There is a moment in every data platform architect’s life when the business asks a question that breaks your existing stack. For me, it happened in 2017, running a data platform at a mid-sized logistics company. The CFO wanted to join three months of transaction data sitting in S3 Parquet files against real-time inventory from PostgreSQL and a product catalog in Elasticsearch. All in a single query. Under thirty seconds.
We had Hadoop. We had Spark. Neither answer was acceptable. Spark could do it, technically, but the job scheduling overhead meant forty-five minutes minimum. And nobody was writing a forty-five-minute report in an ad-hoc tool. We ended up discovering Presto, deployed a cluster in a week, and had the CFO’s query running in twenty-two seconds by Friday.
That was Presto. Today, in 2026, its successor is Trino, and it has become one of the core building blocks of the modern data lakehouse. If you are building analytics infrastructure at any serious scale, you need to understand what Trino is, how its architecture works under the hood, where it fits relative to Spark and cloud warehouses, and how to run it without learning the painful lessons the hard way.
What Trino Is and Where It Came From
Trino is a distributed SQL query engine. It was originally created at Facebook in 2012 under the name Presto, designed specifically to replace Hive for interactive queries against HDFS. Hive translated SQL into MapReduce jobs. A simple aggregation could take fifteen minutes. Presto took the same query to seconds by holding intermediate results in memory instead of writing to disk between stages.
Facebook open-sourced Presto in 2013. Teams at Dropbox, Netflix, Twitter, LinkedIn, and Uber all started running it. In 2019, the original Presto creators (Martin Traverso, Dain Sundstrom, David Phillips, Eric Hwang) left Facebook and founded the Presto Software Foundation, renaming the project PrestoSQL. In 2021 it became Trino to definitively separate from the Facebook fork, which is now maintained by the Presto Foundation and still used at Meta.
The practical implication: when people say “Presto” today they might mean either. Trino is the one with faster development velocity and the active community of the original creators. Starburst offers a commercial distribution with enterprise support. Most new installations in 2026 use Trino.
The Architecture That Makes It Fast
Understanding why Trino can run interactive queries against data that would take Spark jobs many minutes comes down to its execution model.
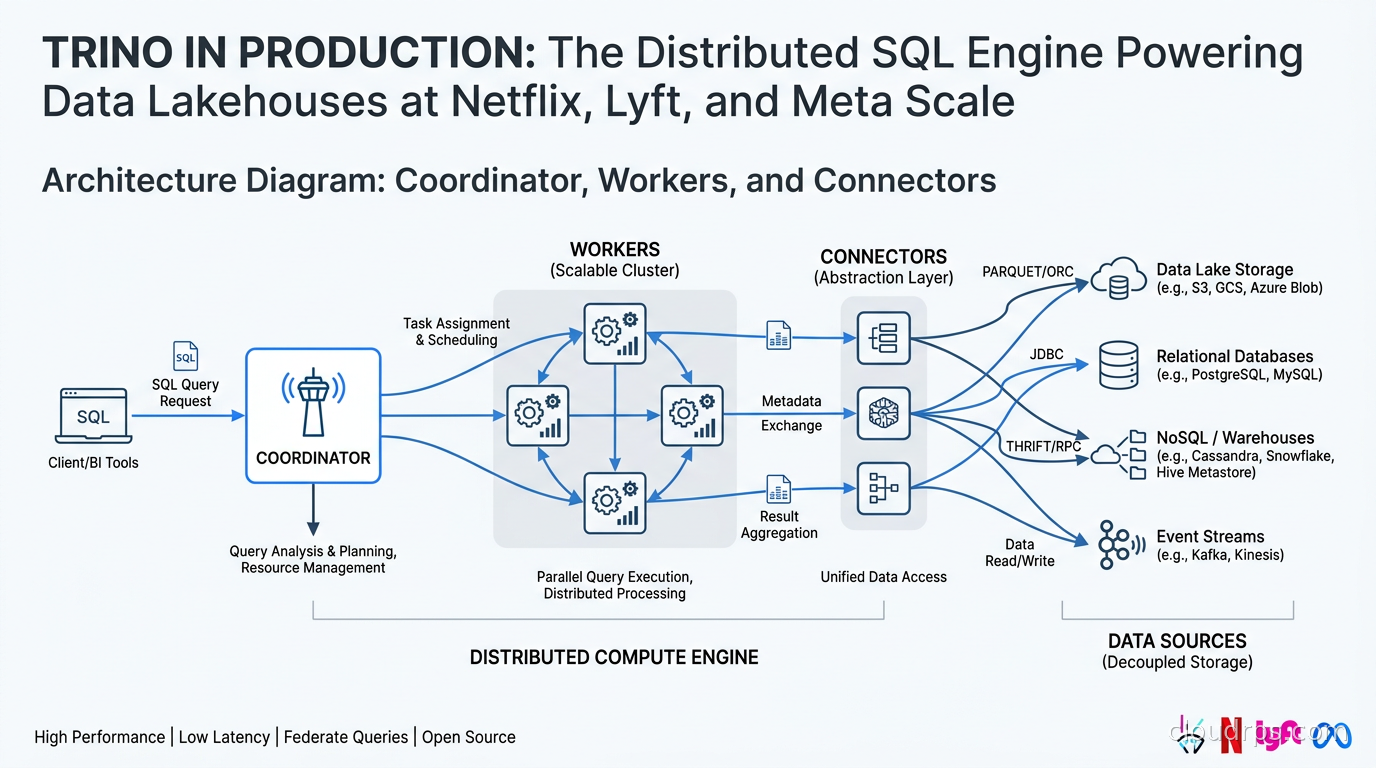
Trino is built on a coordinator-worker architecture with in-memory pipelined execution.
The Coordinator is the brain. When a query arrives, the coordinator parses the SQL, generates an execution plan, splits that plan into stages, and distributes those stages across workers. The coordinator itself does no data processing. It runs the query planner and cost-based optimizer (CBO), manages worker assignments, and tracks query progress. In production you typically run the coordinator on a dedicated instance, separate from the worker fleet.
Workers are where computation happens. Each worker pulls data from the source systems via connectors, processes splits in parallel, and passes intermediate results to other workers via a shuffle mechanism. Results flow through a pipeline of operators: scan, filter, project, aggregate, join, sort. Crucially, this pipeline executes in memory, using a streaming model where data flows through operators without checkpointing to disk (unless spill-to-disk is enabled for memory-heavy operations).
Connectors are the abstraction that makes Trino genuinely powerful. Every data source is accessed through a connector that implements a standard interface: metadata API (what tables and columns exist), split generation (how to partition the work), and data reading (how to fetch and decode the records). Trino ships with connectors for Hive/HDFS, Apache Iceberg, Delta Lake, Apache Hudi, PostgreSQL, MySQL, Cassandra, Elasticsearch, Kafka, and many more. A single query can join across all of them.
Catalogs expose connectors to SQL. You configure a catalog named iceberg_prod backed by the Iceberg connector pointing at your S3 data, another named postgresql pointing at your operational database, and a third named kafka pointing at your event streams. Users then write: SELECT ... FROM iceberg_prod.sales.orders JOIN postgresql.inventory.products ON ... and Trino federates the query across systems transparently.
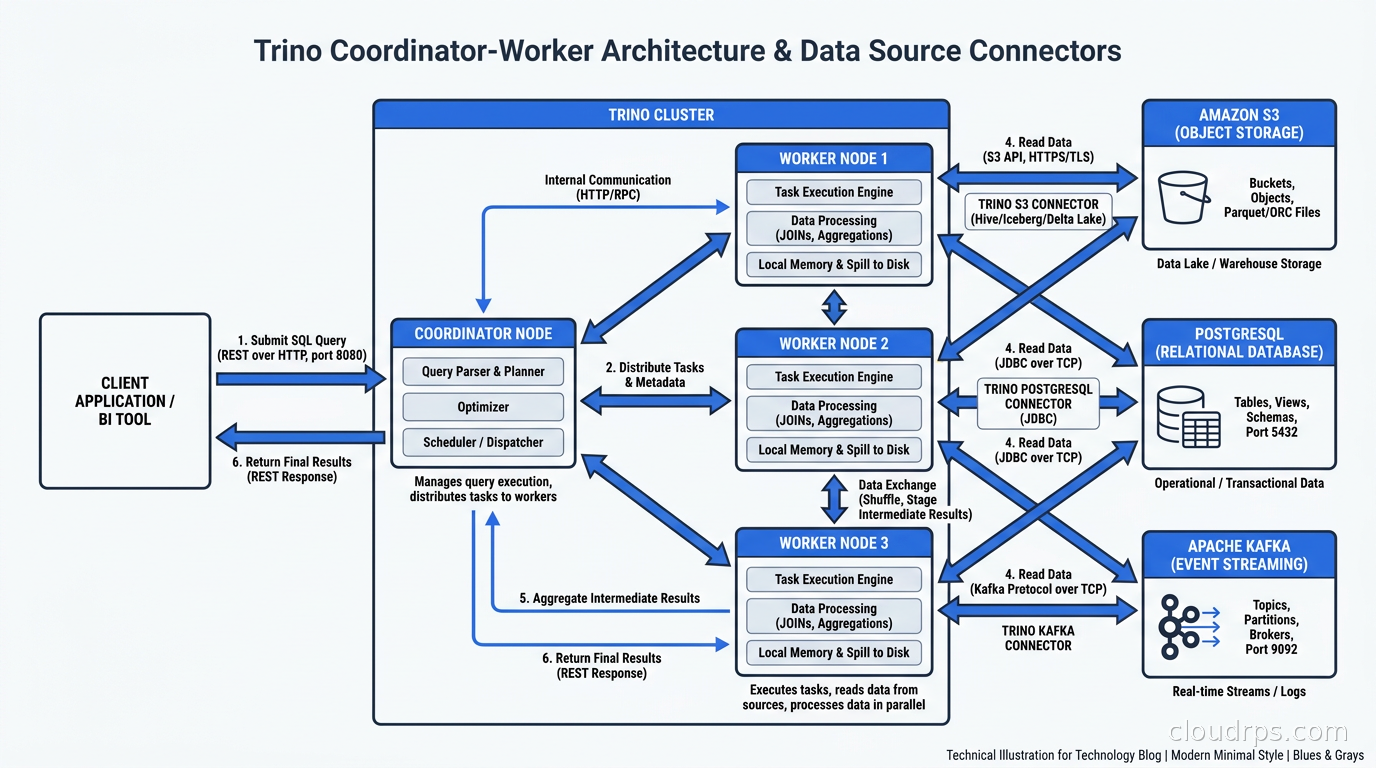
The cost-based optimizer deserves special mention. Trino can collect table statistics (row counts, column cardinality, data size) from data sources and use them to reorder joins, choose aggregation strategies, and select broadcast vs. partitioned hash joins. For queries touching large tables, the CBO regularly delivers two to five times better performance than the rule-based planner. You get this automatically when you run ANALYZE on your Iceberg tables or configure automatic statistics collection in your metastore.
Trino vs Spark: The Honest Comparison
This comes up constantly. Both process data at scale. Both run on clusters. Both can query S3 Parquet files via Iceberg. So when do you use which?
The core difference is execution model. Spark is a general-purpose batch computation engine with a DAG execution model that writes shuffle data to disk. It is built for reliability on large jobs that take minutes to hours. Trino is an interactive query engine that keeps everything in memory and optimizes for latency on queries that should take seconds to minutes.
Practical breakdown:
Query latency under a minute: Trino almost always wins. The memory-pipelined model eliminates disk I/O between stages. Spark’s overhead for scheduling executors, writing shuffle files, and reading them back adds latency that hurts on small-to-medium queries.
Multi-hour batch ETL jobs: Spark wins. Spark’s disk-based shuffle is a feature here, not a bug. It allows jobs to process more data than fits in cluster memory, recover from node failures without restarting the whole job, and run stably for hours. Trino can do ETL with
CREATE TABLE AS SELECTandINSERT INTO SELECT, but if a worker fails mid-query, the whole query fails and must restart. For a three-hour job, that is not acceptable.Federated queries across systems: Trino wins decisively. Spark can read from multiple sources but cannot natively federate a query that JOINs S3 Parquet against PostgreSQL in a single execution plan. You would need to read both into DataFrames, which loads all the data into memory. Trino pushes predicates down into each connector and lets the data source do filtering.
Machine learning and complex transformations: Spark wins. Spark has MLlib, DataFrame APIs in Python/Scala/R, built-in streaming via Spark Structured Streaming, and integrates with ML frameworks. Trino is SQL-only. There is no Trino equivalent of a Spark UDF that calls a Python model.
Streaming data: For queries against Apache Kafka or real-time data, Trino has a Kafka connector that can run SQL against topics, but it is a batch scan of current offsets. For continuous stream processing with stateful aggregations, use Flink or Spark Structured Streaming. Trino is not a streaming engine.
The best data platforms I have seen in twenty years run both. They use Apache Spark for ETL pipelines, model training, and heavy batch work, and Trino for the query engine that BI tools and data analysts hit for interactive exploration and reporting.
The Modern Lakehouse Stack with Trino
Where Trino really shines in 2026 is as the compute layer of an open lakehouse. The typical stack looks like this:
Object storage (S3, GCS, Azure Blob) holds data as Parquet or ORC files. Apache Iceberg provides the table format layer: a metadata catalog that tracks which files belong to which table, what their schemas are, what partitions exist, and what snapshots have been committed. The Hive Metastore or AWS Glue acts as the catalog service that Trino queries to discover tables. Trino then reads the Iceberg metadata, plans the query, and dispatches workers to fetch and process the Parquet files in parallel from S3.
This stack gives you something you cannot get with a managed warehouse like Redshift or BigQuery: full data ownership and open formats. Your data lives in your S3 bucket in standard Parquet files. You can query those same files with Spark, DuckDB, Athena, or any other tool that supports Iceberg. You are not locked into a proprietary storage format.
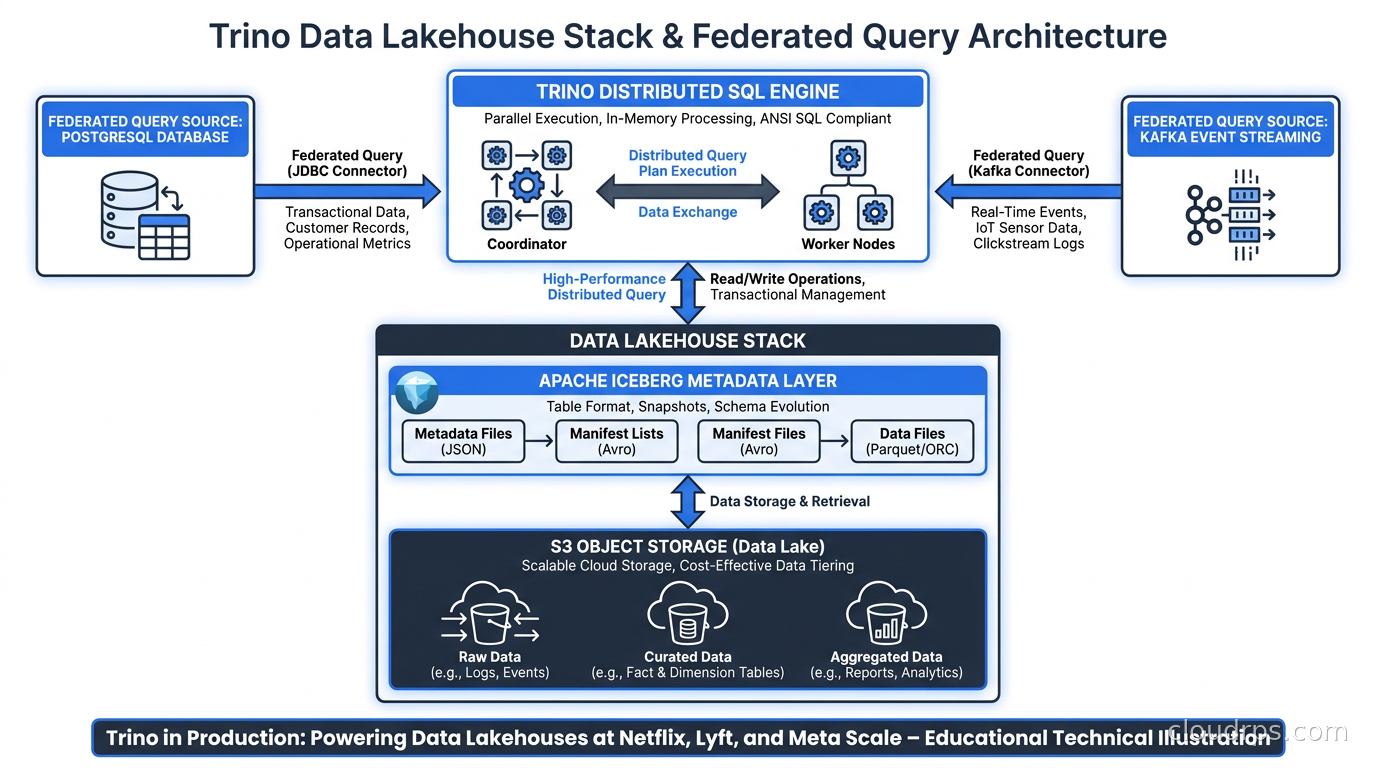
The federated query capability is what separates Trino from running Athena or Spark on Iceberg. I have seen teams use Trino to build a unified query layer where:
- Historical transaction data lives in Iceberg tables on S3
- Operational data lives in PostgreSQL (via the PostgreSQL connector)
- Real-time events come from Kafka topics (via the Kafka connector)
- Reference data lives in a MySQL database
- Third-party data sits in a separate Iceberg catalog
Analysts write a single SQL query joining all of these, and Trino figures out how to execute it. The federated model also works well when you have change data capture pipelines streaming operational database changes into Iceberg. Analysts can query the Iceberg tables for near-real-time data without touching the operational database.
Running Trino in Production: The Practical Bits
Trino is not a managed service by default (though Starburst Galaxy and Amazon Athena v3 offer managed options). If you are self-hosting, here is what I have learned from running it in production.
Cluster sizing is the first decision. Trino is memory-hungry. Each worker needs enough heap to hold the shuffle data and intermediate results for its in-flight queries. A cluster that runs ten concurrent queries each joining a 100GB table with a 10GB dimension needs several terabytes of aggregate cluster memory. Start by sizing workers at 30-50% of expected peak data volume per query, multiply by concurrent query headroom, and add 40% for overhead.
For the coordinator, memory is less critical (it does not process data), but CPU matters for query planning on complex queries. A coordinator with 8-16 vCPUs and 32-64GB memory handles most workloads.
Deployment patterns have converged on two approaches. The traditional approach is an always-on cluster with EC2 instances or VMs, auto-scaling the worker fleet based on query queue depth. The newer approach runs Trino on Kubernetes with the Trino Helm chart, scaling workers via HPA keyed on a custom metric from the Trino JMX exporter. I prefer the Kubernetes approach for its deployment consistency and easier version upgrades, though you need solid persistent volume support or ephemeral storage with spill-to-disk tuned carefully.
Memory configuration is where most production teams get burned. Trino has a layered memory management system. The key parameters: query.max-memory caps the maximum memory per query across the cluster, query.max-memory-per-node caps per worker, and memory.heap-headroom-per-node reserves memory for the JVM itself. Set heap-headroom too low and the JVM garbage collector starts fighting Trino for memory under load, causing cascading query failures.
Enable spill-to-disk for memory-intensive operations (hash joins, aggregations) in production. Without it, a single large query can OOM the worker. With spill enabled, Trino writes sorted intermediate results to local NVMe, which is slower but prevents crashes.
Query resource groups are non-negotiable in a shared cluster. Without resource groups, a single analyst running SELECT * FROM events with no LIMIT can exhaust cluster memory and kill everyone else’s queries. Resource groups let you define per-user and per-group memory limits, concurrency limits, and queuing behavior. I configure groups for: interactive queries (low memory limit, high concurrency, no queuing), ETL jobs (high memory limit, low concurrency, queue depth of 5), and an admin group (unlimited, for debugging).
Caching at the coordinator and worker level dramatically improves performance on repeated queries. Trino supports connector-level metadata caching (schema and partition cache) to avoid hitting the Hive Metastore or Glue on every query. For data caching (caching actual file contents on local SSD), Alluxio is the common solution. With Alluxio in front of S3, queries against frequently accessed tables run two to five times faster because they hit local NVMe instead of S3 network I/O.
Performance Tuning That Actually Matters
After years of running Trino clusters, here are the tuning knobs that move the needle:
Table statistics. Run ANALYZE TABLE on your Iceberg tables regularly. The cost-based optimizer without statistics falls back to heuristics. With statistics, it makes dramatically better join ordering decisions. I have seen queries go from two minutes to fifteen seconds purely from the CBO choosing a better join order after ANALYZE.
Predicate pushdown. Ensure your WHERE clauses include the partition columns of your Iceberg tables. Trino’s Iceberg connector pushes predicates to the metadata layer, pruning partitions before any file scanning happens. If you partition by event_date and your query filters on event_date, Trino skips all partitions outside the filter range. I have seen 99% partition pruning on a two-year event table when queries filter to a single day.
Join distribution type. For joins where one side is small (under a few hundred MB), annotate with /*+ broadcast */ to force a broadcast hash join. Instead of shuffling both tables by join key across the network, Trino sends the small table to every worker, avoiding the expensive shuffle. For large-to-large joins, stick with the default partitioned hash join.
Connector-specific tuning. For the Iceberg connector, tune hive.max-split-size to control file granularity. Smaller splits mean more parallelism but more overhead. For S3, tune hive.s3.max-connections to control the connection pool to S3. Under high concurrency, the default connection limit throttles you.
ORC vs. Parquet. Trino reads both well, but ORC with dictionary encoding often outperforms Parquet for high-cardinality string columns because ORC’s vectorized reader handles dictionary decoding more efficiently. For numeric-heavy workloads, Parquet’s columnar encoding tends to be slightly better. In practice, the difference is smaller than the columnar format itself: both are dramatically better than row-oriented formats.
Trino vs. the Managed Alternatives
If you are evaluating Trino against managed services, the honest comparison:
Cloud data warehouses like Snowflake, BigQuery, and Redshift Serverless offer hands-off operations, automatic scaling, and no cluster management. They are the right choice when operational simplicity outweighs cost and data portability. The downside: your data is in their proprietary format. Exporting from Snowflake at petabyte scale costs real money and time.
Amazon Athena is managed Trino under the hood (Athena v3 is built on Trino). It is the easiest path to ad-hoc SQL on S3, with no cluster to manage and per-query pricing. The tradeoff: you cannot tune the executor, cannot use resource groups, cannot do federated queries to systems outside AWS, and query latency is higher than a tuned dedicated Trino cluster because of the serverless cold-start overhead.
Starburst Galaxy is managed Trino from the original creators. If you want the Trino feature set without running the cluster yourself, Galaxy is the best answer. It adds enterprise features: data products, role-based access control, data masking, audit logging, and a built-in data catalog. I have seen teams standardize on Galaxy when they want lakehouse federation without the operational burden.
Self-hosted Trino makes sense when you have the engineering capacity to run it, need total control over performance tuning, want to integrate with custom data sources via custom connectors, or need to run in an airgapped environment.
Security and Governance in Trino
Production Trino needs authentication and authorization from day one. Trino supports several authentication mechanisms: password-based (file, LDAP, database), certificate-based, Kerberos, JWT, and OAuth 2.0. In cloud environments, I integrate with the organization’s identity provider via OAuth 2.0. Users authenticate with their corporate SSO and Trino validates the JWT.
Authorization comes through two complementary mechanisms. Native Trino access control lets you grant catalog, schema, and table permissions per user or group. For more sophisticated access control with column-level security and row-level filtering, Apache Ranger (via Starburst’s Trino Ranger integration) or OPA-based authorization is the production standard.
For data governance, Trino integrates with Apache Atlas and other metadata catalogs via the Iceberg table format’s built-in lineage tracking. When you run INSERT INTO ... SELECT FROM, Iceberg tracks what data was written from what source. This lineage flows through dbt transformations to your BI layer, giving you end-to-end column lineage without any additional instrumentation.
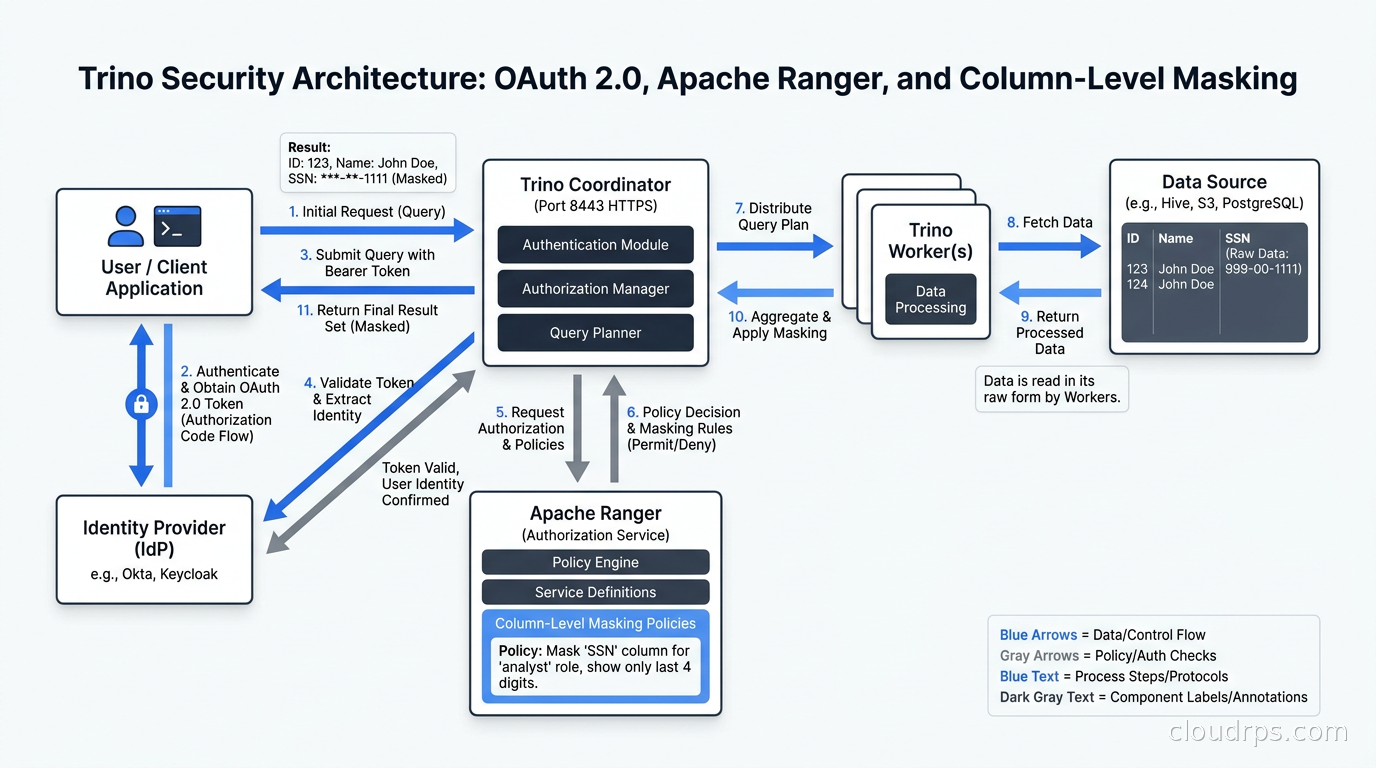
Data masking deserves attention if you have PII in your data lake. Trino’s native policy system supports column masking, but it is limited. Starburst Galaxy and the Ranger integration support dynamic data masking policies that can hash, truncate, or null-mask specific columns based on user group membership. I have implemented column-level masking where analysts see user_email LIKE 'a***@gmail.com' while data engineers see the actual email address, all transparently via Ranger policies.
Orchestration and the dbt Integration
Most Trino installations in 2026 use Airflow, Dagster, or Prefect for pipeline orchestration. The pattern: Spark jobs run heavy ETL and land data into Iceberg tables, and Trino runs transformation queries on those tables to produce analytics-ready datasets. dbt is the tool that manages those Trino-based SQL transformations.
The dbt-trino adapter is mature and production-ready. You configure a dbt profile pointing at your Trino endpoint, write models as .sql files, and dbt handles incremental logic, testing, and documentation. dbt’s incremental materialization maps to Trino’s INSERT INTO ... SELECT ... WHERE with partition filters, giving you efficient incremental loads on Iceberg tables without full rewrites.
The [data contracts](/blog/data-contracts-data-quality-ownership/) pattern pairs naturally with Trino and dbt. Teams define contracts on their Iceberg tables (schema, freshness, row count SLAs), and dbt tests validate those contracts on every pipeline run. When an upstream team changes a column type that breaks your Trino query, the dbt test catches it before analysts see broken dashboards.
When Trino Is Not the Answer
After championing Trino for most of this article, I should be honest about where it falls short.
Trino is not a streaming engine. If you need continuous queries that update as new events arrive, you want Flink or Spark Structured Streaming. Trino’s Kafka connector runs batch queries against current topic offsets; it does not maintain continuous state.
Trino is not a low-latency OLTP database. Query startup overhead is non-trivial, even for simple queries. A query that hits Trino, talks to the Hive Metastore, enumerates Iceberg metadata, and fetches Parquet files from S3 will not complete in single-digit milliseconds. For sub-second latency on pre-aggregated data, look at ClickHouse or Redis-backed serving layers.
Trino is not a great fit for very small teams. Running a Trino cluster requires operational knowledge: JVM tuning, memory configuration, connector versioning, resource group management. If you have two data engineers and need SQL on S3, start with Athena or DuckDB locally. Graduate to Trino when the limitations of managed options become real problems.
Trino also does not replace a data pipeline orchestration tool. It is a query engine, not a scheduler. You still need Airflow or Dagster to trigger Trino queries at the right time, handle retries on failure, and manage dependencies between jobs.
The Decision Framework
Here is how I evaluate whether a team should run Trino:
You should run Trino if: you have data in S3 or a data lake and need interactive SQL under thirty seconds; you need to query across multiple data systems in a single query; you want to own your data in open formats (Iceberg, Parquet) and need high-performance SQL on top; or you have outgrown Athena’s query latency and need tunable performance.
You should look elsewhere if: you need sub-second latency on pre-aggregated data (use ClickHouse or a time-series database); you are processing data that exceeds cluster memory and needs reliable multi-hour batch jobs (use Spark); or you need continuous stream processing with stateful aggregations (use Flink); or your team of two engineers does not have capacity to run a distributed system (use Athena or a managed warehouse).
The war story from 2017 that opened this article ended well. The Presto cluster we deployed became the foundation of our analytics platform. When I left that company two years later, it was running five hundred queries a day across S3, PostgreSQL, and Elasticsearch with a cluster the team had scaled from eight workers to forty. The CFO still ran his report every Friday morning, in under thirty seconds.
Trino has gotten considerably better since then. The cost-based optimizer, fault-tolerant execution mode, native Iceberg support, and Kubernetes deployment patterns have made it more capable and easier to operate than the Presto I was fighting with in 2017. For teams building serious data platforms on open lakehouses, it remains one of the most powerful tools in the stack, and in my experience, one of the most underappreciated.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.