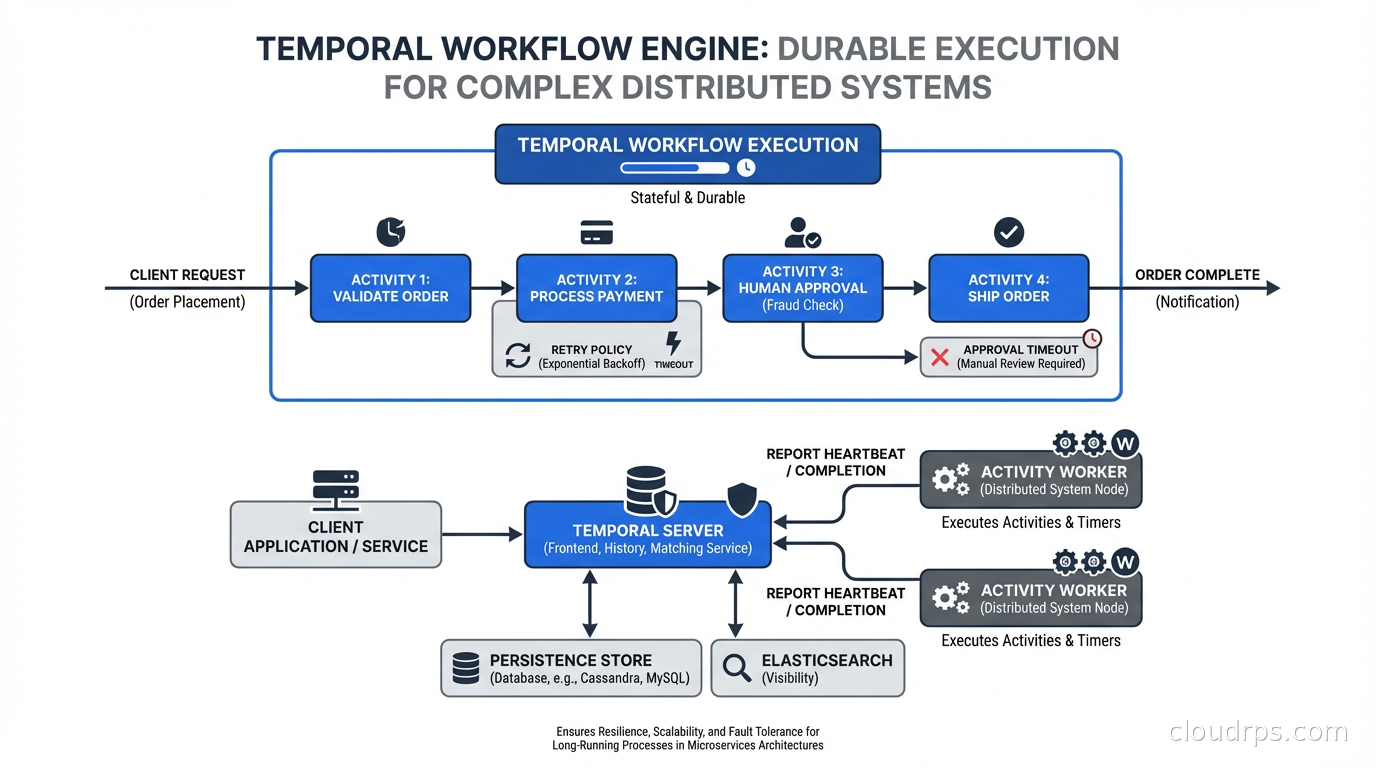
Every distributed system eventually runs into the same category of problem: you need to do something that involves multiple steps, takes time, can fail at any point, and needs to eventually complete correctly even if individual components go down. Order processing that spans inventory check, payment, fulfillment, and notification. User onboarding that involves creating accounts in five systems, sending emails, and waiting for verification. Document processing that involves OCR, classification, review, and approval. Data pipeline steps that depend on external APIs with spotty reliability.
The traditional solutions are all painful. Message queues with saga choreography: distributed state that’s impossible to reason about, debug, or rollback correctly. Cron jobs with database-stored state: works until it doesn’t, and when it breaks the debugging experience is miserable. Homegrown state machines: works for simple cases, becomes a maintenance nightmare as business rules evolve. Workflow databases with polling: slow, resource-intensive, hard to scale.
Temporal is a different approach, and it’s one of the most important pieces of infrastructure I’ve encountered in the last five years. The concept is called “durable execution”: write your workflow as ordinary code, and the framework ensures it runs to completion even through server crashes, network partitions, and arbitrary failures.
What Durable Execution Actually Means
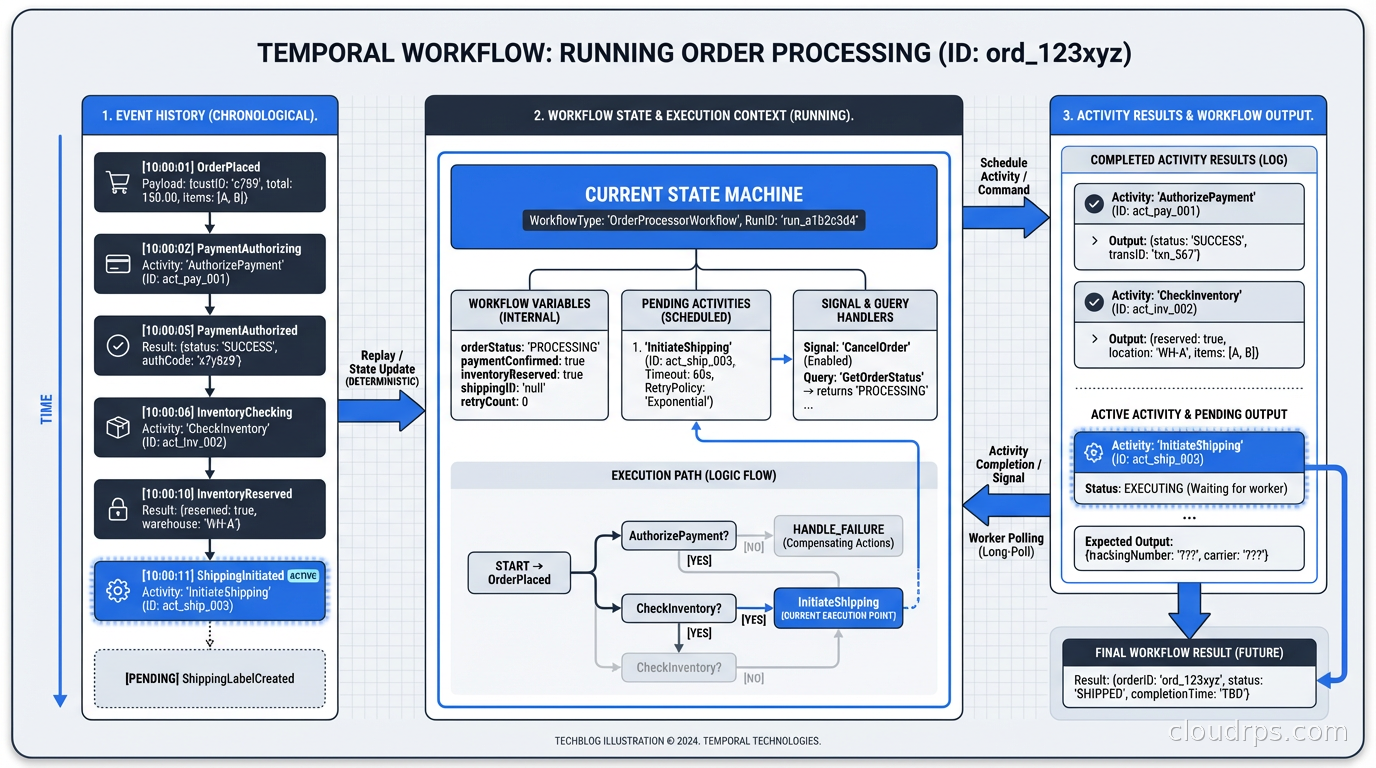
The key insight of Temporal is that it records everything your workflow code does and can replay that history to reconstruct the workflow’s state at any point. This is different from persistence layers that save state periodically; Temporal persists every state transition at the moment it happens.
When a Temporal worker process crashes mid-workflow, another worker picks up the workflow, replays the full history (which is fast because it’s replaying an event log, not re-executing side effects), and continues from exactly where it left off. Your workflow code runs as if nothing happened. You don’t write crash recovery logic. You don’t write retry logic for infrastructure failures. Temporal handles it.
This is what “durable execution” means: your code’s execution is made durable through event sourcing. The code you write looks like sequential, synchronous code. The framework turns it into an event-driven, fault-tolerant, distributed execution.
Here’s what a Temporal workflow looks like in Python:
@workflow.defn
class OrderProcessingWorkflow:
@workflow.run
async def run(self, order: Order) -> OrderResult:
# Each activity call is automatically retried on failure
# State is preserved across worker crashes
inventory_result = await workflow.execute_activity(
check_inventory,
order.items,
start_to_close_timeout=timedelta(seconds=30)
)
if not inventory_result.available:
return OrderResult(status="out_of_stock")
# This payment step will retry automatically on transient failures
payment_result = await workflow.execute_activity(
process_payment,
order.payment,
start_to_close_timeout=timedelta(minutes=2),
retry_policy=RetryPolicy(maximum_attempts=3)
)
# Wait for human approval - can wait days without consuming resources
approval = await workflow.wait_condition(
lambda: self._approval_received,
timeout=timedelta(days=7)
)
await workflow.execute_activity(
fulfill_order,
order,
start_to_close_timeout=timedelta(minutes=10)
)
return OrderResult(status="fulfilled")
This looks like simple async Python. But this workflow can survive your entire server fleet going down and coming back up, can wait for a human approval for days without consuming any server resources, automatically retries failed activities with exponential backoff, and gives you full visibility into its state through the Temporal UI. You didn’t write any of that explicitly.
The Architecture Under the Hood
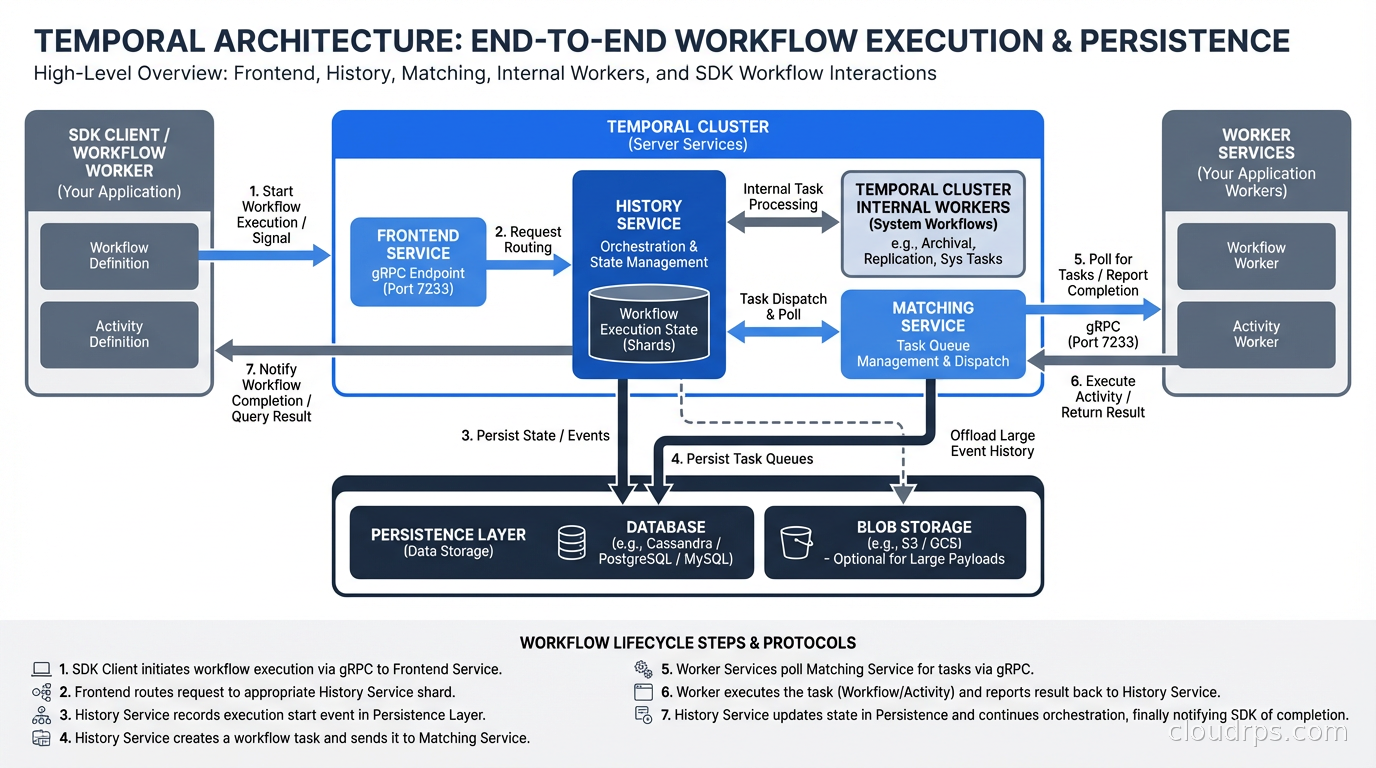
Temporal has a server component (the “Temporal server” or “Temporal cluster”) and client libraries (SDKs for Go, Java, Python, TypeScript, .NET, and others). The server handles durability, state management, and worker coordination. Your code runs in worker processes that connect to the Temporal server.
The server consists of several services: Frontend (the gRPC API layer), History (maintains workflow state), Matching (routes tasks to workers), and Worker (internal workers for Temporal’s own operations). For production, you run these as separate services for scalability. The persistence layer is pluggable: Cassandra, PostgreSQL, or MySQL for workflow state storage.
When your workflow code calls execute_activity, Temporal schedules an activity task in the task queue. An available worker picks up the task, executes the activity function, and reports the result back to the Temporal server. The server records this result in the workflow’s event history and sends a decision task back to the workflow worker to advance the workflow. The workflow worker replays the history (completing previously-executed steps instantly from cached results) and runs forward until it hits the next blocking point.
This replay mechanism is the key to durable execution. The determinism requirement follows from it: workflow code must produce the same results when replayed. No random number generation, no direct time lookups, no direct I/O. All of these go through Temporal SDK functions that return recorded values during replay.
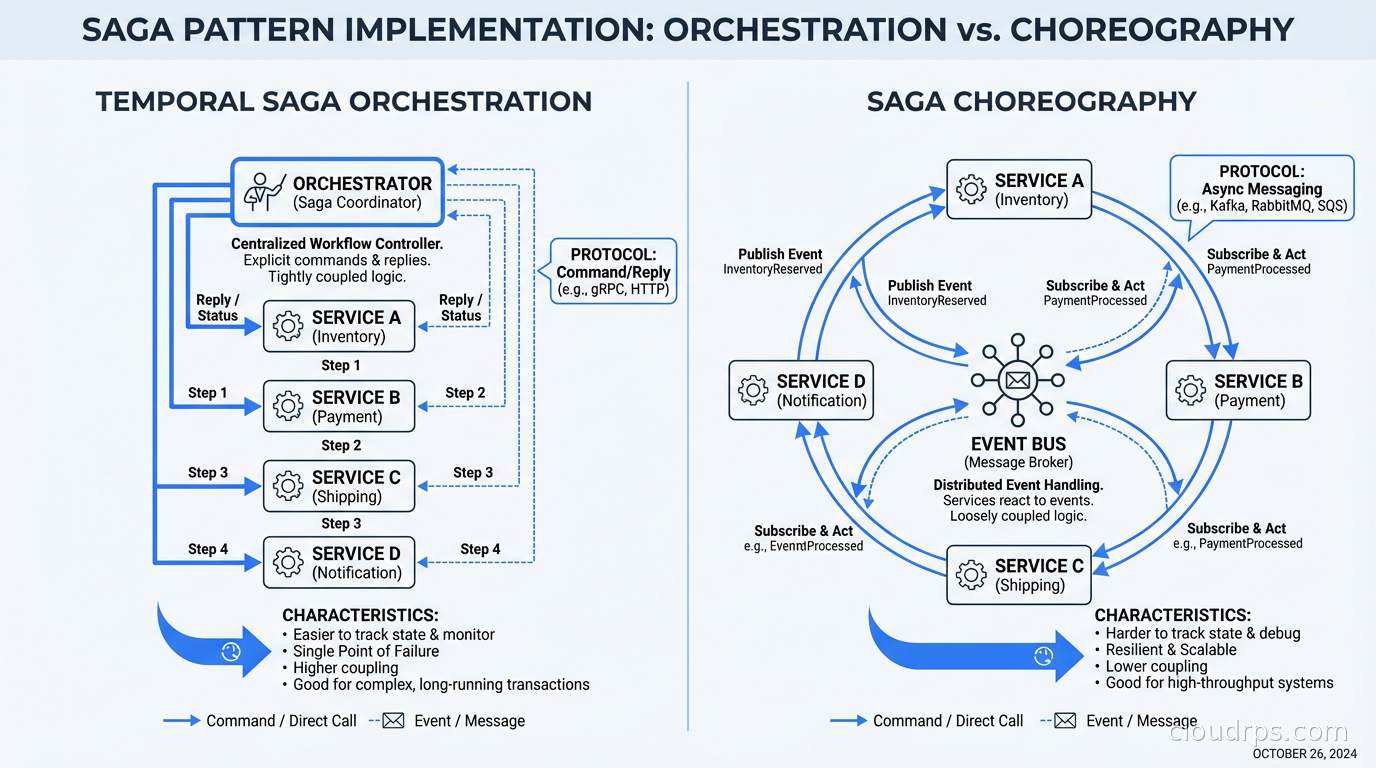
Temporal vs. Traditional Saga Choreography
The saga pattern (which I’ve seen called “distributed transactions with failure handling” by people who don’t know the name) is the common alternative to a workflow engine. In a saga, each service publishes events when it completes its step, and other services subscribe and react. Compensation logic rolls back changes if a step fails downstream.
Sagas work. Netflix and Uber have shipped production systems with choreography-based sagas. But they have real costs:
State is distributed across services and event logs. To understand the current state of an order, you have to reconstruct it from events across multiple services. Debugging a stuck saga means tracing events across services, which requires excellent distributed tracing infrastructure.
Compensation logic is complex and often wrong. What does “undo payment” mean if the payment gateway doesn’t support refunds below a minimum amount? What does “undo inventory reserve” mean if the inventory system was down for two hours and you’re not sure if the reserve was recorded? Compensation logic handles edge cases that are difficult to anticipate and even harder to test.
Business logic is distributed across services. The “business process” of order fulfillment is implemented as event handlers scattered across five services. Understanding the full flow requires reading five codebases. Changing the process requires coordinating changes across five teams.
With Temporal, the business process lives in one place: the workflow definition. Business logic changes happen in the workflow code. Compensation is handled with try/catch and explicit compensation activities. State is queryable through Temporal’s API. Debugging means looking at the workflow’s event history in the Temporal UI, which shows every step, every activity result, every failure, and every retry.
This connects to the broader fault tolerance conversation. Temporal doesn’t make services fault tolerant; it makes the orchestration of those services fault tolerant. Your services still need to be idempotent (activities can be retried, so they must handle duplicate calls correctly), but you get the orchestration layer’s fault tolerance for free.
Use Cases Where Temporal Shines
Long-running business processes. Anything that takes more than a few seconds and involves multiple steps is a candidate. Order management, loan origination, insurance claim processing, user onboarding workflows. The “wait for human input” capability is particularly powerful: a Temporal workflow can wait for a human approval for days with no resources consumed during the wait, then automatically continue when the signal arrives.
Data pipeline orchestration. Processing a batch of documents where each goes through OCR, classification, enrichment, and storage. Temporal handles the fan-out, tracks per-document state, handles failures for individual items without failing the whole batch, and gives you visibility into progress. This is an alternative to Airflow or Prefect for more complex, event-driven pipelines.
Multi-service API integrations. Calling external APIs with poor reliability, rate limits, and partial failure modes. Wrap each API call in an activity with appropriate retry policies and timeouts. The workflow handles the orchestration, retries transient failures automatically, and surfaces permanent failures clearly.
Database migrations and data backfills. Long-running operations that need to process millions of records, handle failures gracefully, and be pausable and resumable. Temporal’s workflow history and visibility make these operations observable in ways that a raw script running on a server is not.
Agentic AI workflows. Multi-step AI agent processes that call tools, wait for results, make decisions, and may run for extended periods. Temporal is well-suited to the agentic AI production use case where you need reliability and observability on top of non-deterministic AI logic.
Operational Considerations
Temporal introduces operational complexity that you need to plan for.
The Temporal server needs a reliable database. PostgreSQL is the most common choice for production, though Cassandra is used at large scale. The database stores all workflow event histories, so its durability is critical. Back it up, monitor it, and size it appropriately for your workflow retention period.
Event history size limits matter. Each workflow accumulates an event history. Very long-running workflows with many steps can grow large event histories that slow down replay. The recommended pattern for very long workflows is to use “continue-as-new”: create a new workflow run that carries forward the current state, resetting the event history. Plan for this if you have workflows that run indefinitely.
Determinism constraints require discipline. Workflow code cannot use system time directly, cannot use random numbers, cannot do direct I/O. These constraints catch developers early and can feel restrictive. The SDK provides workflow-safe versions of these operations. The constraint is real but acceptable once you internalize it.
Versioning workflows is non-trivial. When you change workflow code and have existing running workflows that need to continue with the old behavior, you need to handle versioning explicitly using Temporal’s get_version API. This is workflow-engine-specific knowledge that your team needs to learn. The alternative (migrating all existing workflows before deploying new code) is worse at scale.
Worker sizing requires understanding your workload. Activity workers scale horizontally. Workflow workers should be sized based on the number of concurrent workflow executions. Getting this wrong leads to task queue buildup and latency. Monitor your task queue depths and worker slot utilization.
The monitoring and logging integration is important here: Temporal exports Prometheus metrics for all the key operational signals. Wire these into your existing observability stack and set up alerts on task queue backlog, workflow error rates, and worker slot saturation.
Temporal Cloud vs. Self-Hosted
Temporal Cloud is Temporal’s fully-managed offering. You connect your workers to their cloud infrastructure, and they handle the server operations, persistence, high availability, and upgrades. Pricing is based on execution time and action counts.
Self-hosted Temporal gives you control but adds operational burden. Running a reliable Temporal cluster means managing the multi-service architecture, the persistence layer, upgrades, and monitoring. For teams already operating Kubernetes clusters with solid platform engineering practices, this is manageable. For teams without that foundation, Temporal Cloud is almost always the right choice.
The cost calculation: Temporal Cloud pricing for moderate workloads is typically $500-5000/month depending on volume. A self-hosted cluster on Kubernetes requires engineering time to set up (1-2 weeks) and ongoing operational attention. For most organizations, Temporal Cloud is cost-effective at moderate volumes.
Getting Started
The fastest path to understanding Temporal is to run it locally and build a simple workflow. The Temporal CLI includes a development server that runs everything in a single process:
# Install Temporal CLI
brew install temporalio/brew/tcld
# Start local development server
temporal server start-dev
# This starts the server, UI (http://localhost:8233), and a default namespace
Write a simple workflow, run it, watch it in the UI, then deliberately kill your worker mid-execution and observe how it recovers. This five-minute exercise will make the value proposition concrete in a way that reading about it doesn’t.
Temporal is not the right tool for simple, stateless request-response services. If your service processes a request and returns a result in under a second, you don’t need a workflow engine. But for the class of problems involving long-running, multi-step, failure-prone processes where state needs to survive infrastructure events, Temporal is one of the most significant quality-of-life improvements available in 2026. The amount of boilerplate, infrastructure code, and debugging time it eliminates is substantial once you’ve used it on a real problem.
The teams I’ve seen adopt Temporal consistently report the same thing: once they have it running, they wish they’d had it years earlier. That’s a strong signal.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.