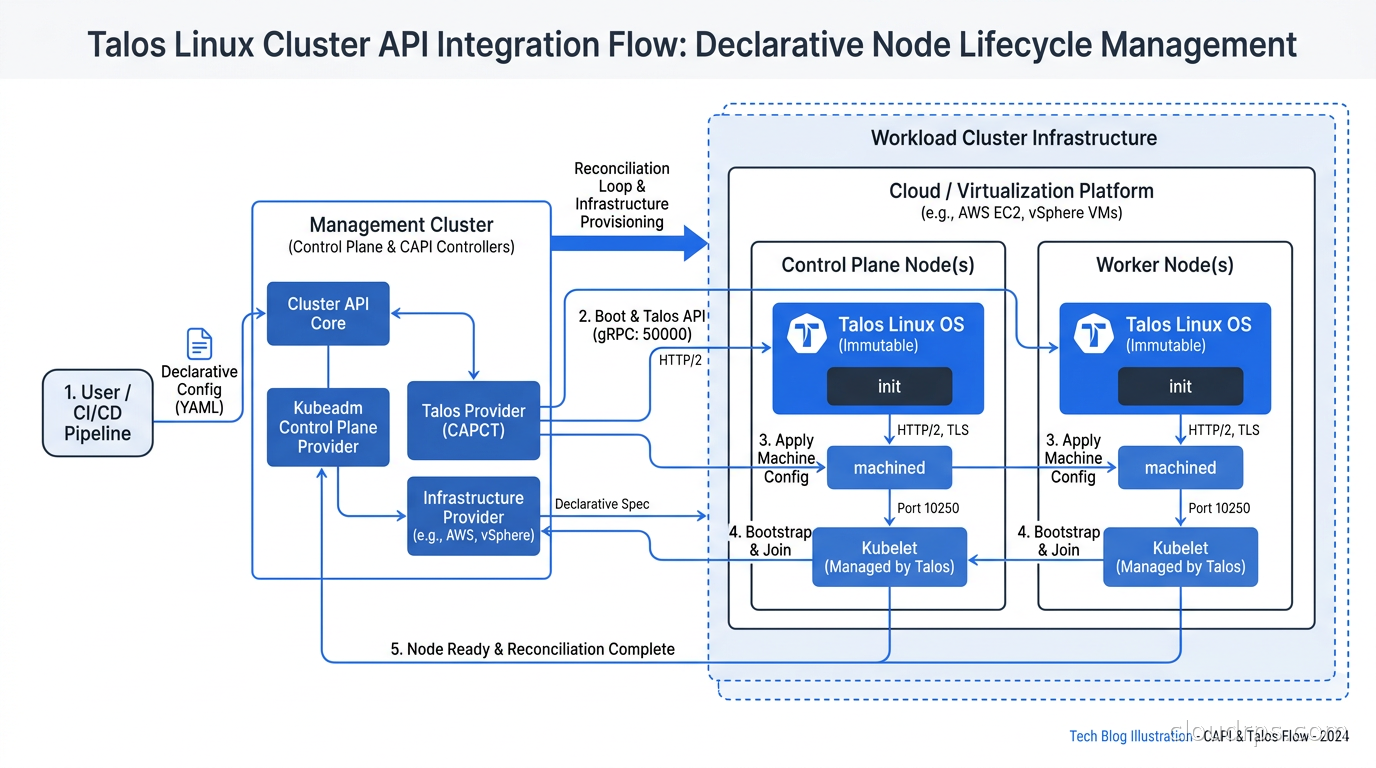
Cluster API: The Missing Piece for Immutable Node Fleets
Immutable OS is most powerful when combined with declarative cluster lifecycle management via GitOps tooling. Cluster API (CAPI) is the Kubernetes-native way to do this: you define your cluster topology, control plane configuration, and worker node machine templates as Kubernetes custom resources, and CAPI controllers provision and manage the physical or virtual machines to match the declared state.
The Talos provider for Cluster API integrates directly with Talos machine configs. You define a TalosControlPlane or worker machine template resource, and CAPI creates the machines, bootstraps them with the correct Talos machine config, and manages their lifecycle going forward. Node upgrades become a declarative operation: you update the machine image in the CAPI template, and the controller drains and replaces nodes in a controlled rolling fashion.
This is the operational model I now recommend for any team running self-managed Kubernetes on bare metal or private cloud. The combination of immutable OS and CAPI declarative lifecycle management eliminates the entire category of problems that manual node management creates. Nodes become truly cattle, not pets, and the operational team stops spending time on node babysitting and starts spending time on platform features.
For the VMware exodus use case, where teams are moving off vSphere and onto bare metal Kubernetes or Proxmox-hosted VMs, CAPI plus Talos is one of the most operationally sound foundations I have recommended. You get the same declarative model you had in vSphere (where the vSphere operator managed machine lifecycle) but without the proprietary dependency and the license costs.
The setup overhead is real: CAPI requires a management cluster (often a small, permanent cluster running only CAPI controllers), and the initial configuration is more complex than just running kubeadm init. But once it is running, the operational leverage is substantial. A team of three engineers can comfortably manage hundreds of nodes.
Security Benefits Worth Quantifying
The security posture improvement from immutable nodes is not theoretical. Let me be specific about what changes in practice.
SSH removal. SSH is one of the most common lateral movement vectors after a cloud workload is compromised. Removing it entirely eliminates the whole class of SSH-based attacks on nodes: brute force, credential stuffing, stolen key exploitation, jump host pivoting. With Talos, even if an attacker has a valid kubeconfig and can exec into a pod, they cannot SSH to the underlying node. The mTLS-authenticated Talos API is a much narrower attack surface than SSH.
No shell for privilege escalation. Container escapes are real. Sandboxing with gVisor or Kata Containers helps, but defense in depth means that even if an attacker reaches the host, they should find a minimal environment. With Talos, there is no shell to escalate into, no sudo, no /usr/bin full of useful attack tooling. The practical blast radius of a container escape is meaningfully smaller.
Reduced CVE surface. A minimal OS has fewer packages, each of which is a potential vulnerability. Talos’s binary count is orders of magnitude smaller than Ubuntu Server. The attack surface for OS-layer CVEs is proportionally smaller, and the time-to-patch for the binaries that do exist is shorter because the update process is automated and atomic.
Auditability. Because all node configuration flows through the machine config API and the OS is immutable, you can definitively verify the state of your fleet at any point. There is no “what did someone do in that SSH session” uncertainty, no drift that accumulated between Ansible runs. The node is either running the declared config or it is not.
This connects directly to the principles behind container image hardening: the same logic that makes distroless container images more secure (remove everything you do not need) applies at the OS layer. Talos is effectively the distroless philosophy applied to the Kubernetes node itself.
The Operational Learning Curve
I want to be honest about the cost, because it is real. Talos has a genuine learning curve, and underestimating it leads to frustration.
Debugging is different. You cannot tail -f /var/log/syslog from a shell. You use talosctl logs, talosctl dmesg, and talosctl service. If you need to run a diagnostic tool that does not exist on the node (which is everything, because almost nothing exists), you run it as an ephemeral container in the cluster using kubectl debug.
Networking troubleshooting requires different muscle memory. Tools like crictl for container runtime inspection or etcdctl for etcd health checks are invoked via talosctl subcommands rather than by SSHing into the control plane and running them directly. You read /proc/net/... files via talosctl read, not by catting them from a shell.
For teams with Kubernetes expertise but traditional Linux backgrounds, the transition takes about two to four weeks before it feels natural. For teams that are cloud-native from the start, with no prior muscle memory for SSH-based node debugging, Talos often feels like the way things should have always worked.
The payoff is real and measurable. In clusters I have run on Talos for two-plus years, there have been zero incidents attributable to node configuration drift. The 2am pages about manual changes corrupting production environments have stopped. Node upgrades happen on a predictable schedule because the process is automated and idempotent.
Choosing Between the Options
Here is how I think through the decision in practice.
Choose Talos Linux if: You are running bare metal or private cloud Kubernetes, you want maximum security guarantees, you are comfortable with the no-SSH operational model, and you want to use Cluster API for lifecycle management. Talos is also well-suited for air-gapped or regulated environments where the reduced attack surface is a compliance requirement.
Choose Flatcar Container Linux if: You need occasional non-Kubernetes system services running directly on the node, you are migrating from a CoreOS-based setup, or you want immutability and atomic updates without giving up SSH entirely.
Choose AWS Bottlerocket if: You are running exclusively on AWS with EKS, you want AWS to handle OS update operations, and you are not interested in owning the OS lifecycle management yourself.
Choose Fedora CoreOS or RHCOS if: You are in the Red Hat ecosystem, running OpenShift, or need FIPS-validated OS images and commercial support for compliance in regulated industries.
Getting Started Without a Full Commitment
One approach I recommend for evaluating Talos: start with a non-production cluster on bare metal or a set of VMs before committing to a production rollout.
Provision it using talosctl gen config <cluster-name> <control-plane-endpoint> to create your machine configs. Boot the nodes from the Talos ISO or disk image (it fits on a USB drive and can PXE-boot for bare metal). Apply the configs via talosctl apply-config --insecure --nodes <ip> --file controlplane.yaml. The full Kubernetes setup is typically complete in under 30 minutes.
Then spend two to four weeks operating it. Do a Kubernetes version upgrade. Do an OS version upgrade. Simulate a node failure and replace it via CAPI or manually. Run talosctl for common debugging tasks you would normally do via SSH. By the end of that period, you will know definitively whether the operational model works for your team.
For the Kubernetes RBAC and eBPF-based network policy layers, nothing changes with Talos: those operate at the Kubernetes layer and are orthogonal to the node OS. You still define namespaces, roles, ClusterRoles, and network policies exactly as you would on any other Kubernetes cluster.
The Talos documentation is genuinely well-written. The community Discord is active and the maintainers respond quickly. Sidero Labs offers commercial support for production deployments, which matters for enterprises that need contractual SLAs.
The Bigger Picture
The move toward immutable infrastructure is not just a trend; it is the inevitable consequence of operating infrastructure at scale. The more nodes you have, the more the traditional mutable model breaks down under its own operational weight. The more security matters, the harder it becomes to justify SSH access to production nodes running sensitive workloads. The more you automate, the more you need a substrate that automation can reason about reliably.
Talos Linux is the most aggressive implementation of these principles available today. It is not for everyone: it requires learning a new operational model and accepting genuine constraints on how you interact with your nodes. But for teams that have felt the failure modes of mutable Kubernetes nodes, those constraints are not limitations. They are features.
The 2am incident that started this article happened on an Ubuntu-based cluster. The replacement cluster ran Flatcar. Two years after that, the production clusters I consult on run Talos. The operational confidence gap between those three generations is not subtle. Twenty years of building infrastructure has taught me that the things that seem like overengineering at first usually turn out to be the decisions you are grateful for when something goes wrong at the worst possible time.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.