I’ve been building AI-powered applications for long enough to remember when “vector database” wasn’t a category anyone recognized. You either jammed embeddings into a blob column, used FAISS as a local library, or paid for something exotic. Then the RAG craze hit, and suddenly every Postgres shop had engineers asking whether they needed to migrate to Pinecone.
The honest answer is usually no. But the full answer is more interesting.
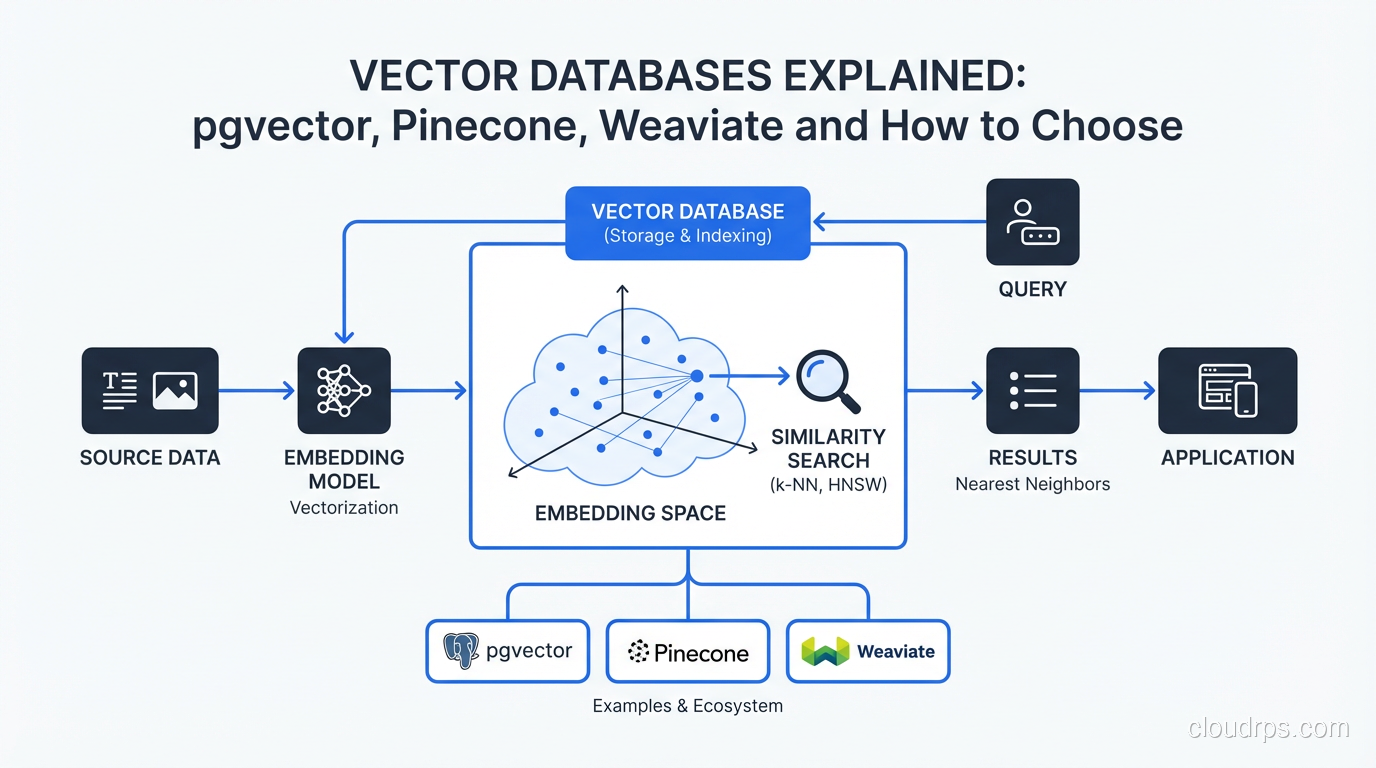
What a Vector Database Actually Does
Before you can evaluate your options, you need to understand the problem. Traditional databases search by exact match or range: “give me all users where country = 'US' and age > 30”. That’s fast because you’re comparing discrete values with B-tree indexes.
Vectors are different. An embedding is a dense array of floating-point numbers, typically 768 to 3072 dimensions, that encodes semantic meaning. When you embed the sentence “I can’t get my laptop to boot”, the resulting vector sits near “computer won’t start” and “BIOS failure” in high-dimensional space, even though those strings share zero characters. The query you want to answer is: “find the 10 vectors in my database that are most similar to this query vector.”
That’s an approximate nearest neighbor (ANN) search problem, and it’s fundamentally different from anything a B-tree can help you with.
Exact nearest neighbor search at scale is O(n) per query. With a million embeddings, that’s a million dot products per request. Fine for a prototype, fatal in production. Vector databases solve this with specialized indexing structures that trade a tiny bit of recall for massive speed improvements.
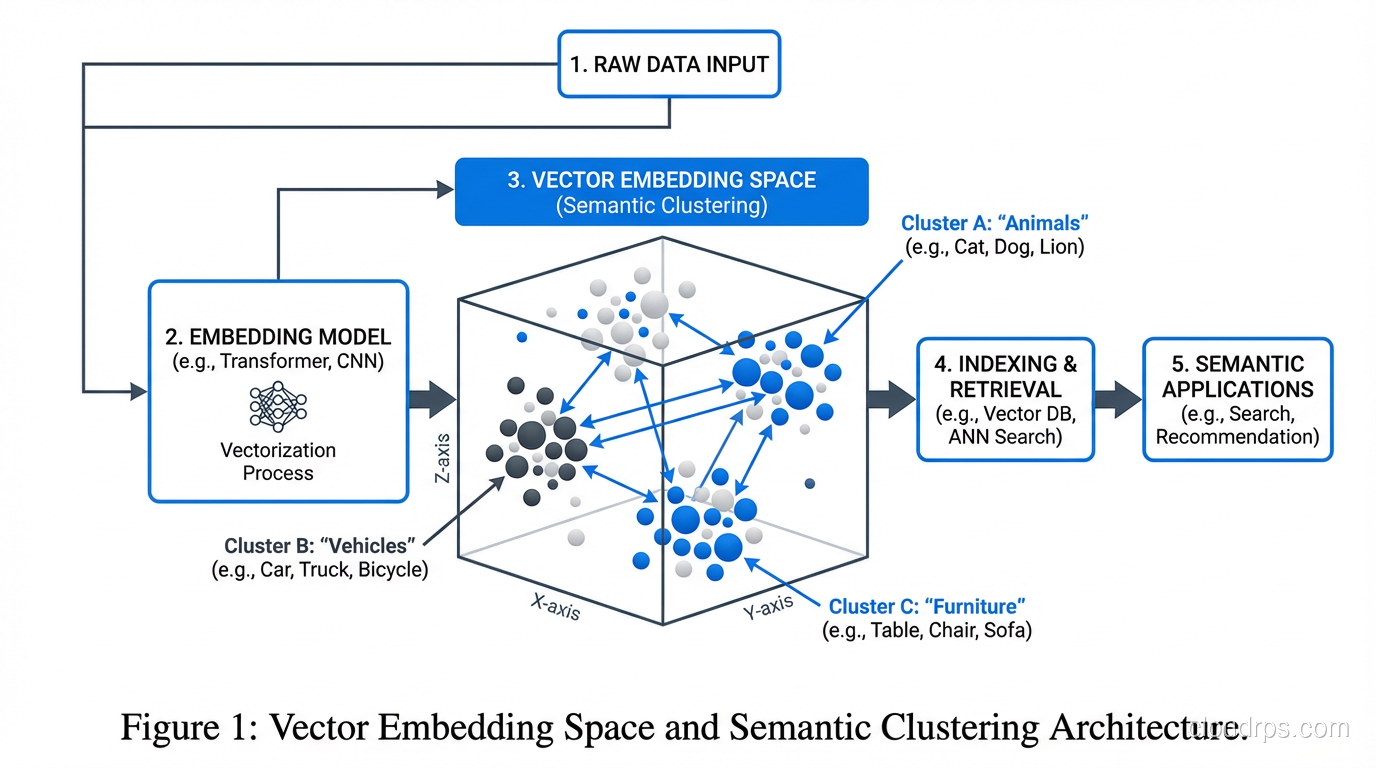
How ANN Indexing Works
There are two dominant index types you’ll encounter: IVF (Inverted File Index) and HNSW (Hierarchical Navigable Small World). Understanding the tradeoff between them will help you tune your system.
IVF partitions your vector space into clusters (Voronoi cells) during index build time. At query time, you only search the nearest N clusters rather than the entire dataset. Build time is relatively fast, and memory usage is proportional to your dataset. The downside: if your query sits near a cluster boundary, you’ll miss relevant results unless you probe enough clusters (the nprobe parameter). IVF works well when you can tolerate a training phase and want predictable memory overhead.
HNSW builds a layered graph where each vector connects to its nearest neighbors. At query time, you navigate the graph greedily, starting from entry points at the top layer and descending toward your query vector. HNSW consistently delivers better recall at the same query latency compared to IVF, but it consumes significantly more memory. A 1-million-vector HNSW index at 1536 dimensions can eat 6-12GB of RAM, which matters when you’re sizing your database instances.
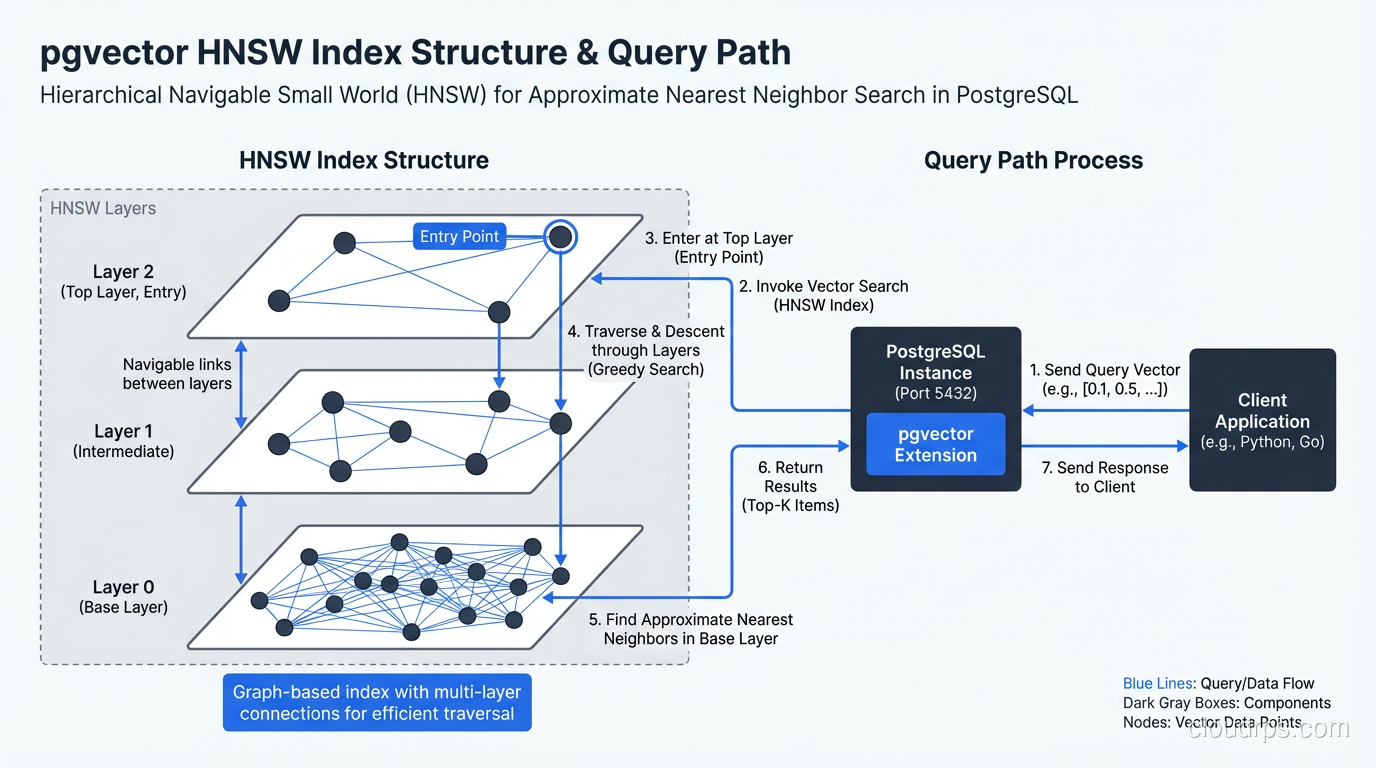
pgvector supports both. My default recommendation: use HNSW for datasets under 10 million vectors where you can afford the memory, IVF for larger datasets or memory-constrained environments.
pgvector: When Postgres Is Enough
I want to challenge the assumption that RAG applications need a dedicated vector database. In my experience, roughly 80% of teams building AI features would be better served by pgvector than by spinning up a separate vector DB service.
Here’s why. Your embeddings don’t exist in isolation. They’re almost always associated with metadata: document IDs, timestamps, user IDs, tenant IDs, content categories. Real applications need to filter: “find the 10 most similar vectors, but only from documents uploaded by this user in the last 30 days.” Dedicated vector databases support metadata filtering, but they’re bolted on. Postgres does it natively through SQL, with all the indexing power you already understand.
pgvector adds a vector column type to Postgres and supports both IVF and HNSW indexes. The basic setup:
CREATE EXTENSION vector;
CREATE TABLE documents (
id bigserial PRIMARY KEY,
user_id bigint NOT NULL,
content text,
embedding vector(1536),
created_at timestamptz DEFAULT now()
);
-- HNSW index for fast ANN search
CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops);
-- Query: find 5 nearest neighbors for a given user
SELECT id, content, 1 - (embedding <=> $1) AS similarity
FROM documents
WHERE user_id = $2
ORDER BY embedding <=> $1
LIMIT 5;
The <=> operator is cosine distance. You also have <-> for Euclidean distance and <#> for negative inner product (dot product). For text embeddings from OpenAI or Cohere, cosine distance is almost always what you want.
Performance at scale depends on your HNSW parameters. The two that matter most are m (number of connections per layer, default 16) and ef_construction (search depth during build, default 64). Higher values mean better recall but slower build time and more memory. For production, I typically use m=16, ef_construction=128 as a starting point and benchmark from there.
The pgvectorscale extension, from Timescale, adds a DiskANN-inspired index called StreamingDiskANN that stores most of the index on disk rather than RAM. If you have 50+ million vectors and can’t fit an HNSW index in memory, this is worth evaluating. It cuts memory requirements by 10x with minimal recall degradation.
When You Actually Need a Dedicated Vector Database
Honest answer: at sufficient scale, or with specific operational requirements.
Pinecone is a fully managed, serverless vector database. You send it vectors and queries via REST API. It handles indexing, sharding, replication, and scaling transparently. The developer experience is excellent. The tradeoff is cost: Pinecone is expensive relative to self-hosted alternatives at the same query volume, and you’re entirely dependent on their infrastructure.
Pinecone makes sense when: you want zero operational overhead, your team doesn’t have database expertise, you’re doing pure vector search without complex SQL filtering needs, or you need to scale to hundreds of millions of vectors without operational pain.
Weaviate is an open-source vector database with strong GraphQL and hybrid search capabilities. It supports BM25 keyword search alongside vector similarity, letting you do “find documents that match this keyword AND are semantically similar to this vector.” This hybrid approach often outperforms pure vector search in RAG systems, because pure semantic search sometimes retrieves vaguely relevant documents while missing exact keyword matches.
Weaviate’s schema is more rigid than pgvector but that structure pays dividends in multi-modal workloads, where you’re mixing text, image, and tabular embeddings in the same search.
Qdrant deserves a mention. It’s Rust-based, extremely fast, and has excellent support for payload filtering (their term for metadata filters). The filtering implementation is better than most competitors: instead of post-filtering results after ANN search (which can decimate your result count), Qdrant uses filtered HNSW that applies predicates during graph traversal. If you have highly selective filters, that distinction matters enormously.
Chroma is the “just works” option for development and small teams. Pure Python, embedded or server mode, zero configuration. I wouldn’t run it at production scale, but for prototyping a RAG system in an afternoon, it’s unbeaten.
The Hybrid Search Reality
Pure vector search has a dirty secret: it sometimes retrieves complete nonsense with high similarity scores. I’ve seen RAG systems confidently return chunks about Python the programming language in response to queries about Monty Python sketches, because the embedding models associated them semantically.
Production RAG systems almost always benefit from hybrid search: combining vector similarity with BM25 or TF-IDF keyword scoring, then merging the two result lists using Reciprocal Rank Fusion (RRF). This approach surfaces documents that are both semantically relevant AND contain the actual terms the user typed.
If you’re using pgvector, you can implement hybrid search using the pg_trgm extension for trigram-based text similarity alongside your vector searches, then combining the rankings in application code. It’s more work than a database that supports hybrid natively, but it’s absolutely doable.
Operational Considerations
Vector databases have some specific operational characteristics worth knowing before you go to production.
Index build time: HNSW indexes are expensive to build. On a dataset of 10 million 1536-dimension vectors, building an HNSW index can take hours. If you’re doing bulk imports, plan for this. Consider IVF if you’re frequently reindexing.
Embedding drift: When you switch embedding models, you have to re-embed your entire corpus and rebuild your index. This isn’t a minor inconvenience at 50 million documents. Version your embeddings carefully and plan for re-indexing windows before you need them.
Dimensionality and storage: A 1536-dimension vector at float32 precision is 6KB. 100 million of those is 600GB. At float16 (which most models support with minimal quality loss), that’s 300GB. Some newer models like Matryoshka embeddings support truncation to lower dimensions, letting you trade quality for storage at query time. This is worth investigating if storage costs are a concern.
Connection pooling: This applies equally to pgvector and dedicated databases. Vector queries can be CPU-intensive. Use PgBouncer or similar connection pooling to avoid exhausting database connections under load. I’ve seen teams hit connection limits before they hit query latency issues.
Monitoring: Track your recall rate in production. Set up periodic evaluations where you run test queries with known good answers and verify your ANN index is still returning them. Index degradation after major data additions is rare but real, especially with IVF after significant distribution shift in your data. For deeper monitoring patterns, distributed tracing helps you understand where latency comes from in your full RAG pipeline.
Making the Decision
Here’s the framework I use when teams ask me which vector database to choose:
Start with pgvector if: you already run Postgres, your dataset is under 50 million vectors, you need complex metadata filtering, you want to avoid additional infrastructure, or your team doesn’t have dedicated database expertise. The operational simplicity of keeping everything in one database is genuinely underrated. You can always migrate later.
Consider Qdrant or Weaviate if: you’re building a dedicated search service that might hit 100M+ vectors, you need best-in-class hybrid search without implementing it yourself, or you want vector search as a dedicated microservice with its own scaling story.
Consider Pinecone if: you’re a small team that wants managed infrastructure and can afford the cost premium, or you need to move fast and operational burden is your biggest constraint.
Avoid building on FAISS alone in production. I’ve done it. The index lives in memory, reloading it takes minutes, and there’s no built-in persistence or replication. It’s an excellent research library that was never designed to be a production database.
The most important thing I’d tell any team starting a RAG project: don’t over-engineer the vector store upfront. Ship with pgvector, measure where you actually hit limits, and migrate when you have real data about your query patterns. I’ve watched teams spend weeks evaluating vector databases when their bottleneck turned out to be the quality of their chunking strategy, not the database at all.
The embedding quality and retrieval logic matter more than the database you put them in. Get those right first.
For related infrastructure decisions, check out how we approach database replication for high-availability setups, SQL vs NoSQL trade-offs for understanding your data model options, and LLM inference infrastructure for the compute side of your AI stack. If you’re thinking about cost, the FinOps guide has patterns that apply directly to managing embedding API and vector DB costs at scale.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.