The first time someone told me about “serverless computing,” I asked them to point at the thing that doesn’t have servers. They couldn’t, because of course there are servers. There are always servers. The name is marketing, not engineering.
But here’s the thing: once you get past the misleading name, serverless represents a genuinely important shift in how we build and deploy software. I’ve been building infrastructure for over thirty years, and I’ve watched every major paradigm shift in that time. Serverless is real. It’s just not what most people think it is.
What Serverless Actually Means
Serverless doesn’t mean “no servers.” It means “no servers you have to think about.”
More precisely, serverless is an execution model where the cloud provider dynamically manages the allocation and provisioning of servers. You write code, you deploy it, and the provider handles everything else: the hardware, the operating system, the runtime, the scaling, the availability.
The key characteristics:
No server management. You don’t provision, patch, or maintain any servers. You don’t even choose server sizes in most cases.
Pay-per-execution. You’re billed for actual compute time consumed, not for idle capacity. If nobody calls your function for an hour, you pay nothing for that hour.
Auto-scaling to zero. When there’s no traffic, no compute resources are allocated. When traffic spikes, the platform scales out automatically with no configuration required.
Event-driven. Serverless functions are triggered by events: HTTP requests, database changes, file uploads, message queue items, scheduled timers.
This is a fundamentally different model from running virtual machines in the cloud. With EC2 or similar services, you’re still in the server management business. You pick an instance size, you manage the OS, you handle patching, you configure auto-scaling groups. Serverless abstracts all of that away.
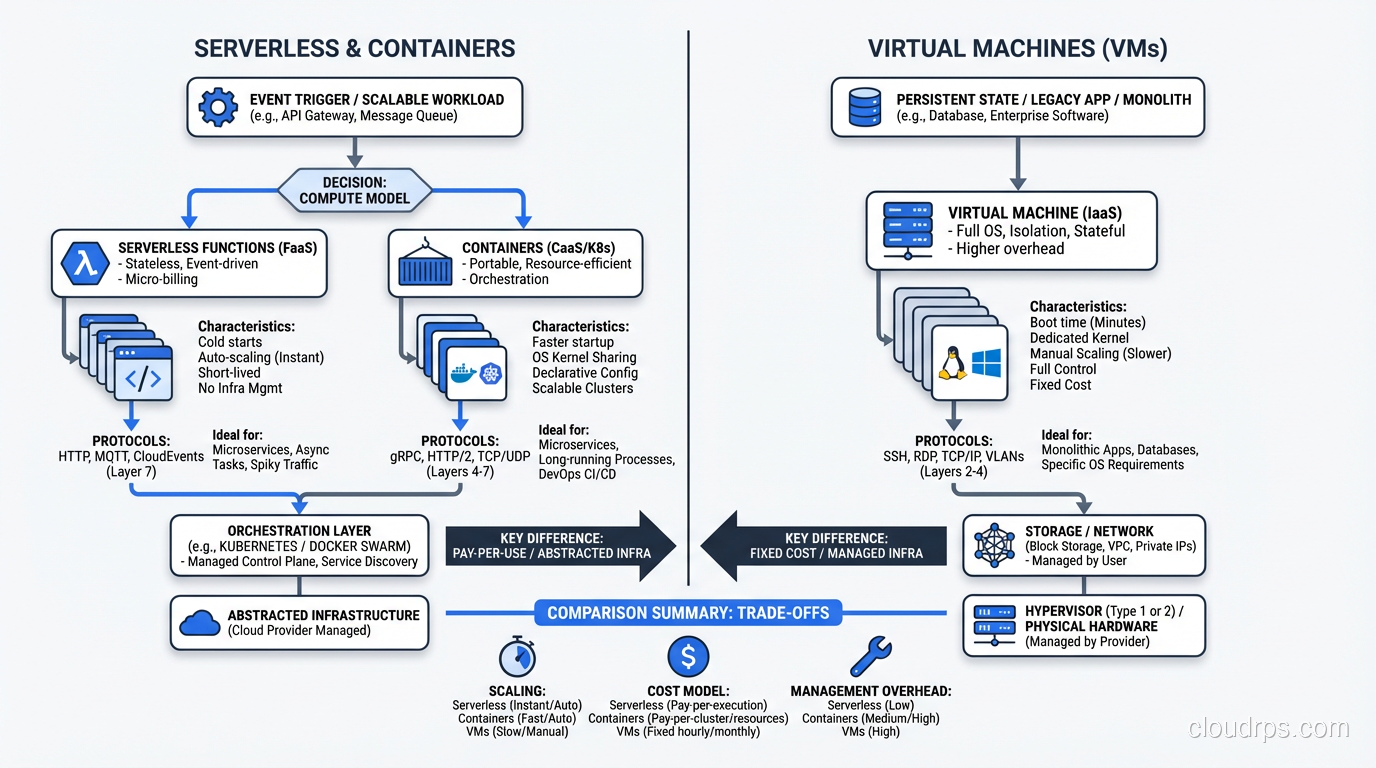
The Spectrum of Serverless
Here’s something that confuses people: serverless isn’t just Lambda (or Azure Functions, or Google Cloud Functions). There’s a whole spectrum of services that operate on serverless principles.
Functions as a Service (FaaS): AWS Lambda, Azure Functions, Google Cloud Functions. This is what most people mean when they say “serverless.” You deploy individual functions that execute in response to events.
Serverless containers: AWS Fargate, Google Cloud Run, Azure Container Instances. You deploy containers, but you don’t manage the underlying infrastructure. No clusters to configure, no nodes to patch.
Serverless databases: DynamoDB, Aurora Serverless, Firestore. The database scales automatically, and you pay per request or per consumed capacity rather than for fixed database instances.
Serverless storage: S3 is arguably the original serverless service. You don’t provision storage capacity; you just upload objects and pay per GB stored and per request.
Serverless messaging: SQS, SNS, EventBridge. Fully managed messaging infrastructure with per-message pricing.
The common thread across all of these: you don’t manage infrastructure, and you pay for what you use. The “serverless” concept is really about an operational model, not a specific technology.
When Serverless Works Brilliantly
I’ve deployed serverless in production for dozens of use cases. Here’s where it shines:
Event Processing Pipelines
A client needed to process images uploaded to S3: generate thumbnails, extract metadata, run content moderation. Traditional approach: run a fleet of EC2 instances polling an SQS queue. Serverless approach: S3 event triggers Lambda, Lambda processes the image and writes results to DynamoDB.
The serverless version handles 100 uploads per day and 100,000 uploads per day with zero configuration changes. At low volume, it costs pennies. At high volume, it scales automatically. We never had to think about instance sizes, auto-scaling policies, or right-sizing.
API Backends with Variable Traffic
REST APIs that handle unpredictable traffic are a sweet spot. A Lambda function behind API Gateway scales from zero to thousands of concurrent executions automatically. For startups with spiky traffic patterns, this is transformational. No over-provisioning, no scrambling to scale during traffic spikes.
Scheduled Jobs and Cron Tasks
The classic use case that nobody writes blog posts about. Need to run a report every night? A Lambda function on a CloudWatch Events schedule. Need to clean up old data weekly? Lambda. Need to check for certificate expiration daily? Lambda. These tasks run for seconds, execute once, and cost fractions of a penny.
Glue Code Between Services
Lambda excels at being the connective tissue between other AWS services. S3 upload triggers Lambda triggers Step Functions orchestration triggers more Lambda functions. This event-driven composition is where serverless architecture really differentiates itself from traditional approaches.
When Serverless Falls Flat
Here’s where my experience diverges from the marketing materials. Serverless has real limitations, and ignoring them leads to painful failures.
Long-Running Processes
Lambda has a 15-minute maximum execution time. If your workload takes longer than that, Lambda doesn’t work without significant architectural gymnastics (chunking work across multiple invocations, using Step Functions for orchestration). I’ve seen teams spend weeks re-architecting a process to fit Lambda’s constraints when a simple EC2 instance would have handled it in 20 minutes.
Consistent High-Throughput Workloads
If you’re processing millions of events per hour, consistently, 24/7, serverless might actually cost more than reserved instances. The per-execution pricing model favors variable, spiky workloads. For steady-state high throughput, the economics often favor dedicated compute.
I ran the numbers for a client processing 50 million API calls per day with consistent traffic. Lambda: roughly $14,000/month. Equivalent EC2 with reserved instances: roughly $4,000/month. The operational simplicity of Lambda has value, but a 3.5x cost premium was hard to justify.
Latency-Sensitive Applications
Cold starts are real. When a Lambda function hasn’t been invoked recently, the first invocation incurs startup time, anywhere from 100ms for a lightweight Python function to 10+ seconds for a Java function with heavy dependencies.
Provisioned Concurrency addresses this (keeps functions warm), but it eliminates the scale-to-zero cost benefit. At that point, you’re paying for idle capacity, which was the thing serverless was supposed to eliminate. This is one area where WebAssembly at the edge is genuinely compelling: WASM modules cold-start in 1-5ms because they share a runtime process rather than requiring isolated OS-level initialization, making sub-millisecond serverless latency achievable at the edge.
Complex Stateful Workflows
Serverless functions are stateless by design. If your application needs to maintain state between invocations (session data, in-progress transactions, cached computations) you need to externalize that state to a database or cache. This adds latency, complexity, and cost.
I’ve seen architectures where every Lambda function invocation makes 3-4 DynamoDB calls just to reconstitute state. The aggregate latency and cost of all those database calls often exceeds what a stateful server would have cost.
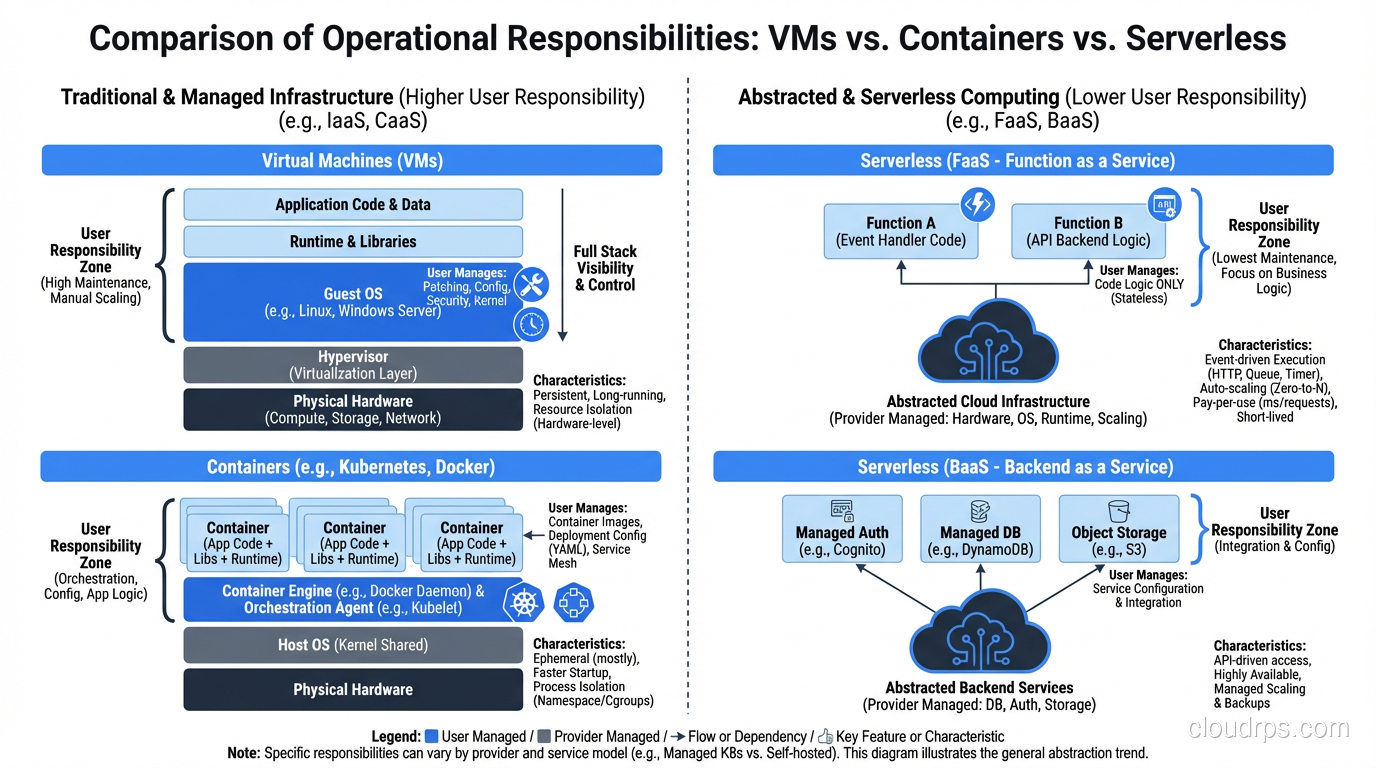
The Architecture Shift
Moving to serverless isn’t just swapping your execution environment. It fundamentally changes how you design systems.
From Monoliths to Functions
In a traditional architecture, you have a monolithic application running on a server. Routes, business logic, data access, all in one process. In serverless, each function typically handles a single concern. This is microservices taken to the extreme: micro-functions.
This granularity has benefits (independent scaling, independent deployment) and costs (more things to manage, distributed systems complexity, cold start multiplication).
From Synchronous to Event-Driven
Serverless pushes you toward event-driven architectures. Instead of Service A calling Service B directly and waiting for a response, Service A publishes an event, and Service B reacts to it asynchronously. This decoupling improves resilience but makes the system harder to reason about and debug.
From Always-On to On-Demand
The mental model shift from “my server is running” to “my code runs when triggered” is bigger than it sounds. You lose the ability to have background processes, in-memory caches, connection pools, and other patterns that depend on a persistent process.
The relationship between serverless and traditional service models is worth understanding. I covered that in IaaS vs PaaS vs SaaS: Cloud Service Models Explained.
The Observability Problem
This is the issue that bites hardest in production. Debugging a serverless application is fundamentally harder than debugging a traditional application.
With a server, I can SSH in, look at logs, check process state, examine network connections, profile the running code. With Lambda, I get CloudWatch logs and X-Ray traces. That’s it. The execution environment is ephemeral and inaccessible.
Distributed tracing becomes essential but also harder. A single user request might fan out across five Lambda functions, two DynamoDB tables, an SQS queue, and an SNS topic. Correlating all of that into a coherent trace requires investment in observability tooling.
I spent three days debugging a production issue in a serverless application where intermittent timeouts were caused by Lambda functions hitting the concurrent execution limit in a specific region. The error messages were unhelpful, the metrics were distributed across multiple services, and the root cause was a configuration default I didn’t know existed.
That experience taught me: your serverless observability investment needs to be proportional to your serverless architecture complexity. If you’re running a few Lambda functions for cron jobs, CloudWatch is fine. If you’re running a full microservices architecture on Lambda, you need dedicated observability tooling.
Serverless and the Scaling Story
The automatic scaling aspect of serverless deserves deeper examination because it’s both the biggest selling point and a source of surprises.
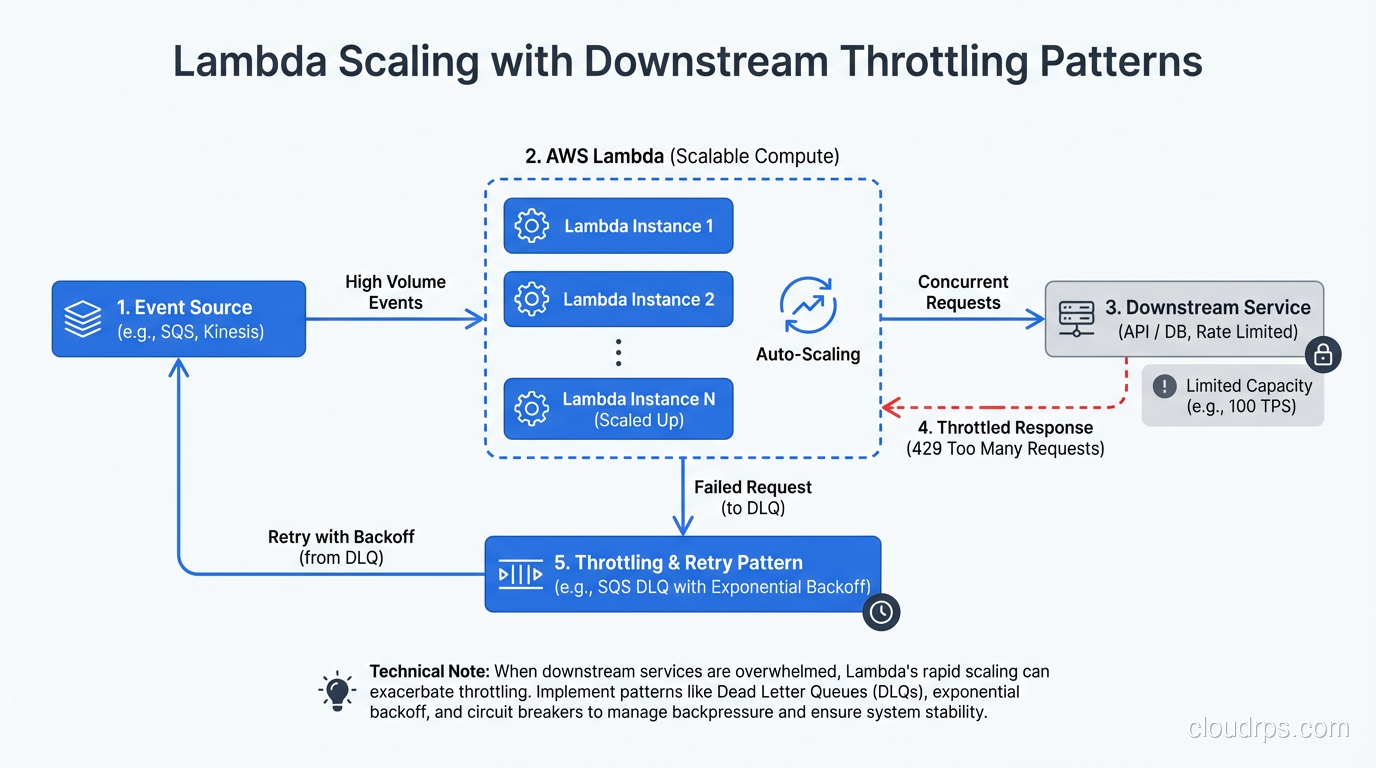
Lambda scales by running more concurrent instances of your function. If 100 requests arrive simultaneously, Lambda runs 100 concurrent copies. If 10,000 requests arrive, Lambda runs 10,000 copies (subject to concurrency limits).
This is different from traditional scaling approaches where you add more servers behind a load balancer. Lambda scaling is per-function, per-request, and near-instantaneous for warm invocations.
But here’s the catch: everything downstream of Lambda needs to scale too. I’ve seen this pattern more times than I care to admit: Lambda scales to 1,000 concurrent executions, each one opens a database connection, and the database falls over because it can’t handle 1,000 simultaneous connections. Lambda scaled perfectly. The system failed anyway.
The solution is to think about serverless scaling as a system property, not a function property. Use connection pooling (RDS Proxy), queue-based load leveling (SQS between Lambda and downstream services), or concurrency limits on the Lambda function itself.
My Honest Assessment After Seven Years of Serverless
I’ve been building with serverless since Lambda launched in 2014. Here’s where I’ve landed:
Serverless is excellent for event-driven, variable-traffic workloads. Image processing, webhooks, scheduled tasks, API backends with unpredictable traffic. These use cases are clear wins.
Serverless is problematic for latency-critical, stateful, or high-throughput workloads. Cold starts, state management complexity, and cost at scale are real constraints.
Serverless complexity is underestimated. The marketing says “just write code.” The reality is that you’re trading server management complexity for distributed systems complexity. Whether that’s a good trade depends on your team’s skills and your system’s requirements.
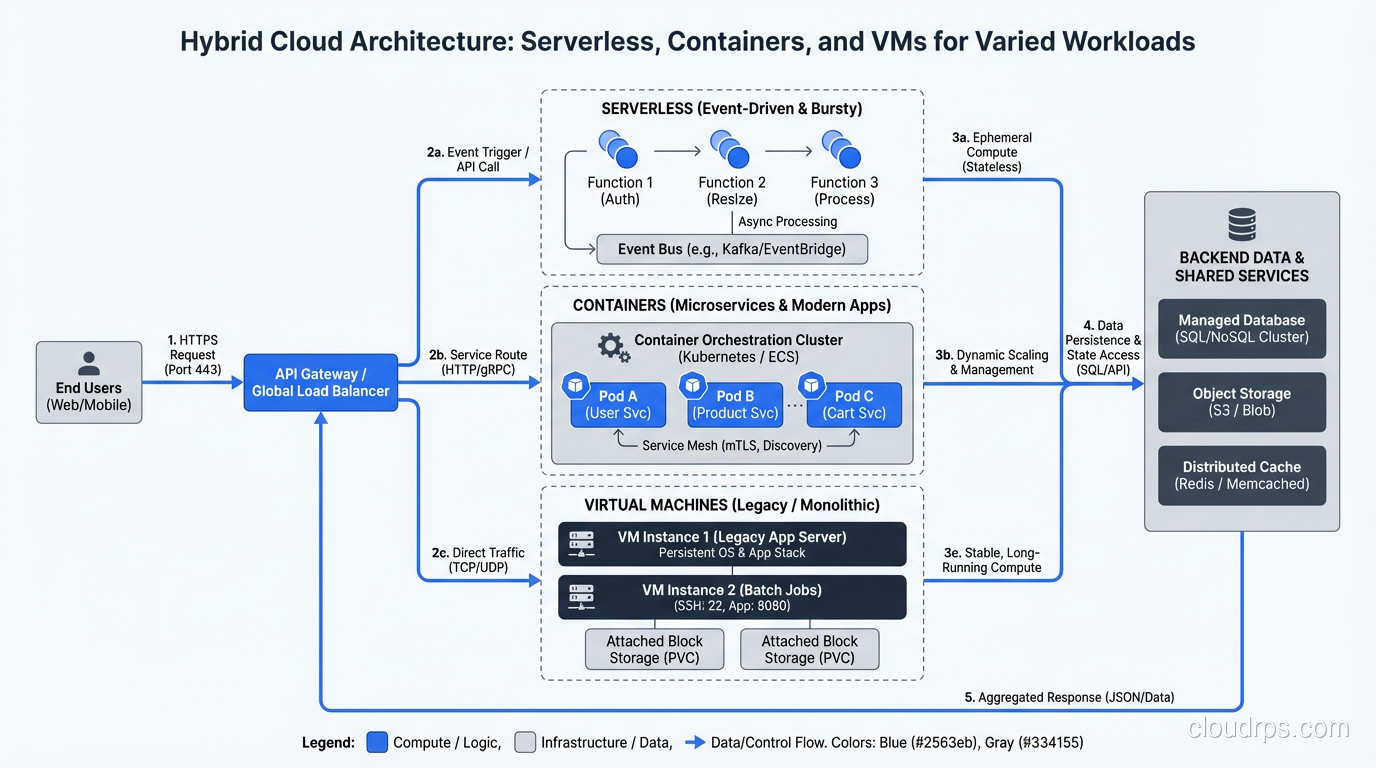
Serverless is not an all-or-nothing choice. The best architectures I’ve built use serverless where it shines and containers or VMs where it doesn’t. Lambda for event processing, Fargate for long-running services, EC2 for performance-critical databases. Use the right tool for each job.
The name is wrong. The hype is overdone. But the technology is real and genuinely useful when applied with clear eyes and realistic expectations. That’s the honest assessment from someone who’s shipped serverless to production and also cleaned up the mess when it was the wrong choice.
Get Cloud Architecture Insights
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.