The first production system I ever designed was a three-tier application. It was 1997, and we were building an internal procurement system for a manufacturing company. Web server in the DMZ, application server in the trusted zone, Oracle database in the back. That architecture served us well for years.
Almost three decades later, I still start every architecture conversation with three-tier. Not because it’s the only pattern (it’s not), but because it’s the foundational mental model that everything else builds on. Microservices, serverless, event-driven architectures: they’re all responses to the limitations of three-tier, and you can’t understand the responses without understanding what they’re responding to.
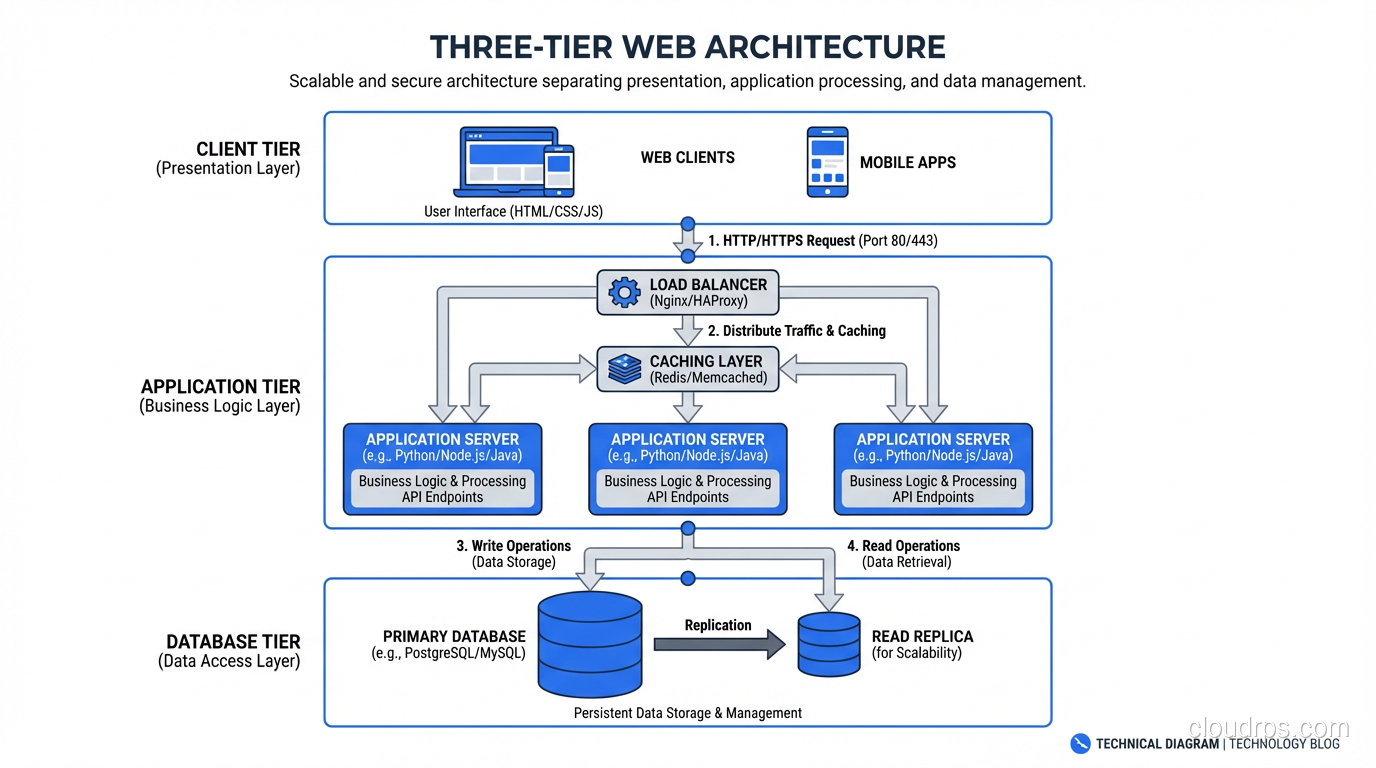
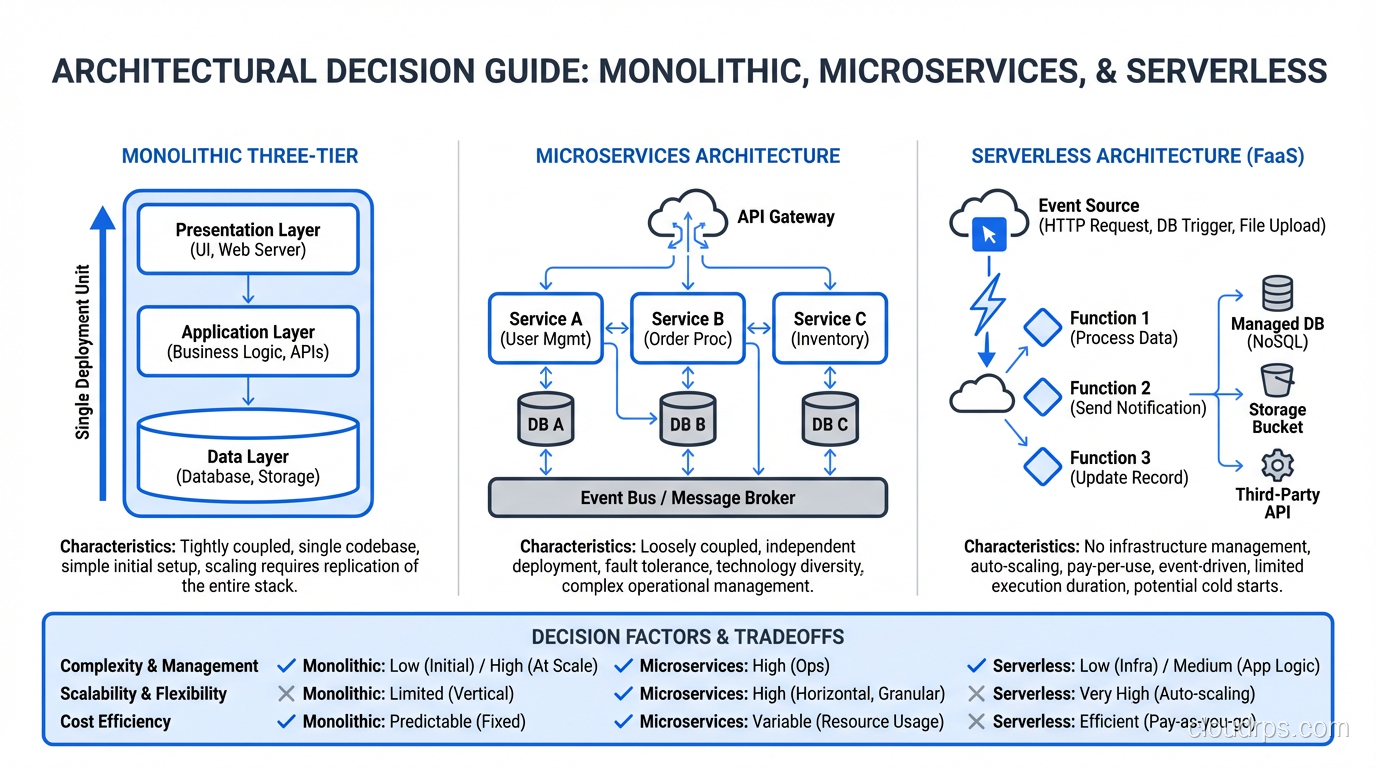
The Three Tiers
Let me be precise about what the three tiers actually are, because I see sloppy definitions all the time.
Tier 1: Presentation (The Client)
This is what the user interacts with. In the traditional model, it was HTML pages rendered by the web server. In the modern model, it’s a JavaScript application running in the browser (React, Vue, Angular) or a mobile app.
The presentation tier’s job is simple: collect input from the user, send it to the application tier, and display the response. It should contain minimal business logic. When I see complex business rules implemented in frontend JavaScript, I know the architecture is heading for trouble. Frontend code runs on devices you don’t control, in browsers you can’t trust.
Tier 2: Application (The Logic)
This is where the business logic lives. User authentication, data validation, workflow processing, calculations, integrations. All of it runs here. The application tier receives requests from the presentation tier, processes them according to business rules, interacts with the data tier, and returns results.
In the traditional model, this was a Java EE application server, a .NET application, or a set of PHP scripts. In the modern model, it might be a Node.js service, a Python Django application, a Go API, or a collection of microservices.
Tier 3: Data (The Storage)
This is where state lives. Databases (relational, document, graph), file systems, caches, message queues: anything that persists or manages state. The data tier receives queries and commands from the application tier and returns data.
The data tier is the most critical tier in any system. You can redeploy your presentation and application tiers from source code. You cannot recreate your data from source code. This asymmetry should drive your architecture decisions more than any other factor.
Why Three Tiers Exists
The three-tier pattern emerged for a specific reason: separation of concerns at deployment boundaries.
Before three-tier, the dominant architecture was client-server (two-tier). A thick client application connected directly to a database. Business logic lived in the client application and in database stored procedures. This worked until you had to update the business logic, which meant redeploying the client to every desktop, or modifying stored procedures that were tangled with data access logic.
Three-tier solved this by extracting business logic into a middle tier that could be updated independently. Change the business rules? Redeploy the application tier. Change the UI? Redeploy the presentation tier. Change the data model? Update the data tier. Each tier could evolve on its own schedule.
This separation also created natural security boundaries. The database isn’t directly accessible from the internet because the application tier mediates all access. The web server in the DMZ only talks to the application tier, never directly to the data tier. In the days before cloud networking, these physical and network boundaries were the primary security architecture.
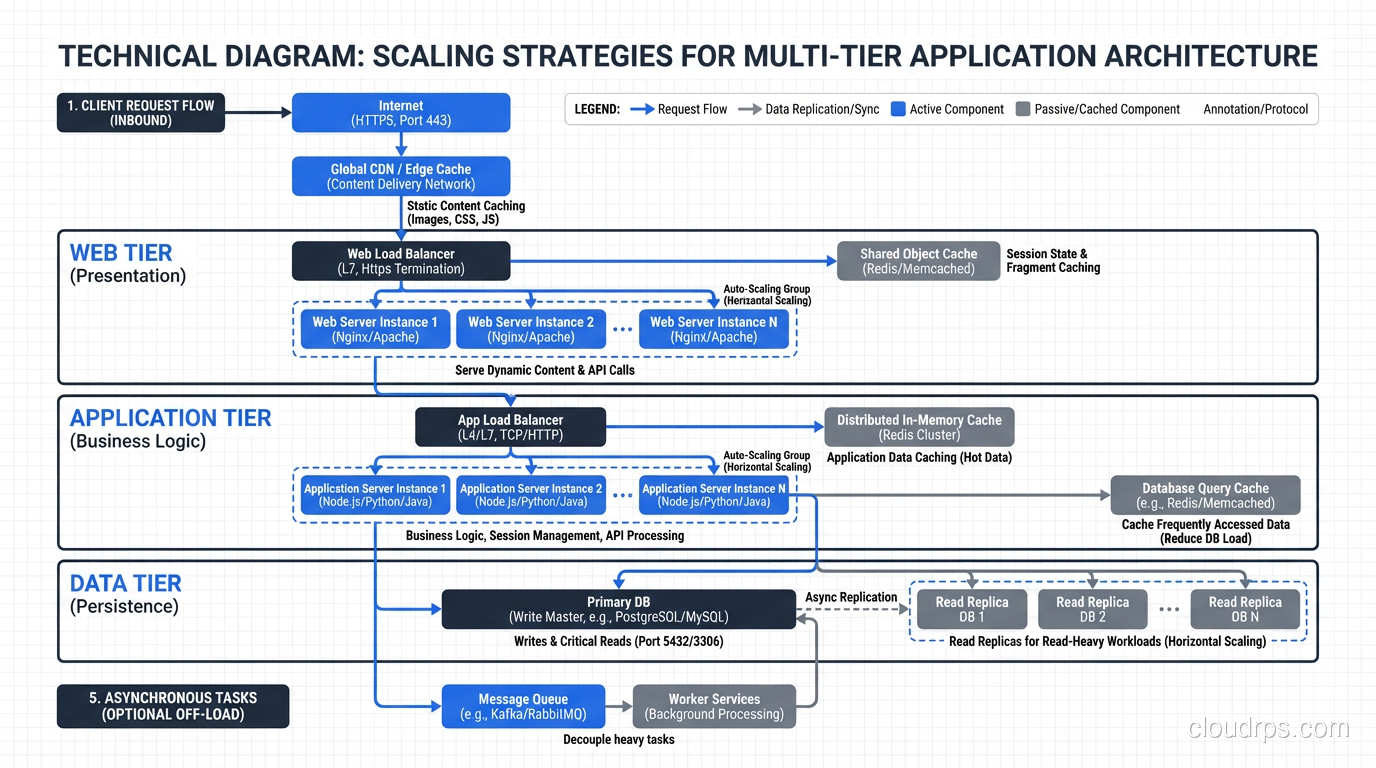
Scaling Each Tier
Here’s where three-tier architecture gets interesting in a cloud context. Each tier has different scaling characteristics, and understanding those differences is critical for building systems that handle real-world load.
Scaling the Presentation Tier
The presentation tier is the easiest to scale because it’s mostly stateless. Static assets (HTML, CSS, JavaScript, images) can be served from a CDN. Dynamic rendering can be distributed across multiple web servers behind a load balancer.
In practice, modern single-page applications have shifted most presentation work to the browser. Your “presentation tier” might just be S3 + CloudFront serving a React bundle. That scales to millions of users with zero additional servers.
Scaling the Application Tier
The application tier scales horizontally by adding more instances behind a load balancer. This works when the tier is stateless, meaning any instance can handle any request without knowing about previous requests.
The stateless constraint is key, and it’s where I see most scaling problems. If your application stores session data in local memory, you can’t scale horizontally without sticky sessions (which defeat the purpose of horizontal scaling) or externalizing session state to Redis or a database.
The pattern I’ve used for the last fifteen years: keep the application tier completely stateless. All session state goes to Redis. All persistent state goes to the database. Any application instance can handle any request. This lets auto-scaling groups add and remove instances freely based on load.
For a deeper dive on scaling strategies, see How to Scale a Web Application.
Scaling the Data Tier
This is where things get hard. The data tier is inherently stateful, and scaling stateful systems is fundamentally more difficult than scaling stateless ones.
Vertical scaling (scaling up): Bigger database server. More CPU, more RAM, faster storage. This is the simplest approach and works until you hit the limit of the largest available instance. I’ve run single PostgreSQL instances handling 50,000 queries per second on a sufficiently large machine. Sometimes the simplest solution is the right one.
Read replicas: For read-heavy workloads, create read replicas and distribute read queries across them. Writes go to the primary, reads go to replicas. This scales reads linearly but doesn’t help with write throughput.
Sharding: Partition data across multiple database instances based on a shard key (usually tenant ID or geographic region). This scales both reads and writes but adds enormous complexity to your application layer. Queries that span shards become expensive. Rebalancing shards is operationally painful.
Caching: Put a cache (Redis, Memcached) in front of the database to absorb read traffic. This is often the highest-leverage scaling change you can make. A well-configured cache with a 95% hit rate means your database handles 20x less traffic.
High Availability in Three-Tier Architecture
Making a three-tier application highly available requires eliminating single points of failure in every tier.
Presentation tier: Multiple web servers behind a load balancer. The load balancer itself must be redundant (which is why managed load balancers like ALB or NLB are so valuable, since AWS handles the load balancer’s availability).
Application tier: Multiple application instances behind a load balancer, ideally spread across availability zones. If one AZ goes down, the instances in the other AZ continue serving traffic.
Data tier: Primary database with synchronous or semi-synchronous replication to a standby in a different AZ. Automated failover when the primary becomes unavailable.
The data tier is always the hardest to make highly available because of the stateful nature. A failed application server just means one less instance handling requests; the load balancer routes around it. A failed database primary means you need to promote a standby, potentially accept a brief write outage, and hope your replication was up to date.
I’ve managed dozens of database failovers. Automated failover with synchronous replication (like Amazon RDS Multi-AZ) has become reliable enough that I trust it for production. But I still test failover regularly. Trust but verify.
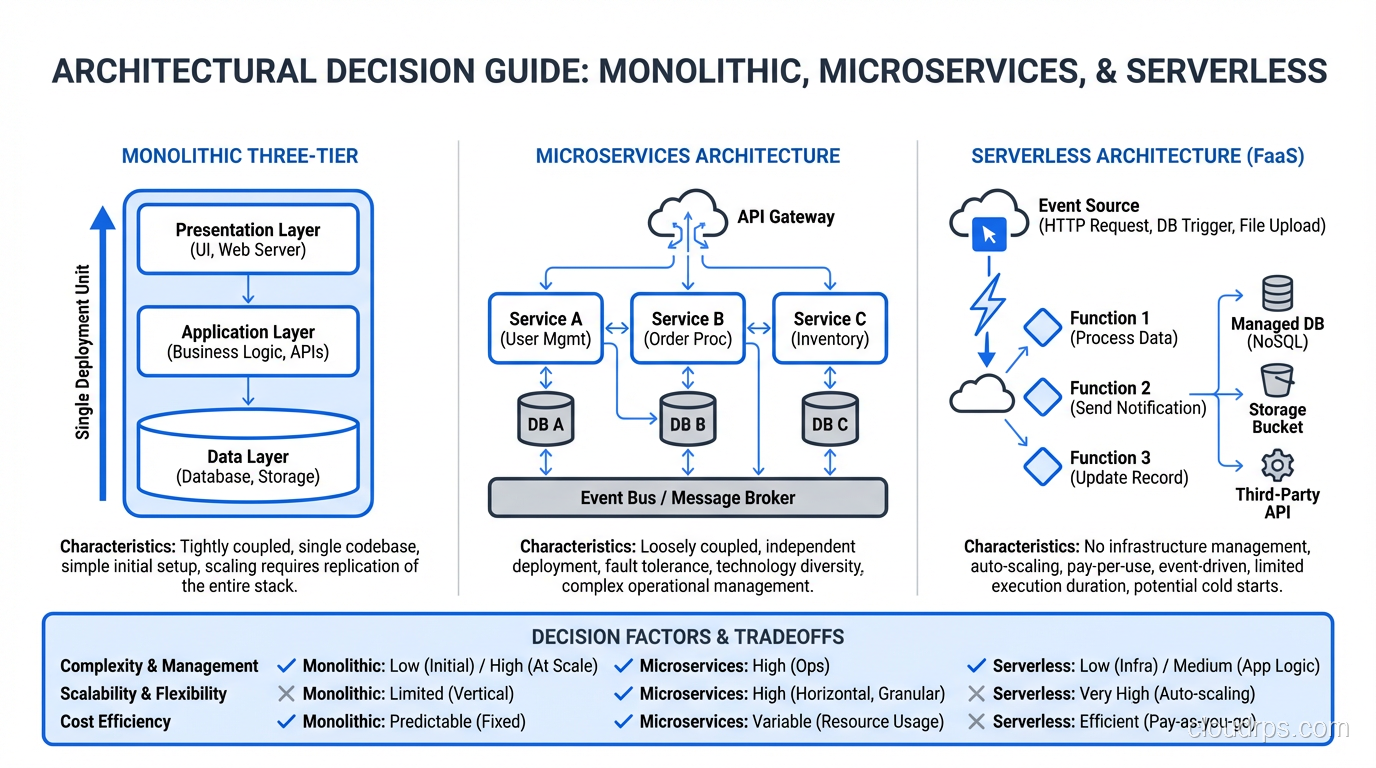
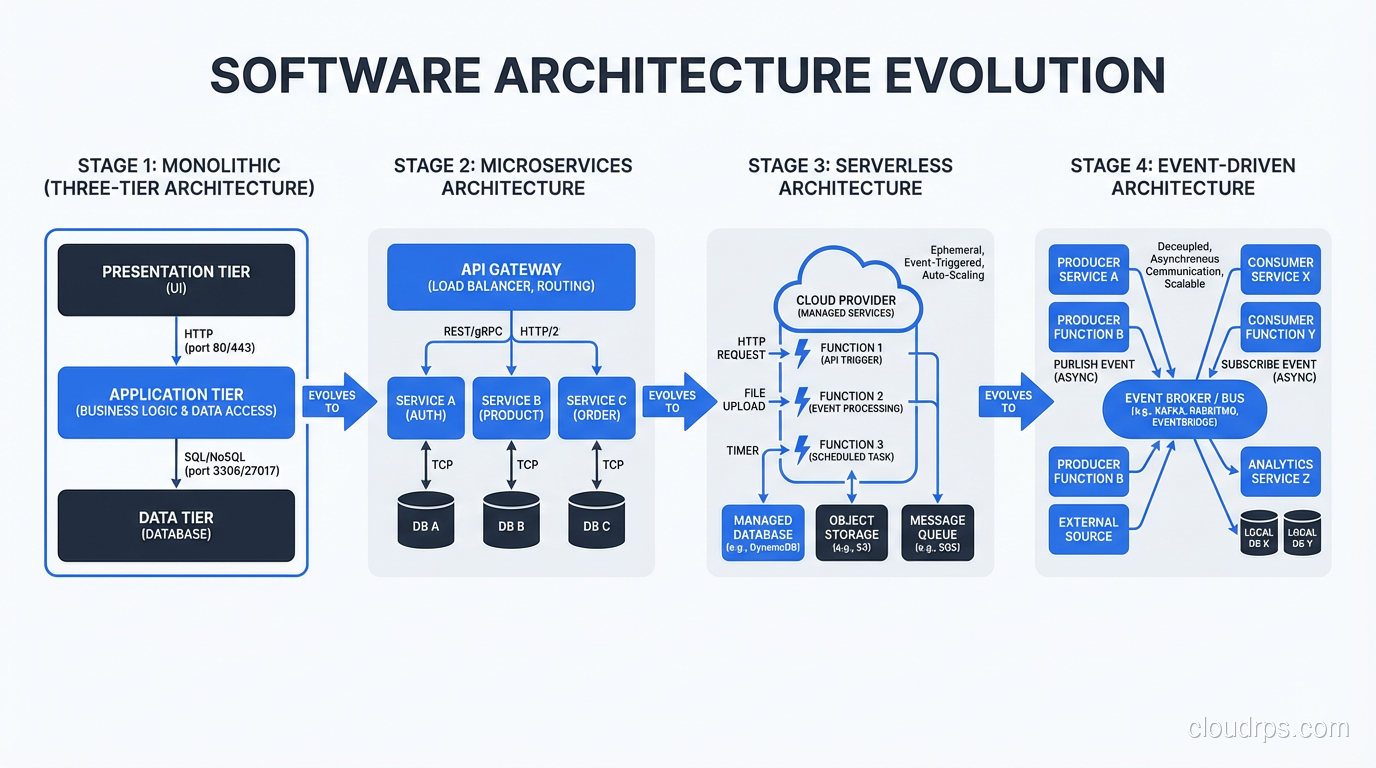
The Modern Variants
Three-tier architecture evolved as systems grew more complex and the limitations became apparent. Understanding the modern variants requires understanding what problems they solve.
Microservices: Three-Tier, Decomposed
Microservices decompose the monolithic application tier into independent services, each responsible for a specific business capability. Instead of one large application server handling orders, inventory, and payments, you have an Order Service, an Inventory Service, and a Payment Service.
Each microservice often has its own mini three-tier structure: an API layer (presentation), business logic (application), and data store (data). It’s three-tier all the way down.
The benefit is independent scalability and deployment. The Order Service can be scaled separately from the Inventory Service. The Payment Service can be deployed without touching the other services.
The cost is distributed systems complexity. Network calls between services add latency. Distributed transactions are hard. Data consistency across service boundaries requires careful design. I’ve seen plenty of teams adopt microservices and end up with a distributed monolith: all the complexity of microservices with none of the benefits.
Serverless: Three-Tier, Unbundled
Serverless architectures often follow the same three-tier logic but use managed services for each tier. API Gateway for presentation routing, Lambda functions for application logic, DynamoDB for data storage. The tiers exist, but you don’t manage the infrastructure for any of them.
Event-Driven: Three-Tier, Asynchronous
Event-driven architectures add asynchronous communication between tiers. Instead of the application tier synchronously calling the data tier, it publishes events to a message broker, and various consumers process those events asynchronously. This decouples the tiers further and enables better resilience (if the data tier is temporarily unavailable, events queue up rather than causing failures).
Common Mistakes I See
After decades of reviewing three-tier architectures, here are the mistakes that keep showing up:
Putting Business Logic in the Database
Stored procedures, triggers, complex SQL functions. I fought this battle in the early 2000s, and I’m still fighting it. Business logic in the database is hard to test, hard to version control, hard to deploy, and creates tight coupling between your application and your database technology.
I’ve migrated enough Oracle-dependent applications to know the pain of business logic buried in PL/SQL. Keep your database doing what it does best: storing and retrieving data efficiently.
Treating the Application Tier as Stateful
“We store the shopping cart in the application server’s memory.” I’ve heard this sentence dozens of times. It works until you need a second application server, and then you’re in trouble. Make the application tier stateless from day one. You’ll thank yourself when you need to scale.
Ignoring the Presentation Tier’s Evolution
The presentation tier has shifted dramatically from server-rendered pages to client-side applications. This changes the traffic pattern. Instead of the web server rendering HTML, it serves static files once and then the client makes API calls. Your application tier is now an API server, and your load balancing strategy needs to account for the different traffic pattern (many small API calls vs. fewer large page renders).
Skipping the Cache Layer
If your application goes directly from the application tier to the database for every request, you’re leaving performance on the table. A caching layer between the application and data tiers, even a simple one, typically reduces database load by 80-90% for read-heavy workloads.
When Three-Tier Is Still the Right Choice
Despite the industry’s love affair with microservices and serverless, three-tier monolithic architecture is still the right choice for many applications.
If your team is small (under 10 engineers), a monolith is almost always the right starting point. Microservices add operational overhead that small teams can’t absorb. Start with a well-structured monolith, and decompose into services only when you have a clear scaling or organizational reason to do so.
If your application’s complexity is moderate and well-understood, three-tier gives you a clear, well-known architecture with decades of tooling, best practices, and operational knowledge. There’s enormous value in boring technology.
If your scaling needs are predictable, horizontal scaling of a monolithic application tier behind a load balancer handles more traffic than most applications will ever see.
Three-tier isn’t outdated. It’s proven. And proven matters when you’re responsible for systems that need to work at 3 AM on a Saturday.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.