DevOps
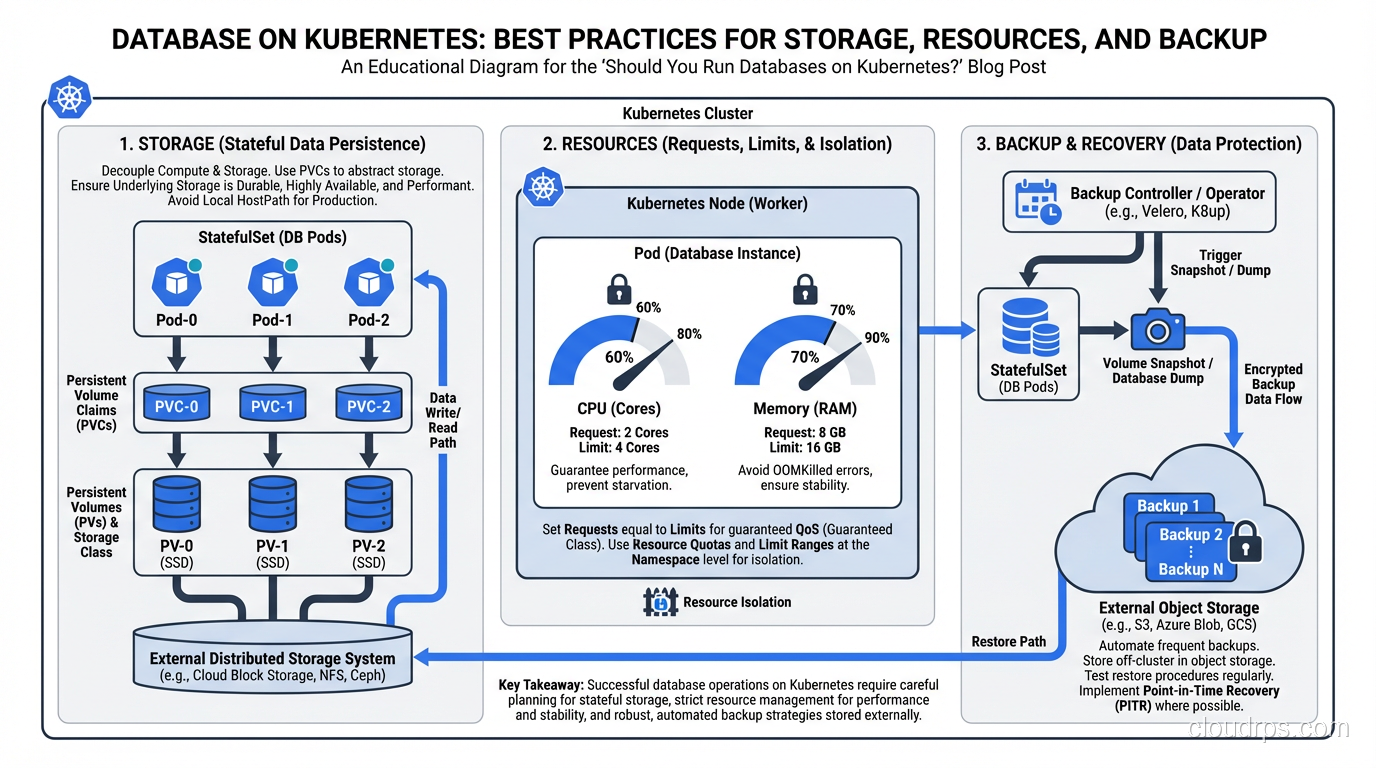
Should You Run Databases on Kubernetes? A Honest Assessment
An honest assessment of running databases on Kubernetes from someone who's tried it. When it works, when it doesn't, and what you need to get right.
An honest assessment of running databases on Kubernetes from someone who's tried it. When it works, when it doesn't, and what you need to get right.
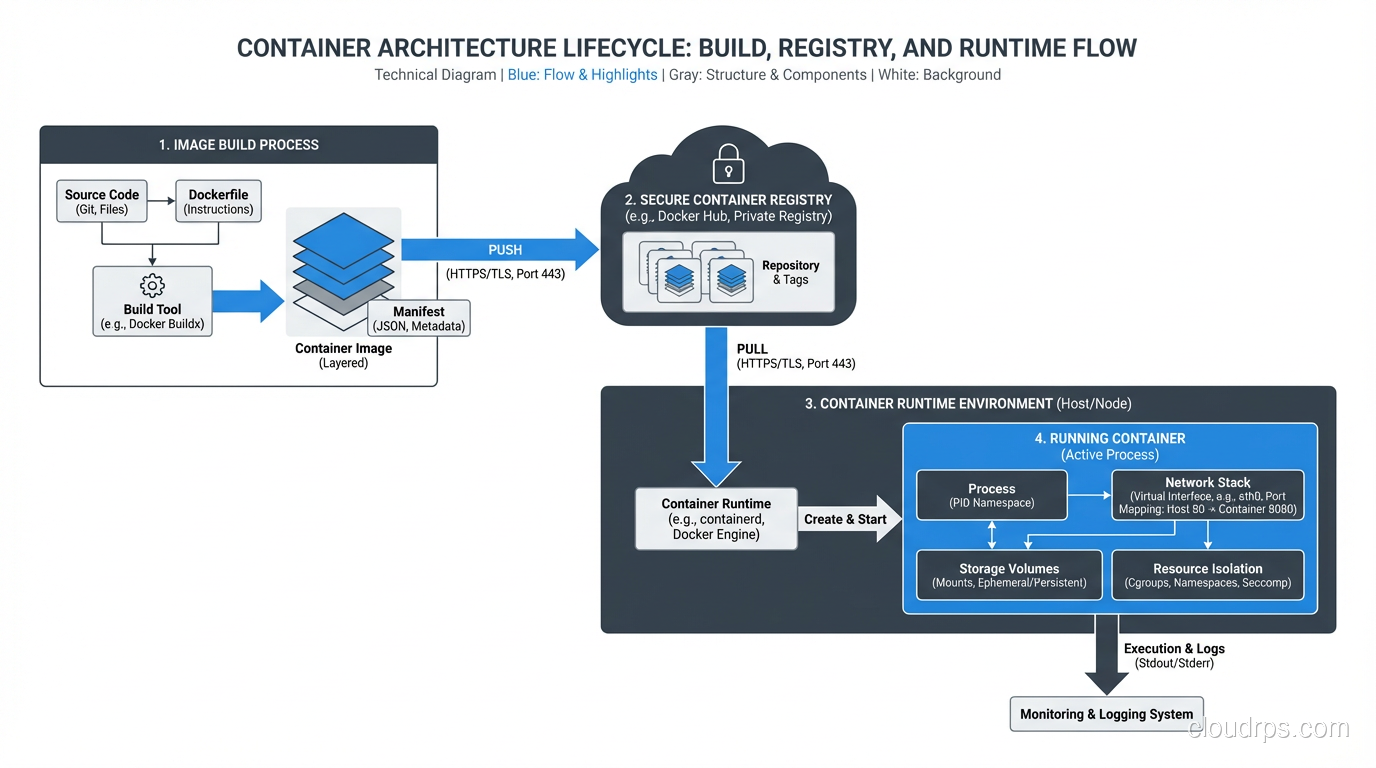
A senior architect's honest take on Kubernetes, Docker, and containers. What they are, when you need them, and when you absolutely don't.
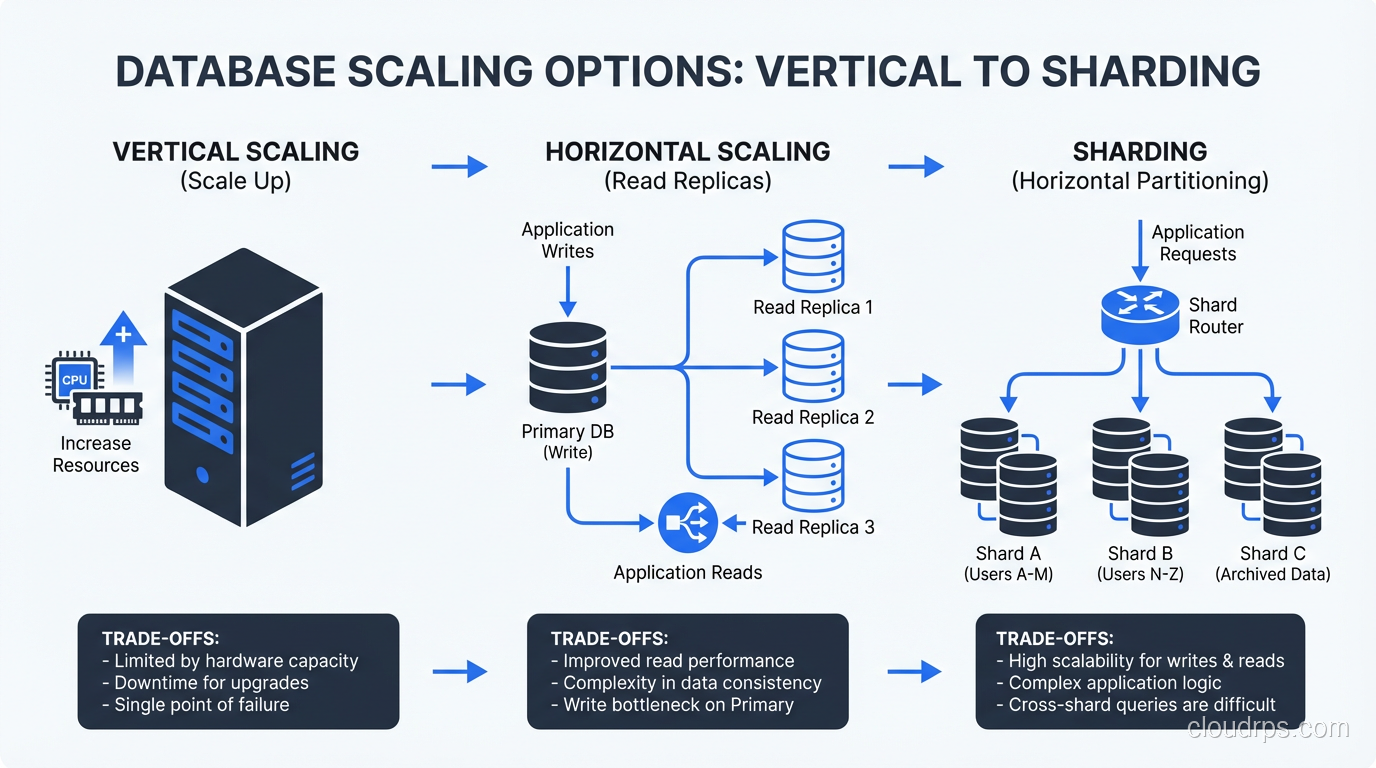
A practical guide to scaling web applications from an architect who's done it at every stage. From single server to distributed systems serving millions.
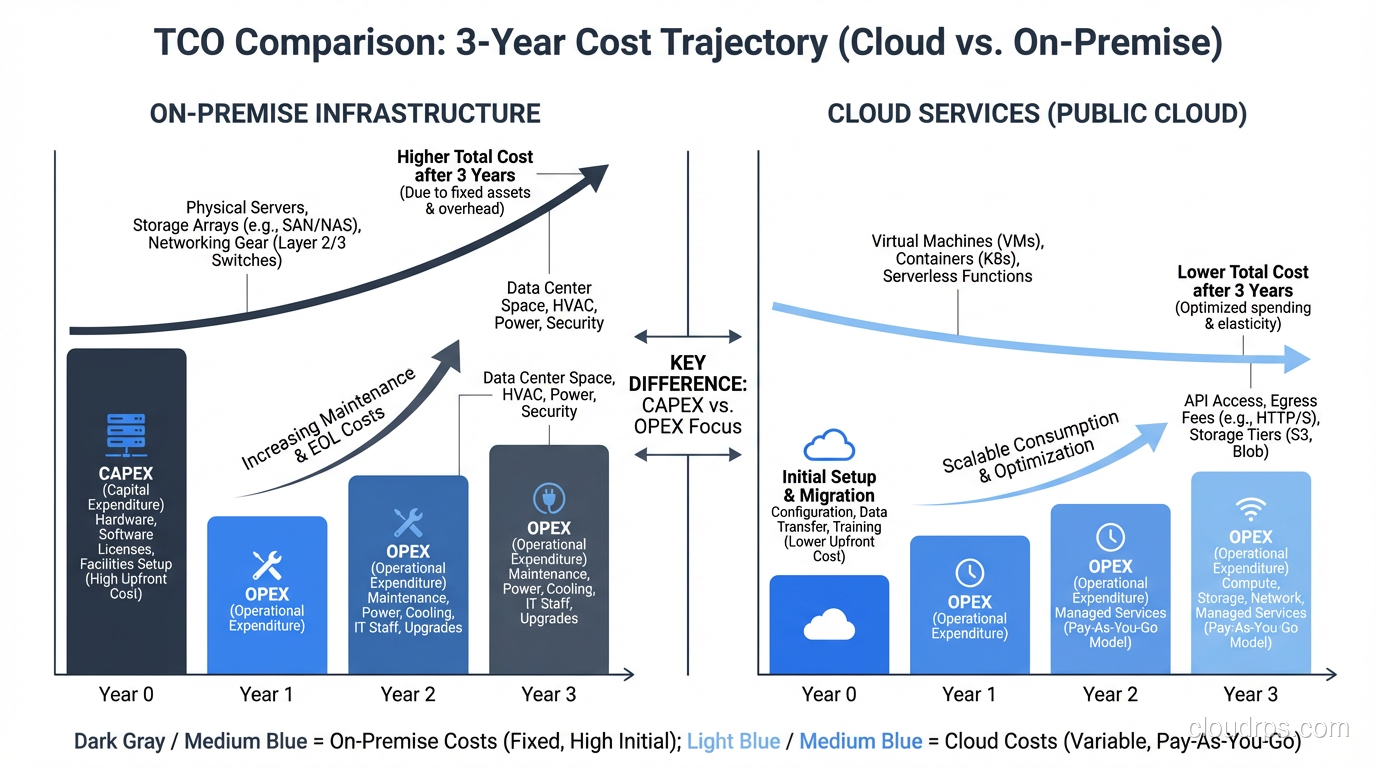
How to calculate total cost of ownership for cloud computing from an architect who's done it wrong and learned the hard way. Real costs, hidden costs, and how to compare.
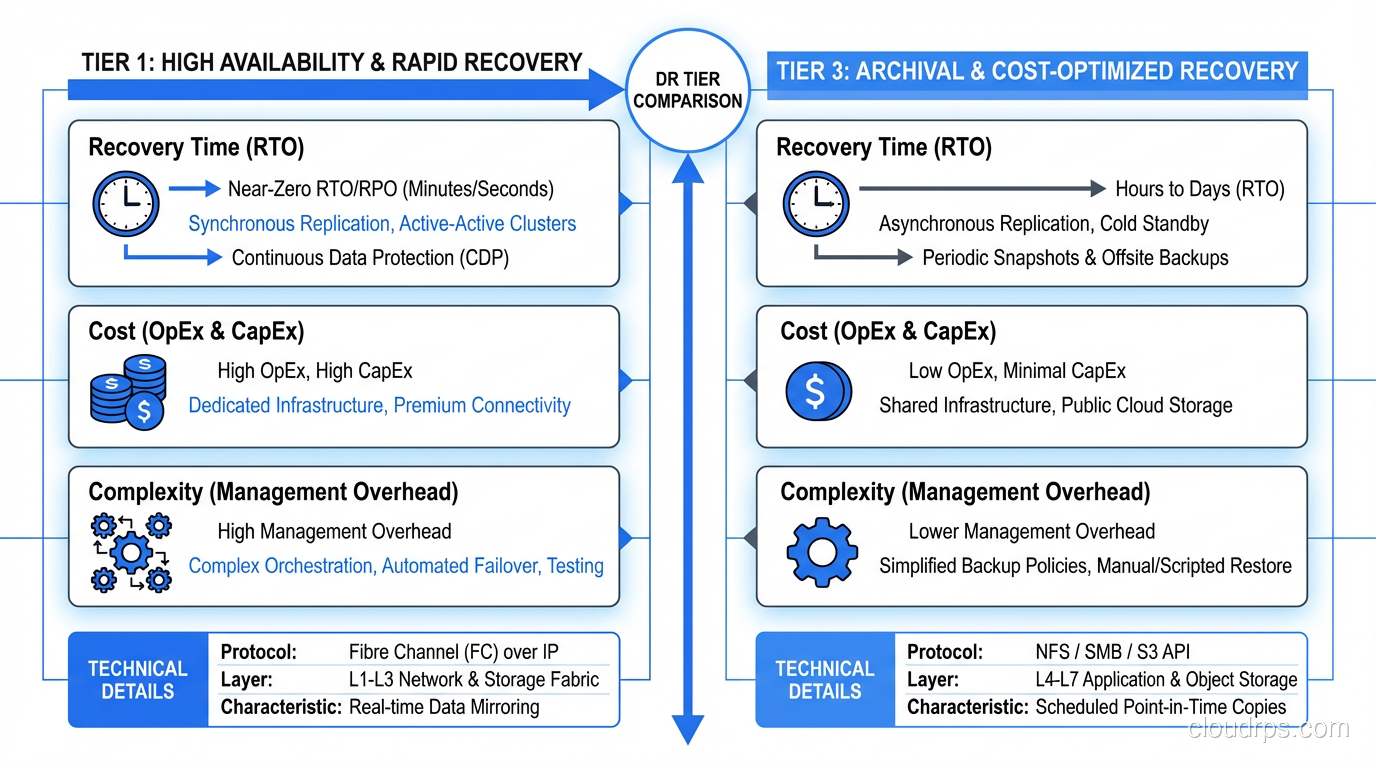
A practical disaster recovery planning guide from an architect who's survived real disasters. Strategies, tier models, testing frameworks, and playbooks.
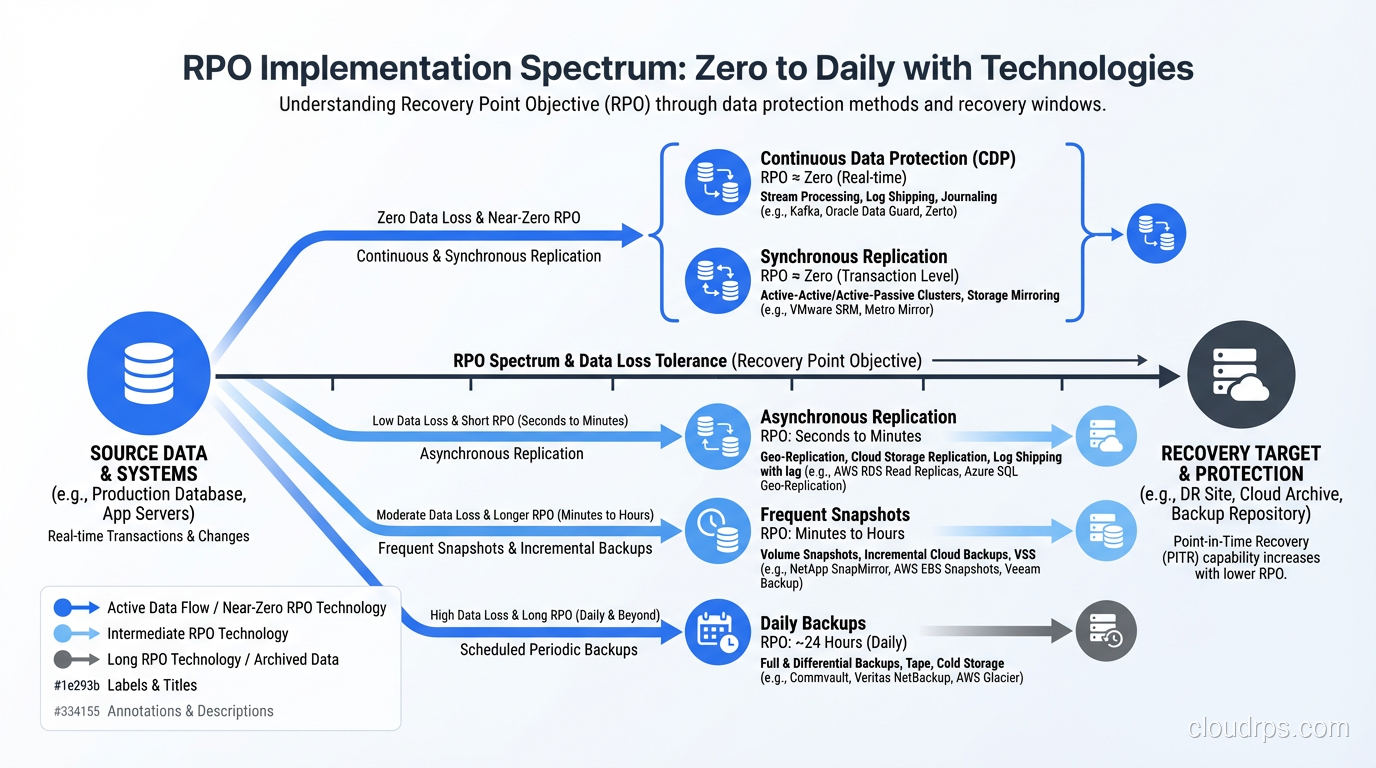
RTO and RPO explained by an architect who's set and tested them for decades. How to define recovery objectives that actually match your business needs.
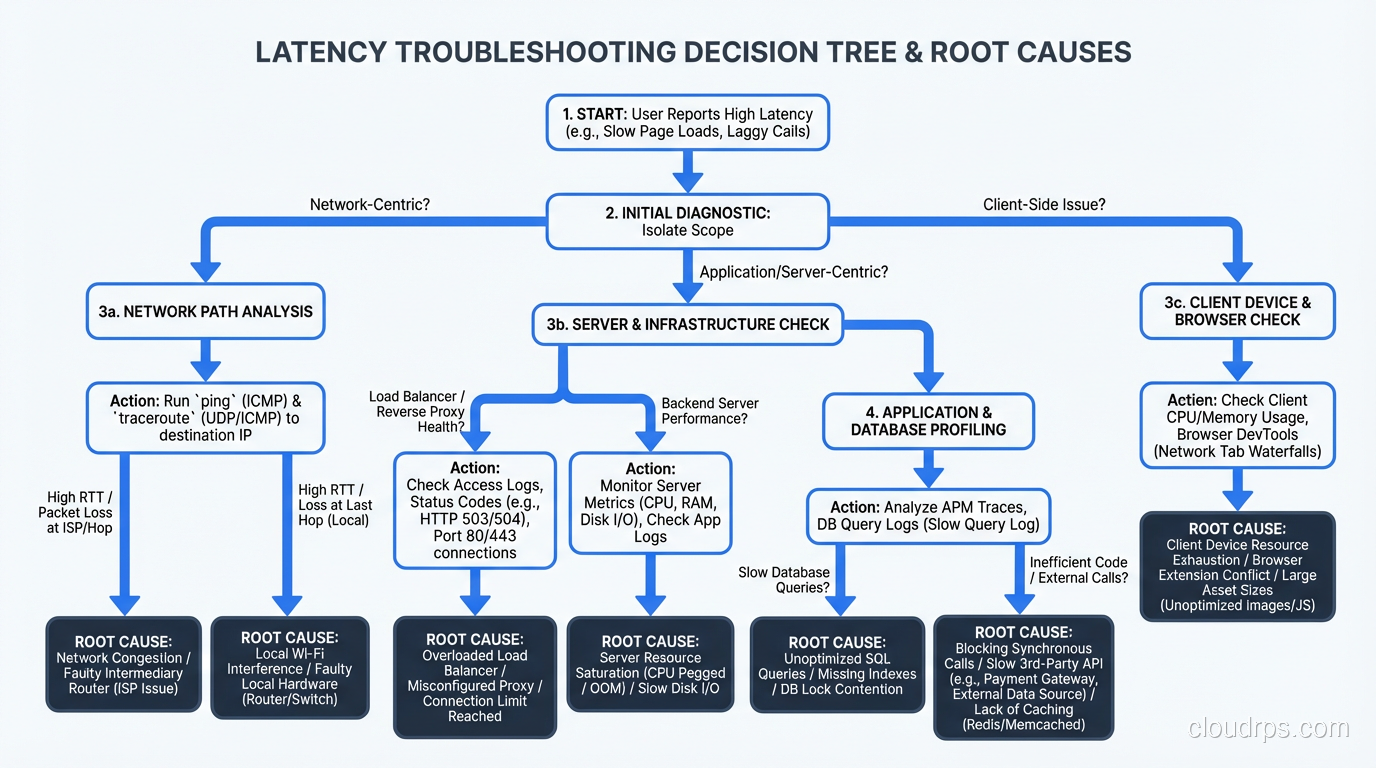
A systematic method for tracking down latency issues in production systems, from network to application to database, built from decades of war stories.
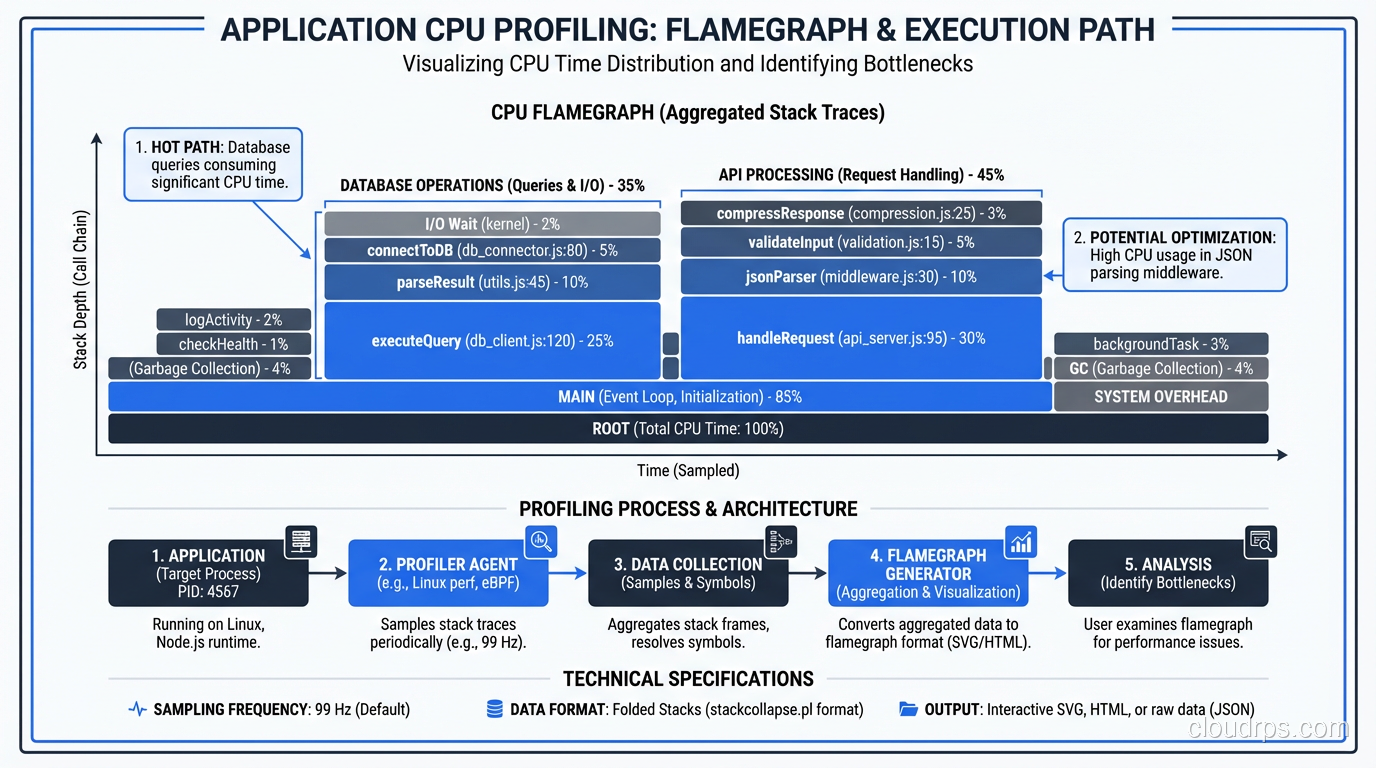
Hard-won performance tuning lessons from 30 years of fixing slow systems. Database optimization, application profiling, and the metrics that matter.
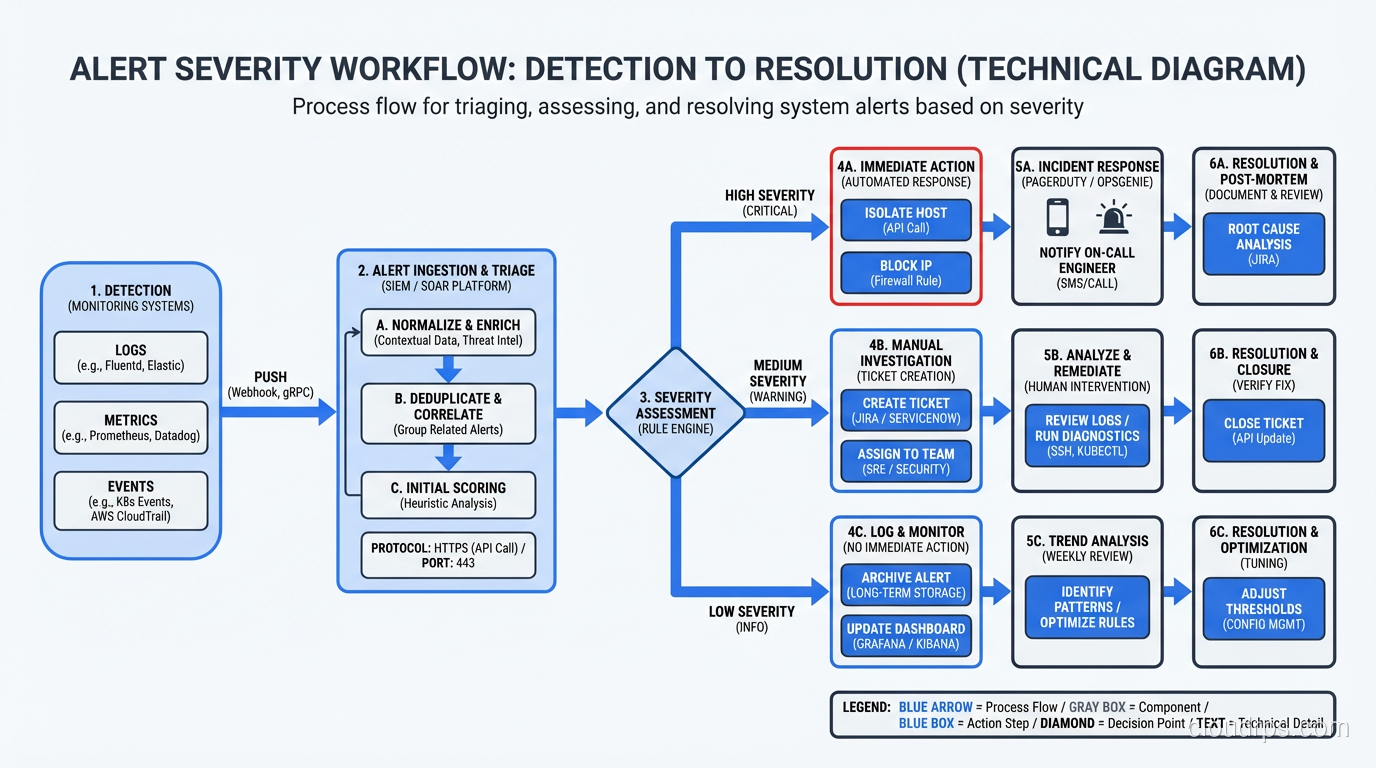
Practical monitoring and logging advice from three decades of production operations. What metrics matter, how to build alerts that work, and tools I trust.
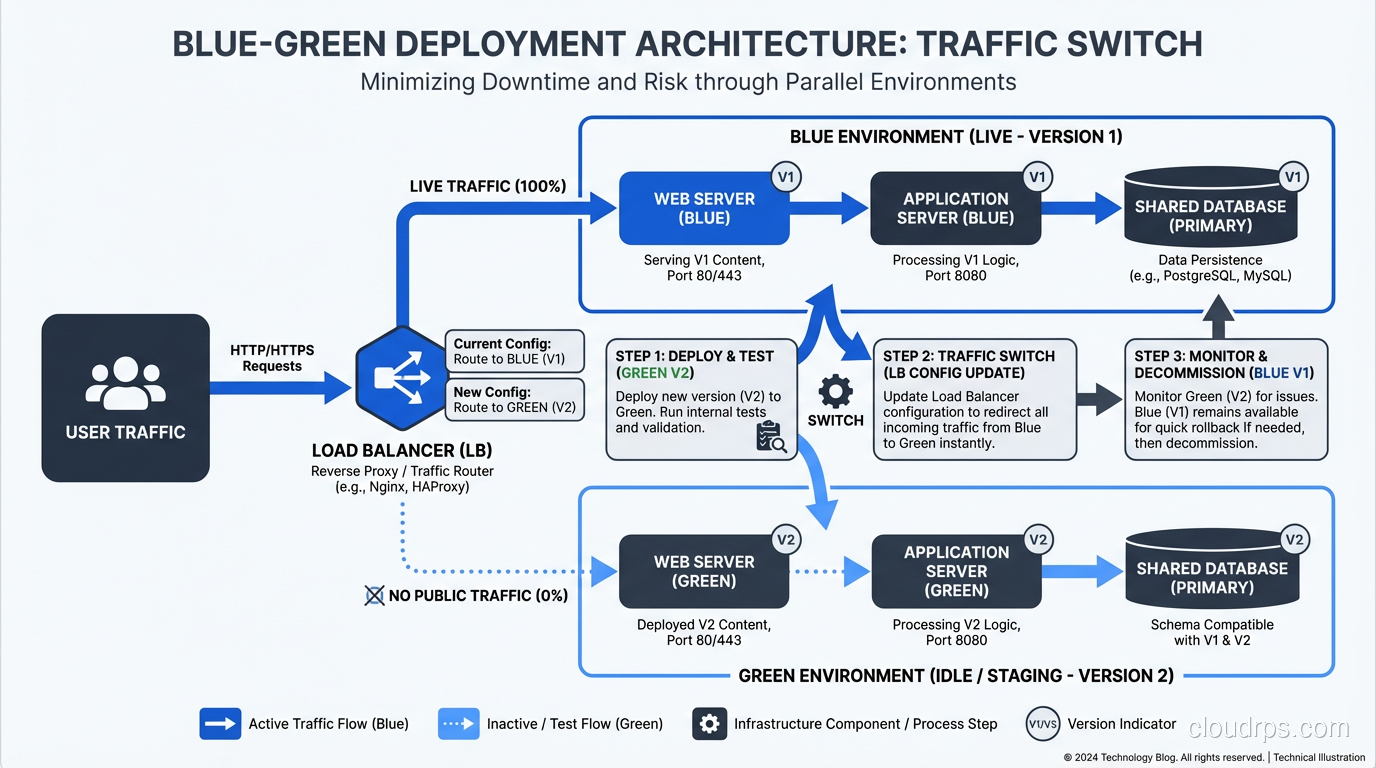
A battle-tested guide to blue-green deployments from an architect who's used them to eliminate downtime across hundreds of releases in production.
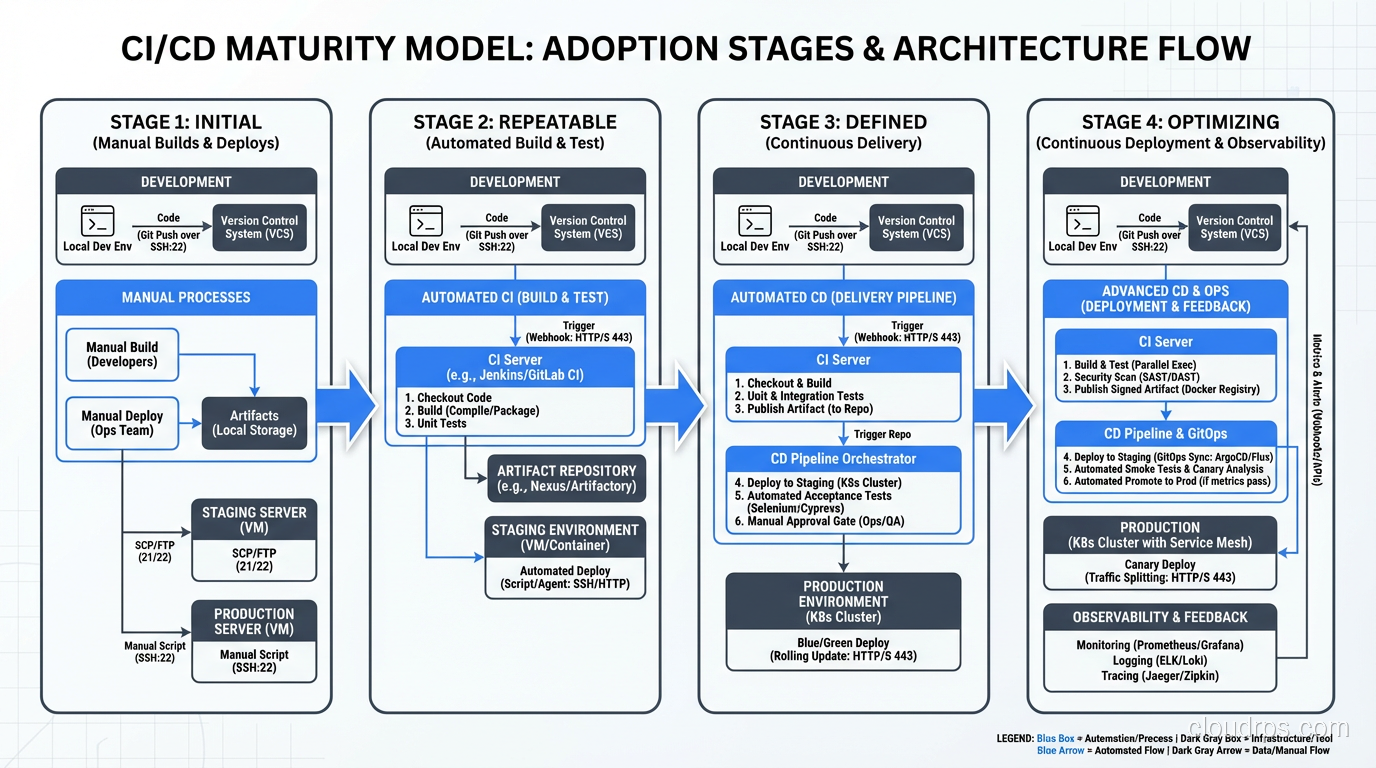
Learn CI/CD from someone who built pipelines before the tools existed. Continuous integration and delivery principles, patterns, and hard-won lessons.
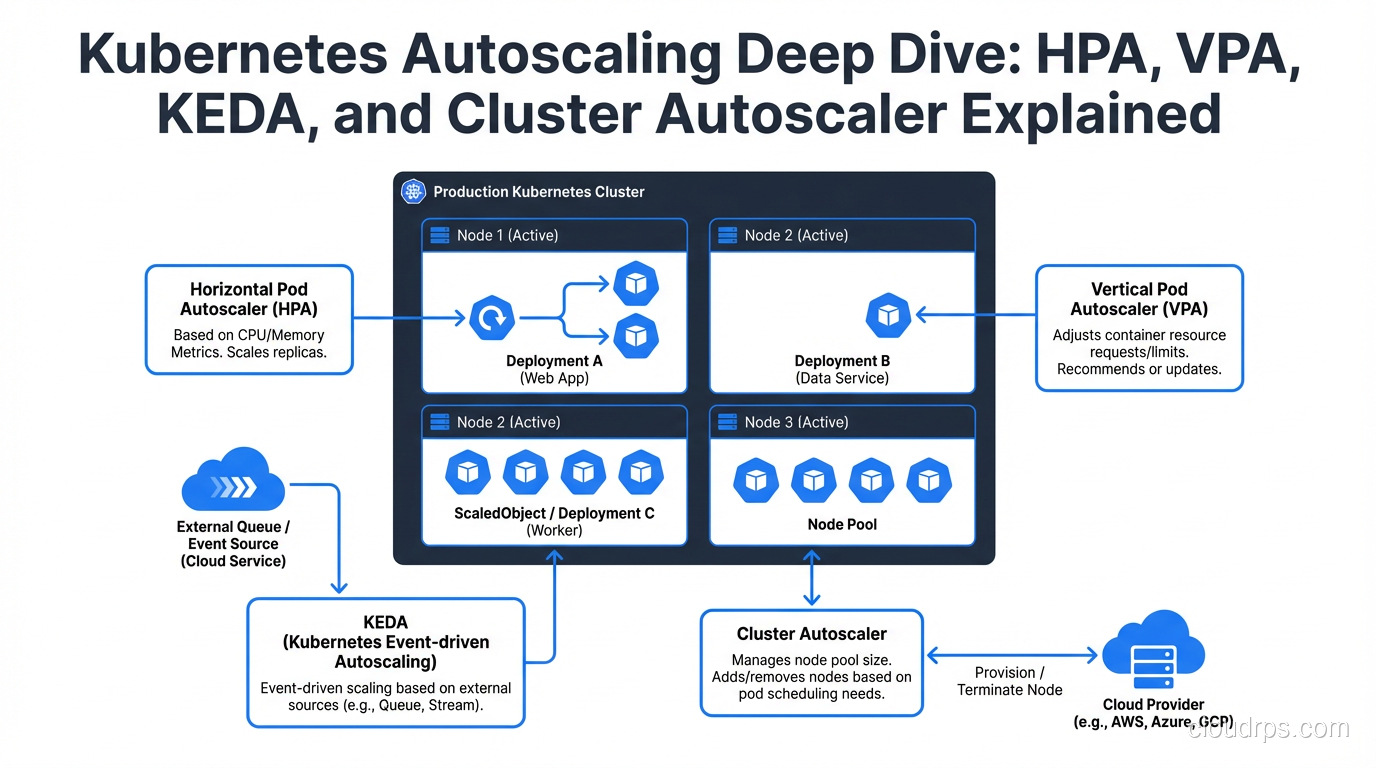
A practical guide to Kubernetes autoscaling: how HPA, VPA, KEDA, and Cluster Autoscaler work, when to use each, and how to avoid the pitfalls that catch most teams.
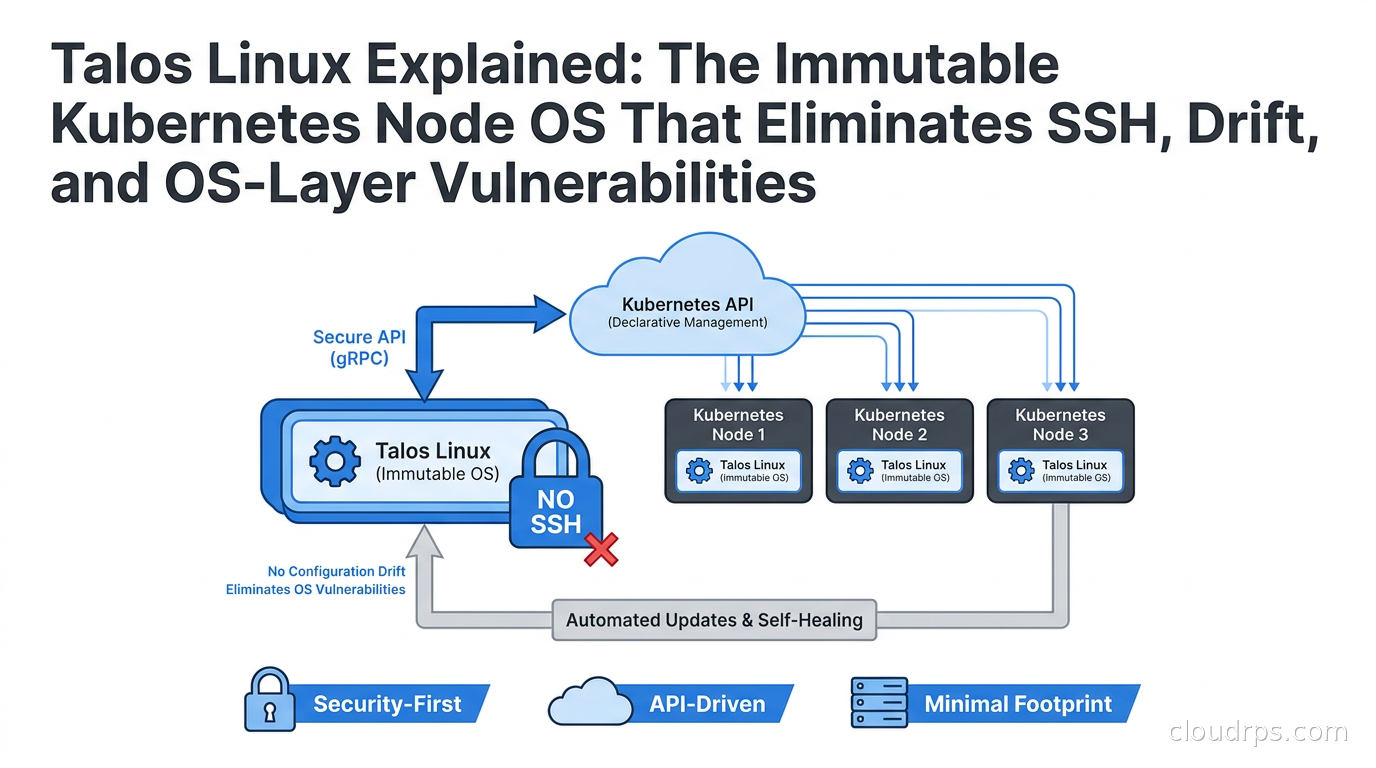
Talos Linux removes SSH, the shell, and mutable state from Kubernetes nodes entirely. Here's how it works, how it compares to Flatcar, Bottlerocket, and Fedora CoreOS, and why it's changing how serious teams run Kubernetes in production.
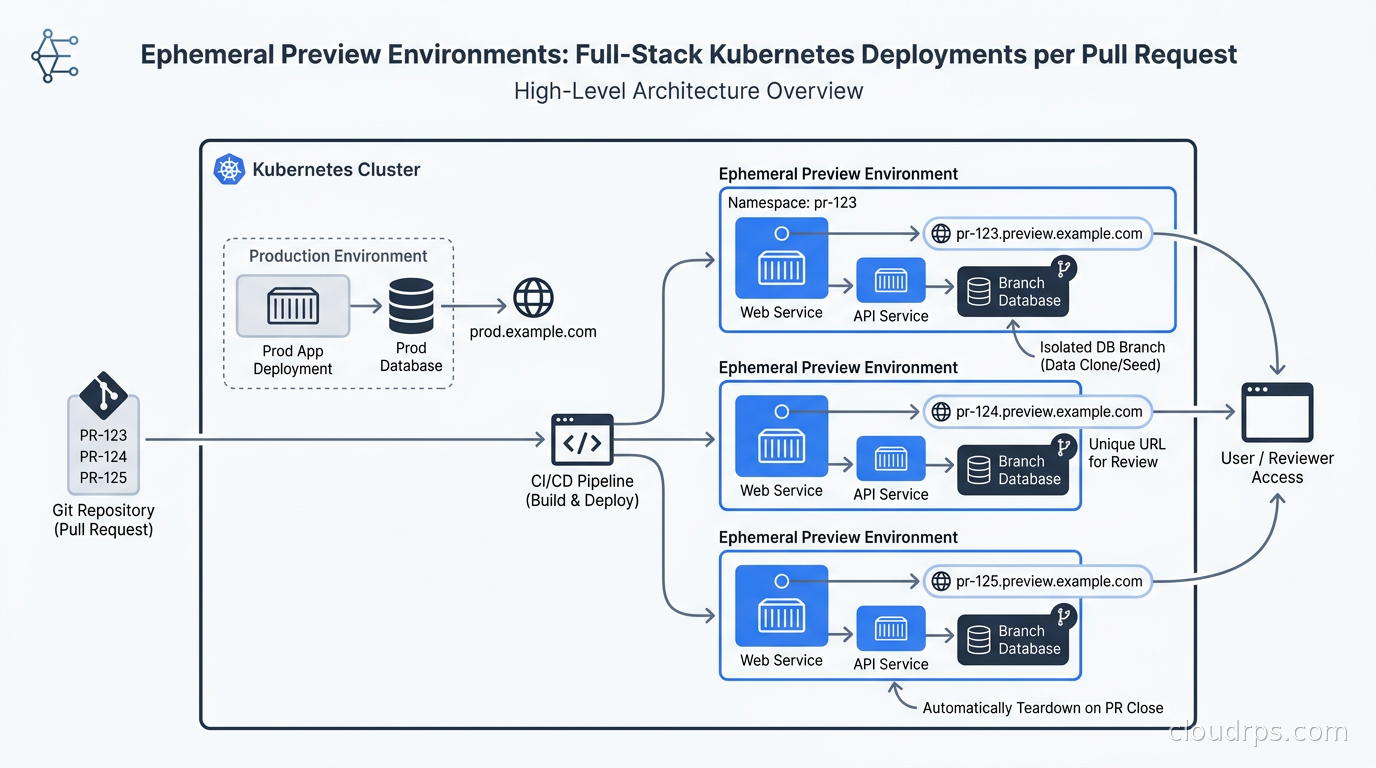
How to implement per-PR ephemeral preview environments on Kubernetes using ArgoCD ApplicationSets, Neon database branching, wildcard TLS, and automated cleanup — plus an honest look at managed platforms like Okteto and Bunnyshell.
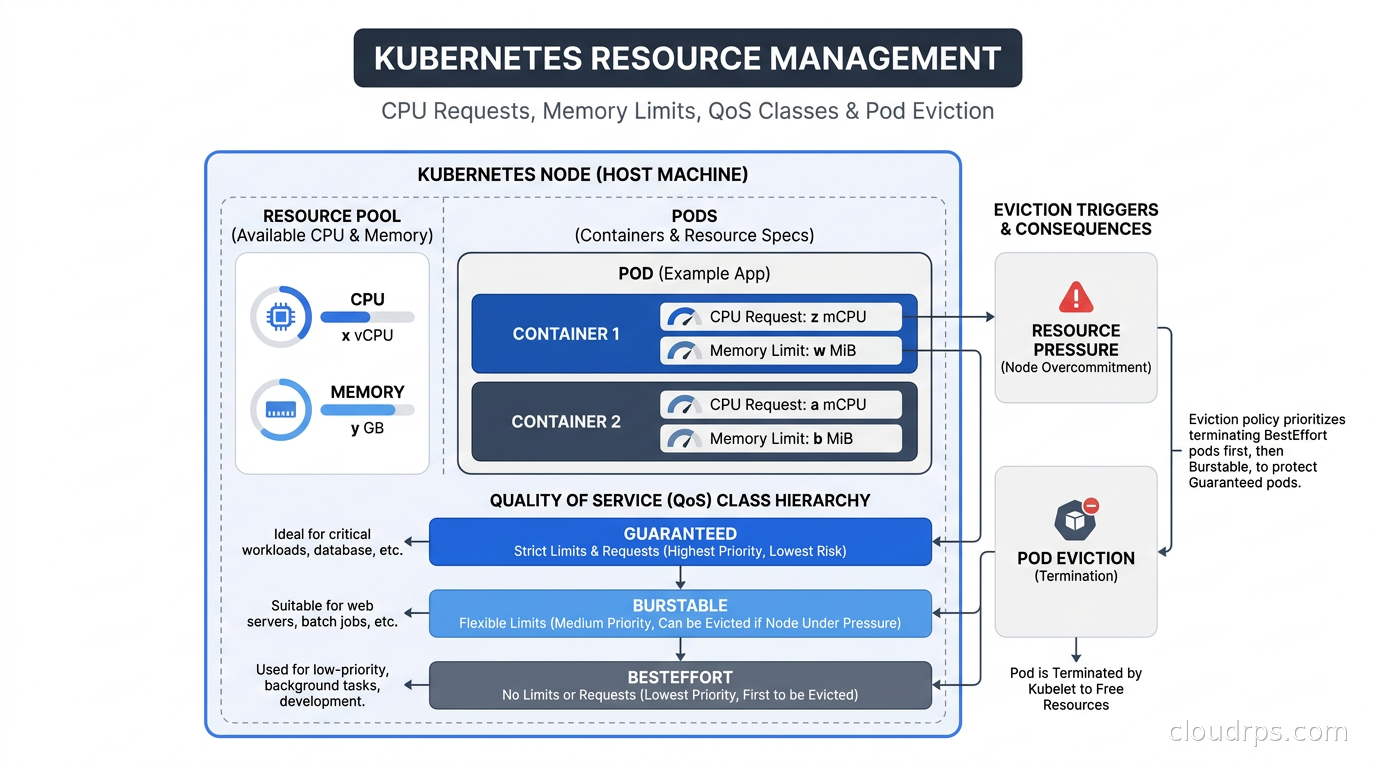
A deep dive into Kubernetes CPU requests, memory limits, QoS classes, LimitRange, and ResourceQuota. Learn why pods get OOMKilled and evicted, and how to right-size your workloads for reliable production clusters.
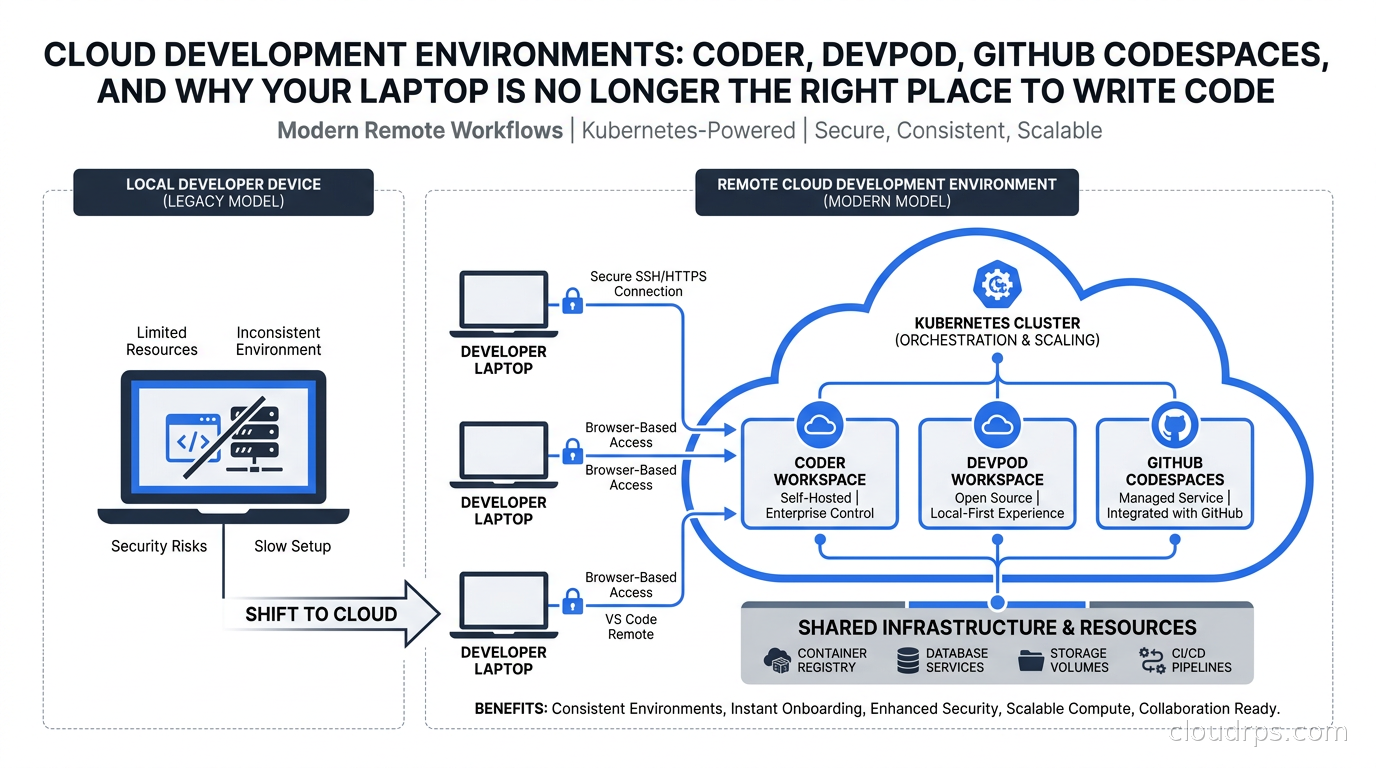
A hands-on guide to Cloud Development Environments (CDEs): how Coder, DevPod, GitHub Codespaces, and devcontainers work, when to adopt them, and why AI agents are making this the most important platform engineering decision of 2026.
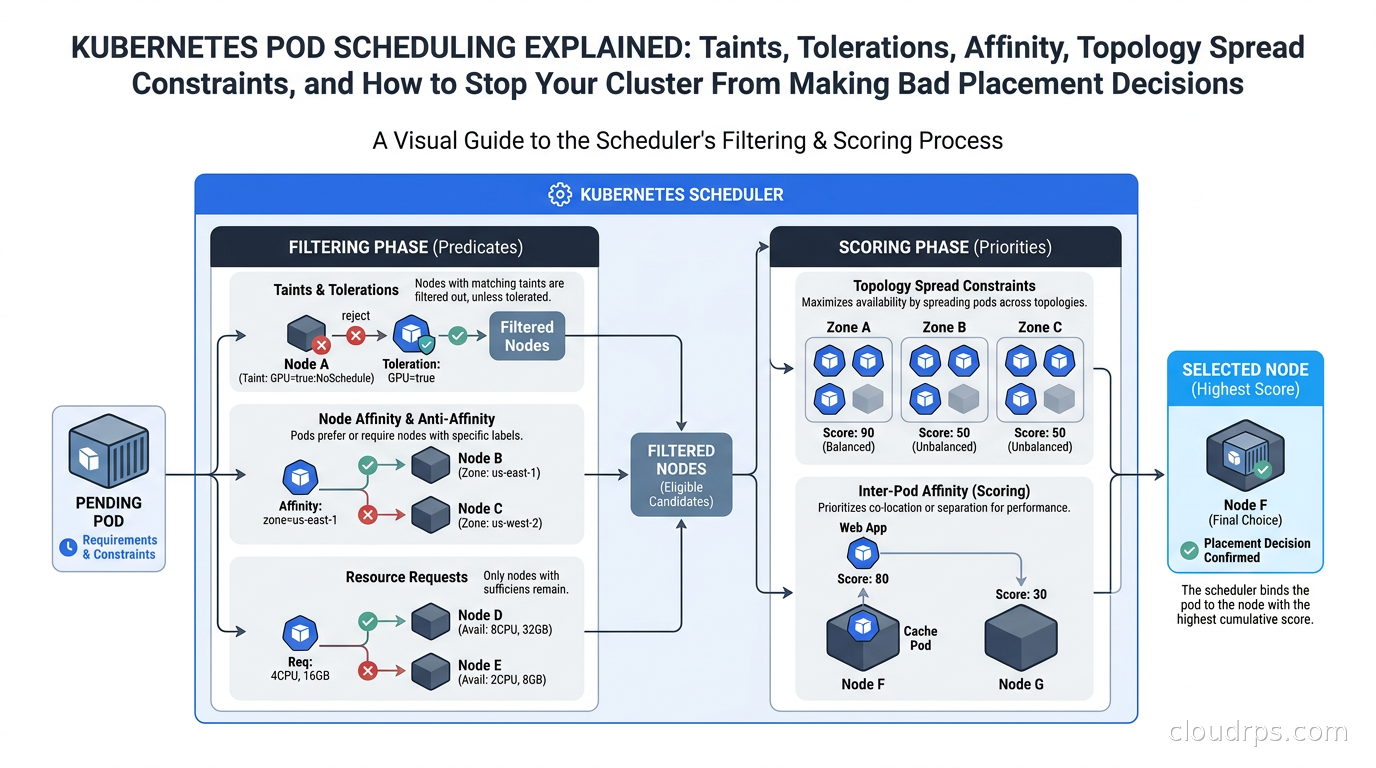
A deep dive into Kubernetes pod scheduling: how the scheduler works, when to use taints vs affinity, topology spread constraints for HA, PriorityClass for preemption, and the production patterns that actually matter.
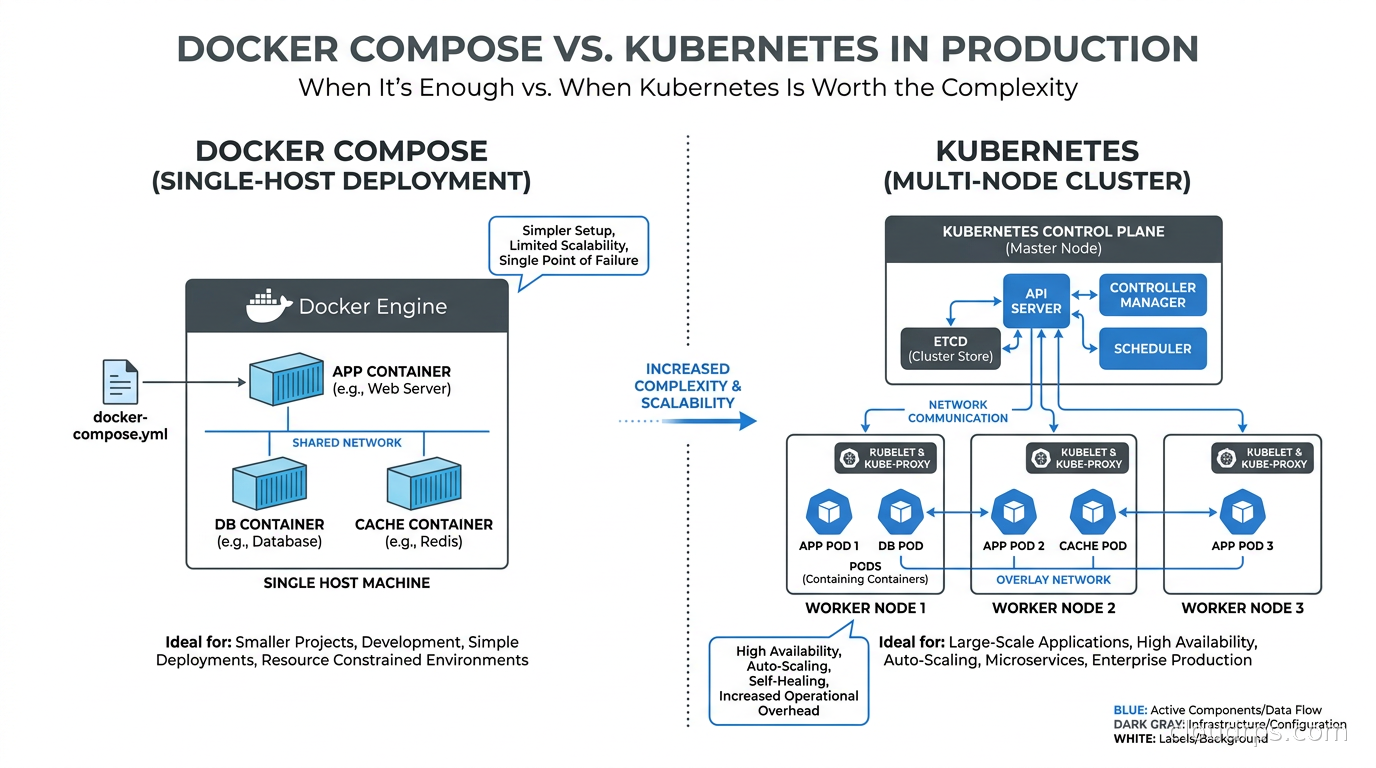
A principal cloud architect's honest take on when Docker Compose is the right production tool and when Kubernetes complexity is genuinely justified. Includes a decision framework, real failure modes, and migration signals.
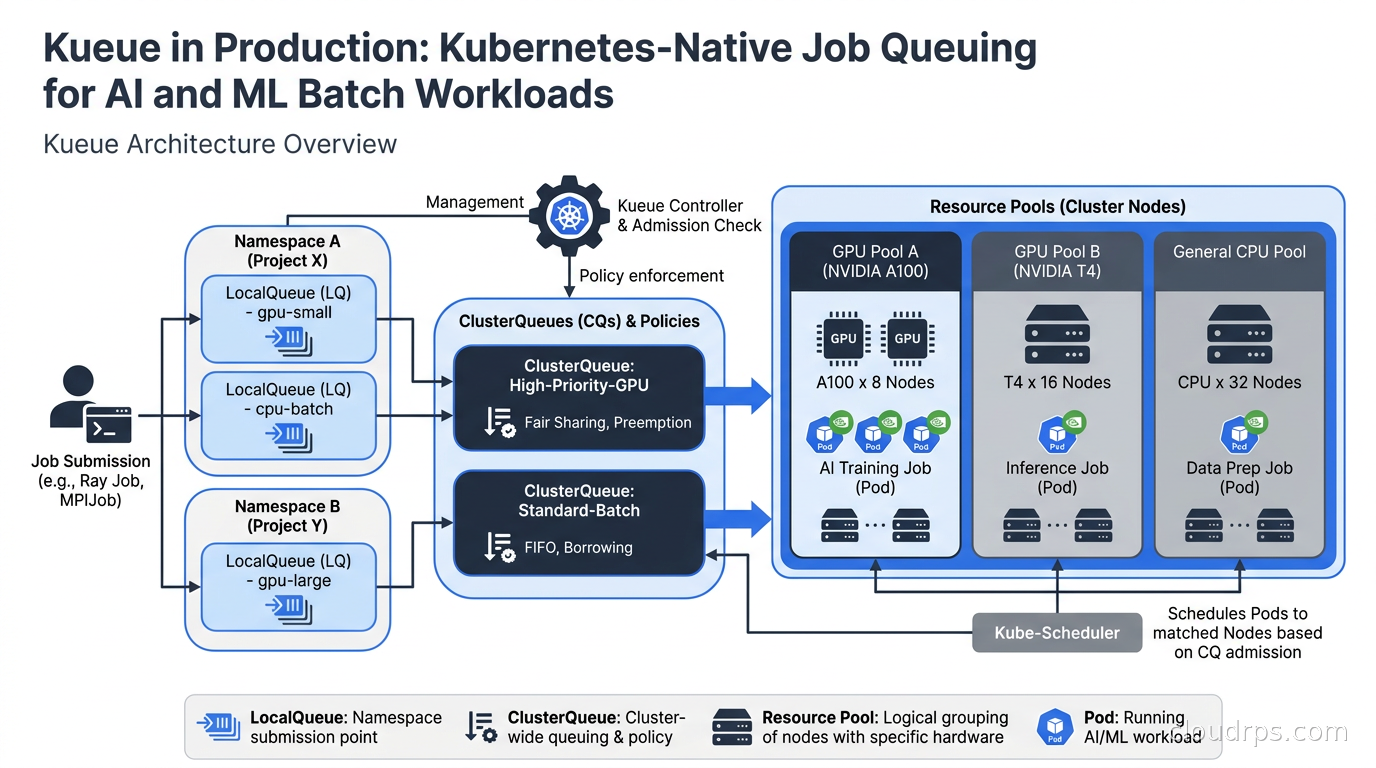
Kueue brings fair-share GPU scheduling, gang scheduling, and quota enforcement to Kubernetes AI workloads. Here is how to deploy it in production and stop wasting expensive GPUs.
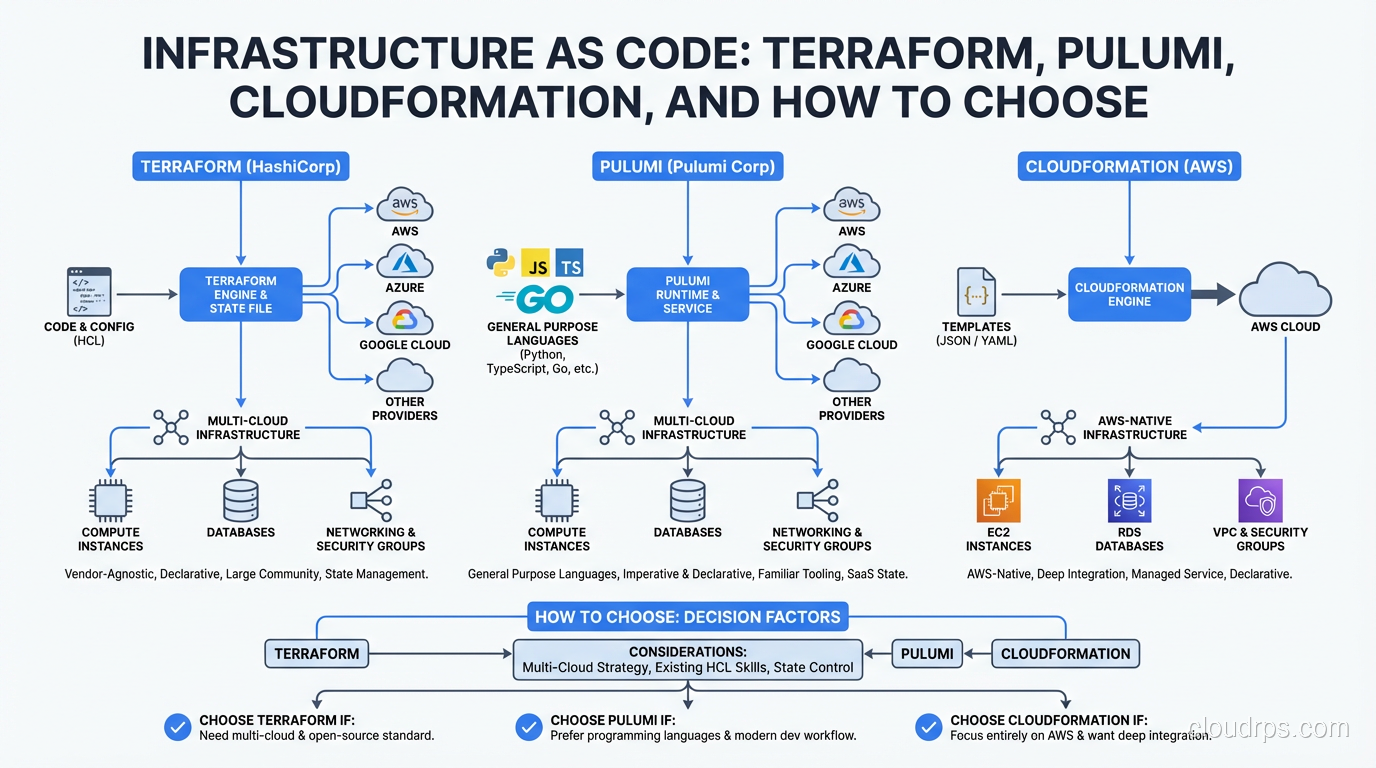
A practical guide to Infrastructure as Code tools. Compare Terraform, Pulumi, CloudFormation, and OpenTofu with real-world examples, trade-offs, and migration stories.
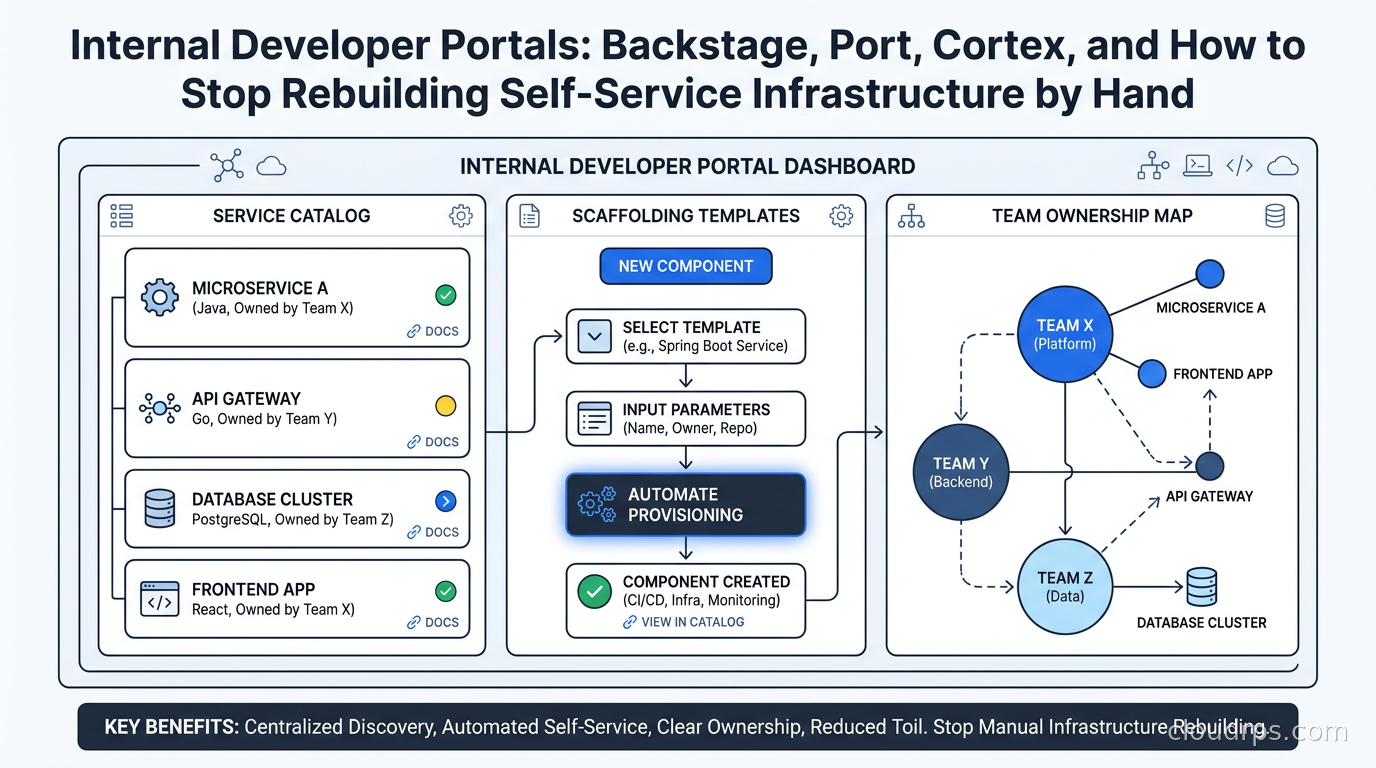
A principal cloud architect's guide to internal developer portals. Compare Backstage, Port, Cortex, and OpsLevel — and learn how to actually get engineers to use one.
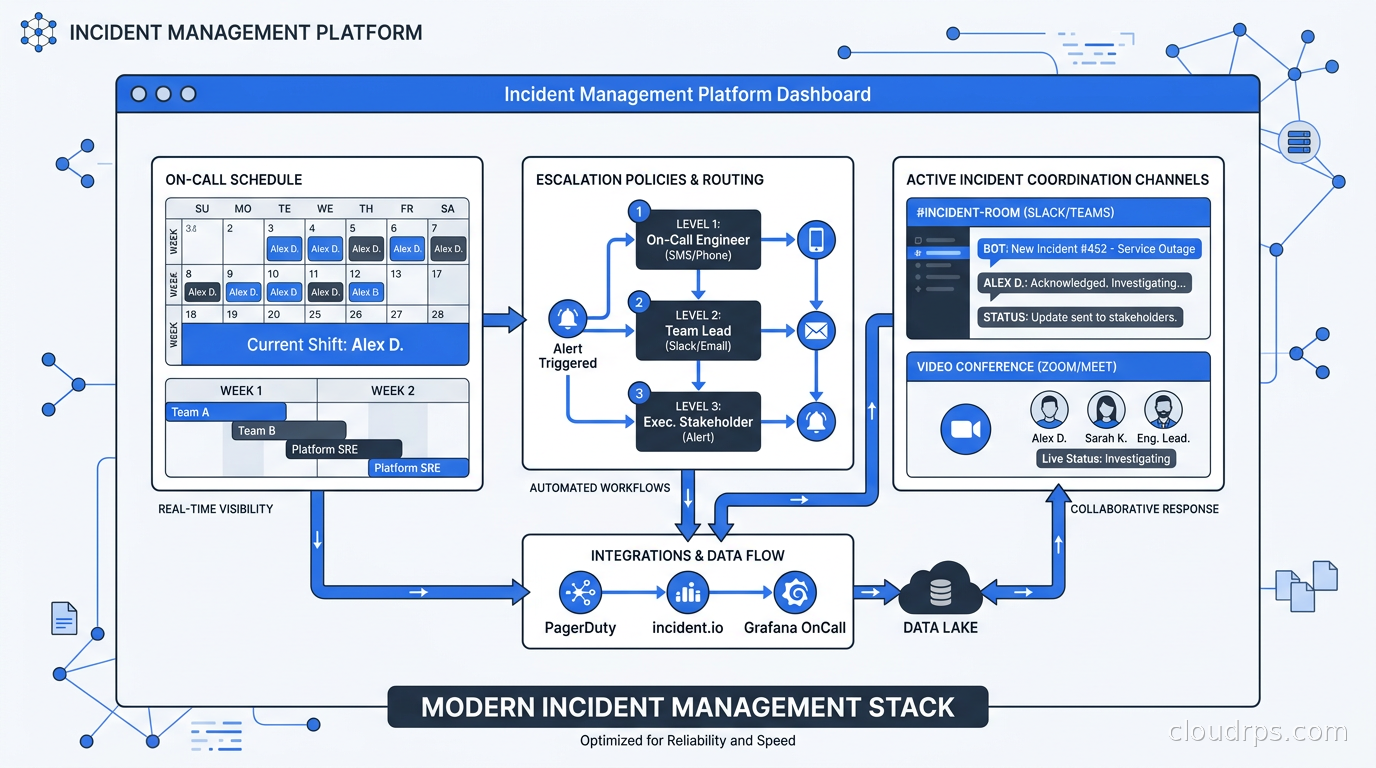
Opsgenie is shutting down in April 2027. Here is a practical guide to modern incident management platforms, on-call design, and choosing between PagerDuty, incident.io, and Grafana OnCall before you are forced to decide under a deadline.
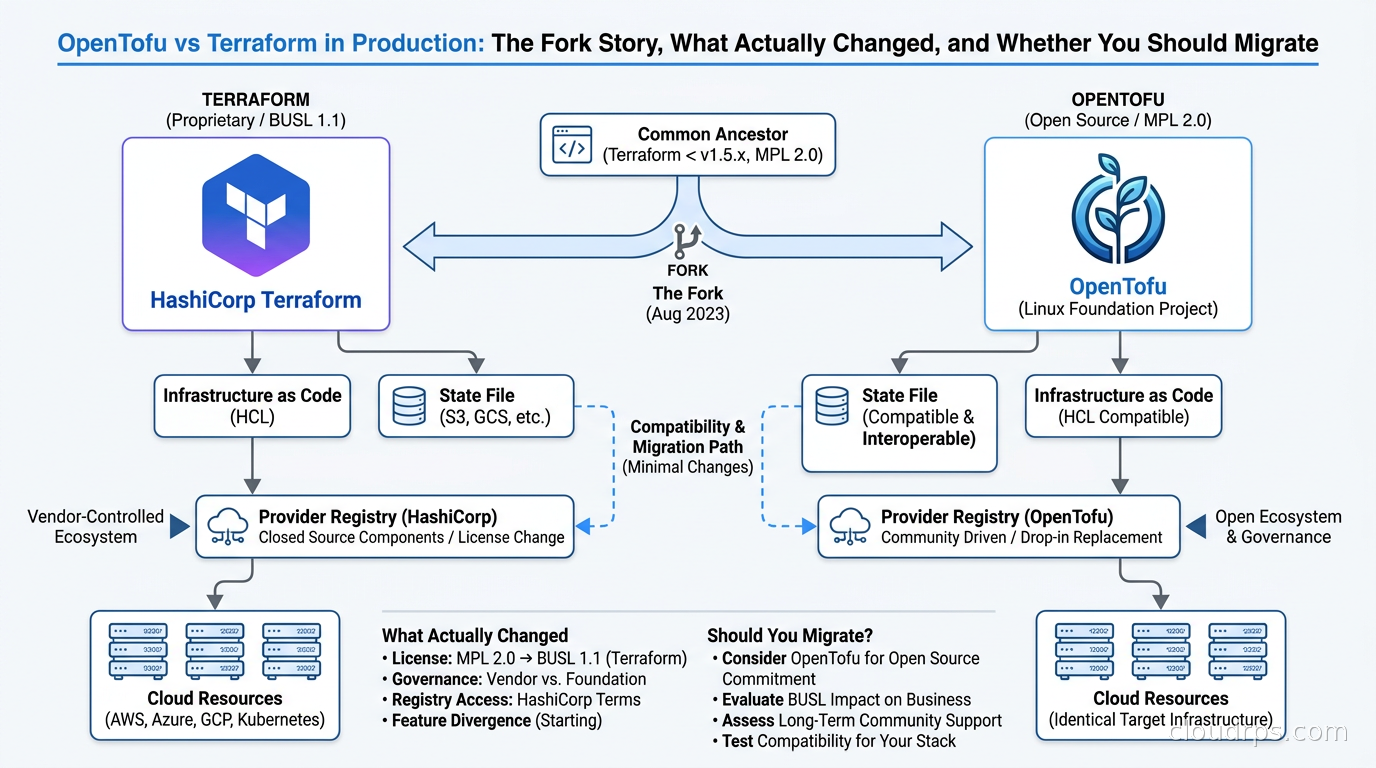
HashiCorp's 2023 license change triggered the biggest fork in IaC history. Here's what OpenTofu has shipped, who's adopted it, and how to decide if migration makes sense for your team.
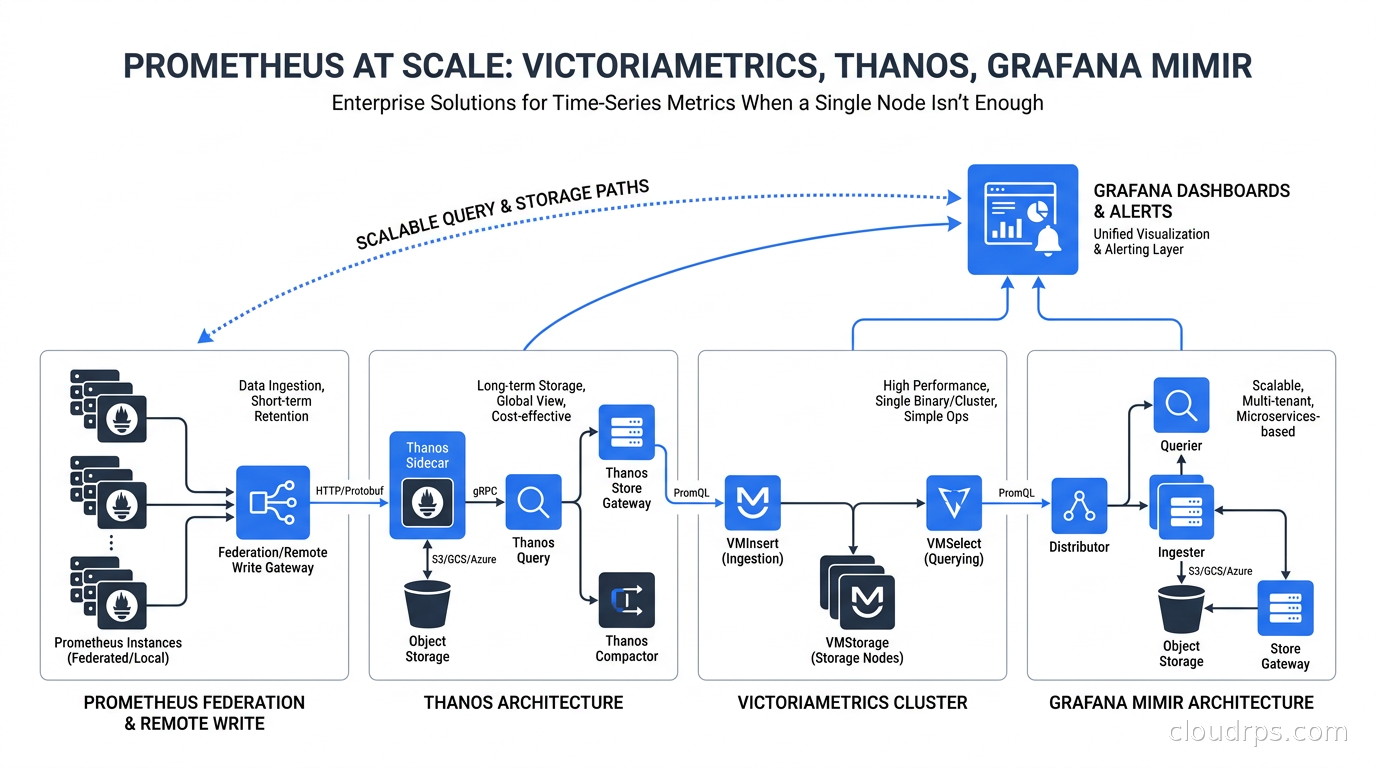
Single-node Prometheus breaks down at scale. Here's how VictoriaMetrics, Thanos, and Grafana Mimir solve long-term storage, high availability, and multi-cluster metrics at petabyte scale.
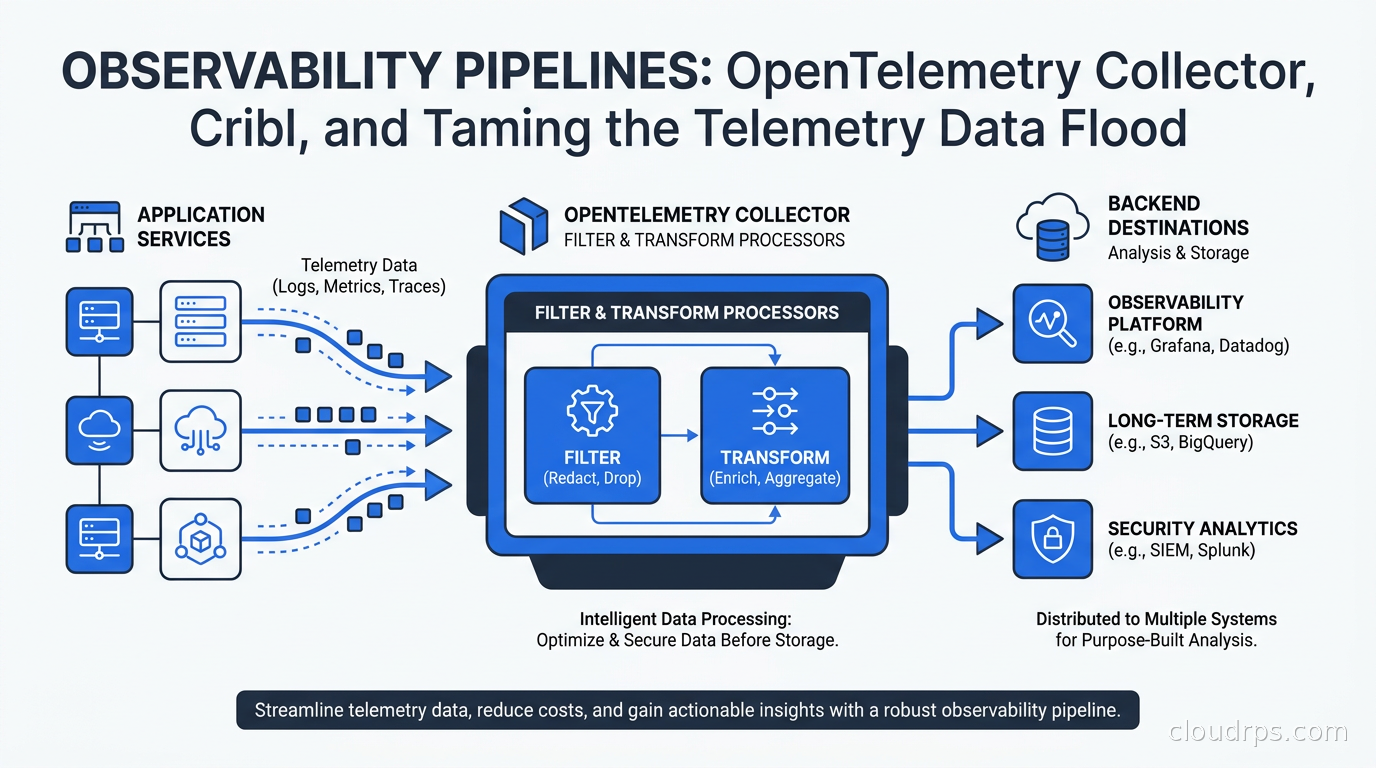
How to build observability pipelines with the OpenTelemetry Collector, Cribl, and Vector to cut telemetry costs 60-80% without losing diagnostic visibility.
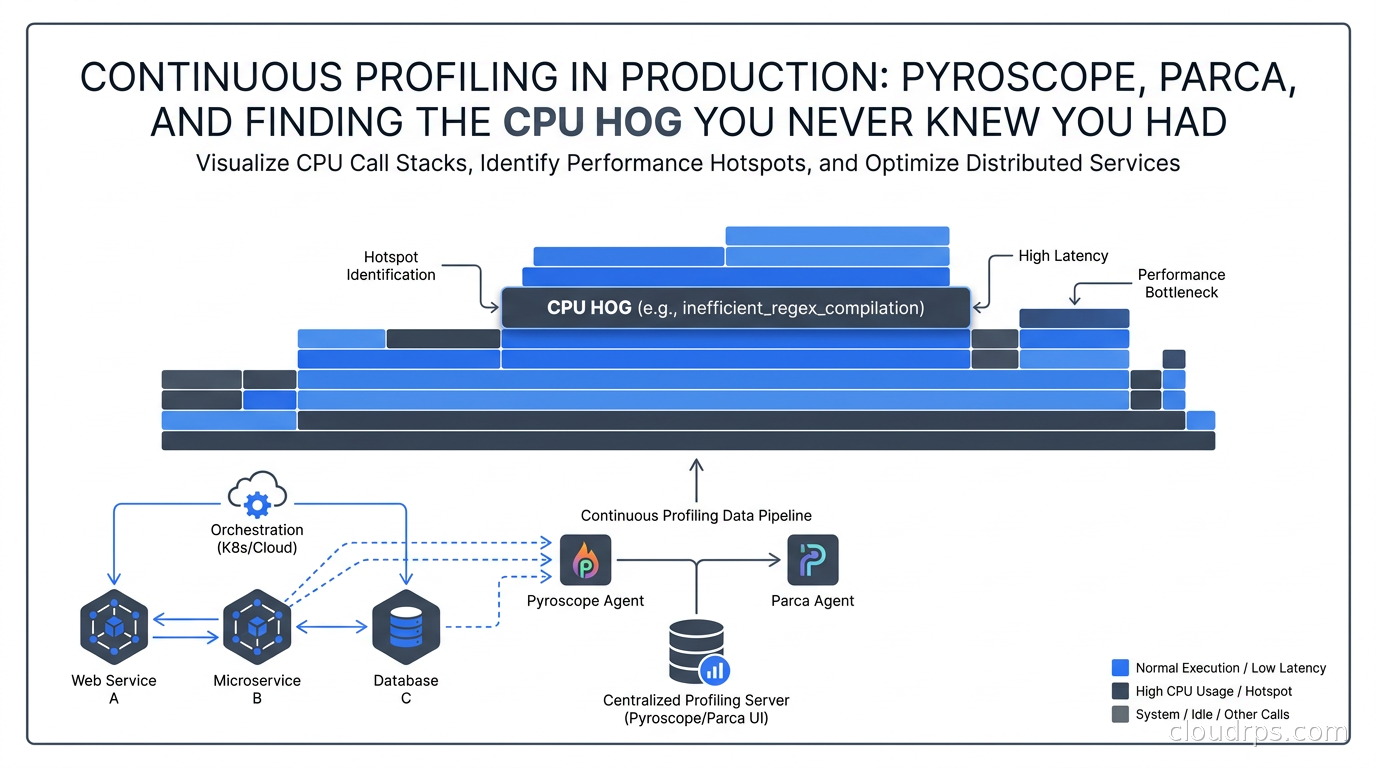
Continuous profiling is the fourth pillar of observability most teams skip. Learn how Pyroscope, Parca, and eBPF-based profilers find CPU and memory bottlenecks that metrics and traces can't.
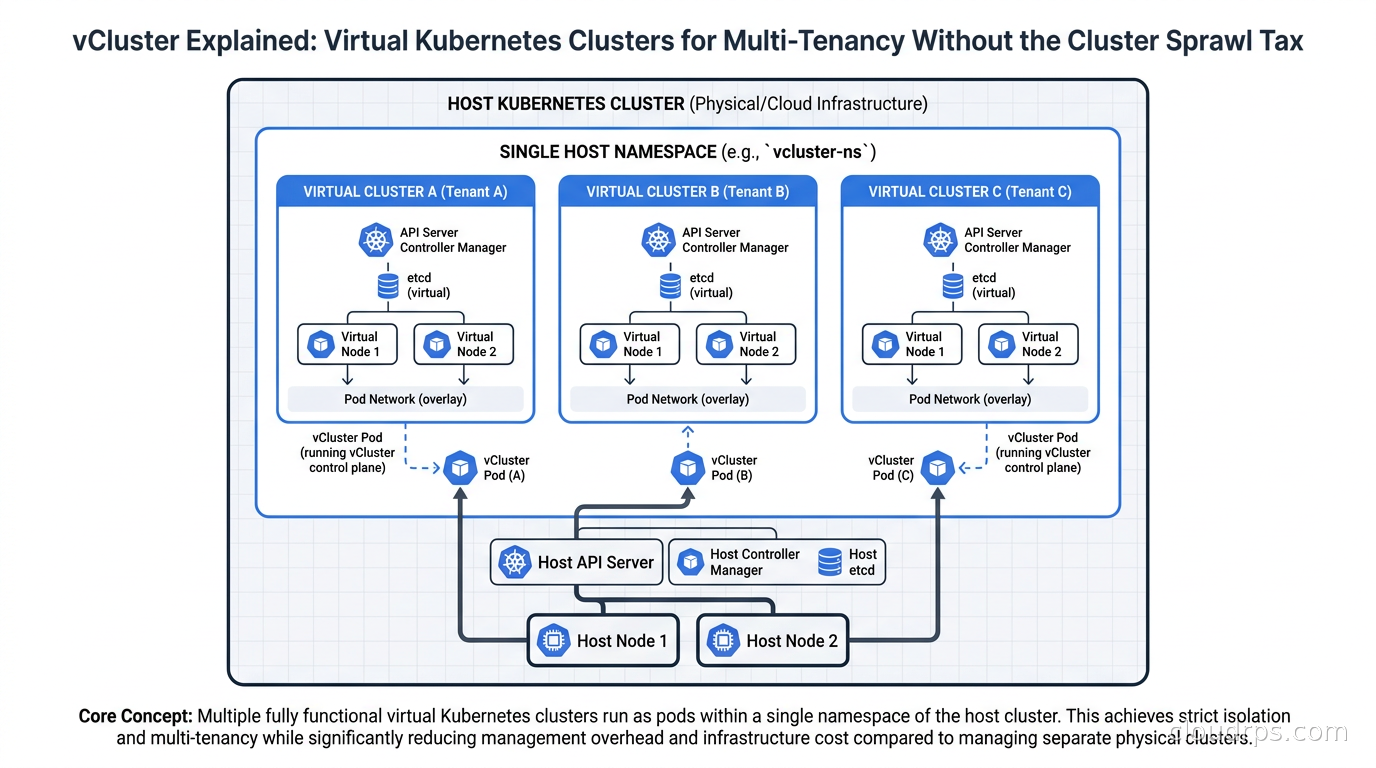
vCluster creates fully functional virtual Kubernetes clusters inside a single host cluster. Learn how it solves cluster sprawl, enables real multi-tenancy, and cuts costs by 60-80% compared to dedicated clusters per team.
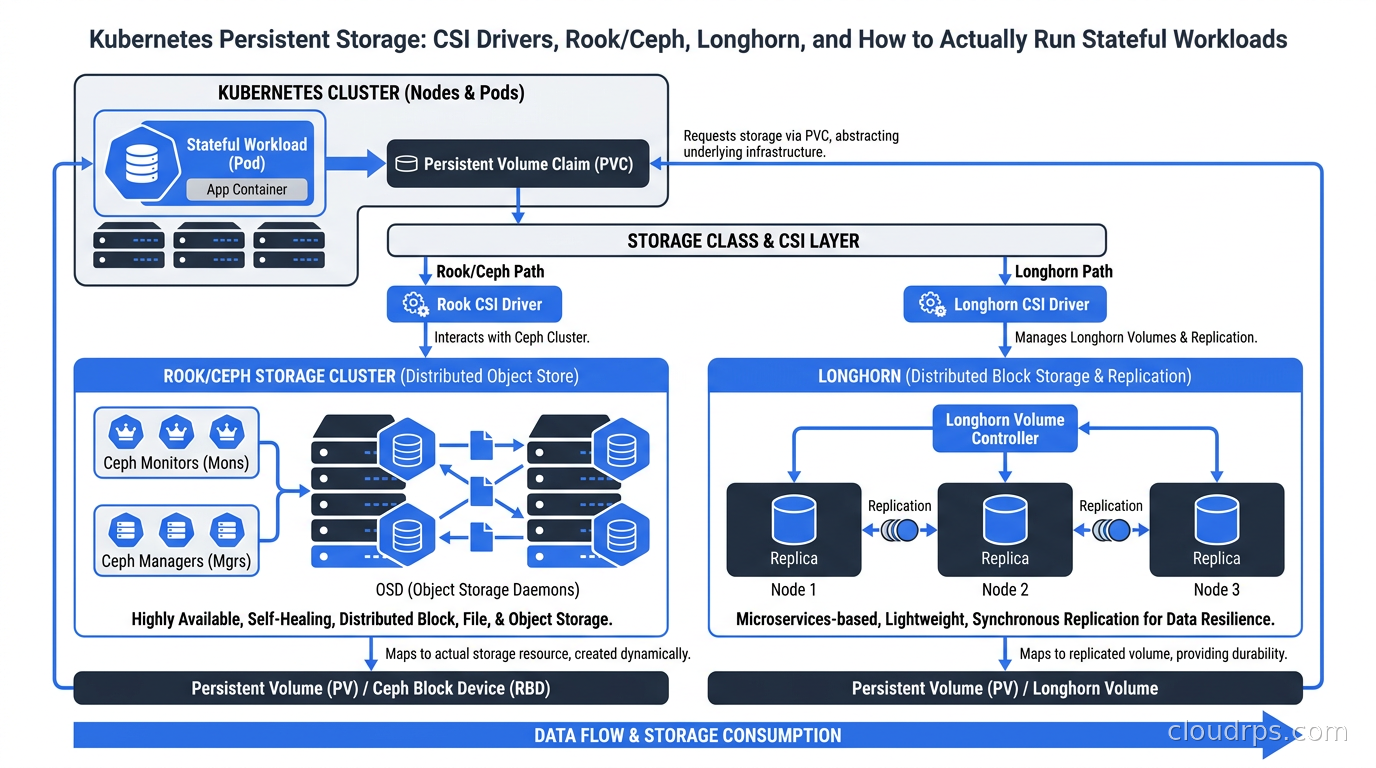
A deep dive into Kubernetes persistent storage: how CSI drivers work, when to use Rook/Ceph vs Longhorn vs cloud-native options, and the access mode traps that have broken more than one production migration.
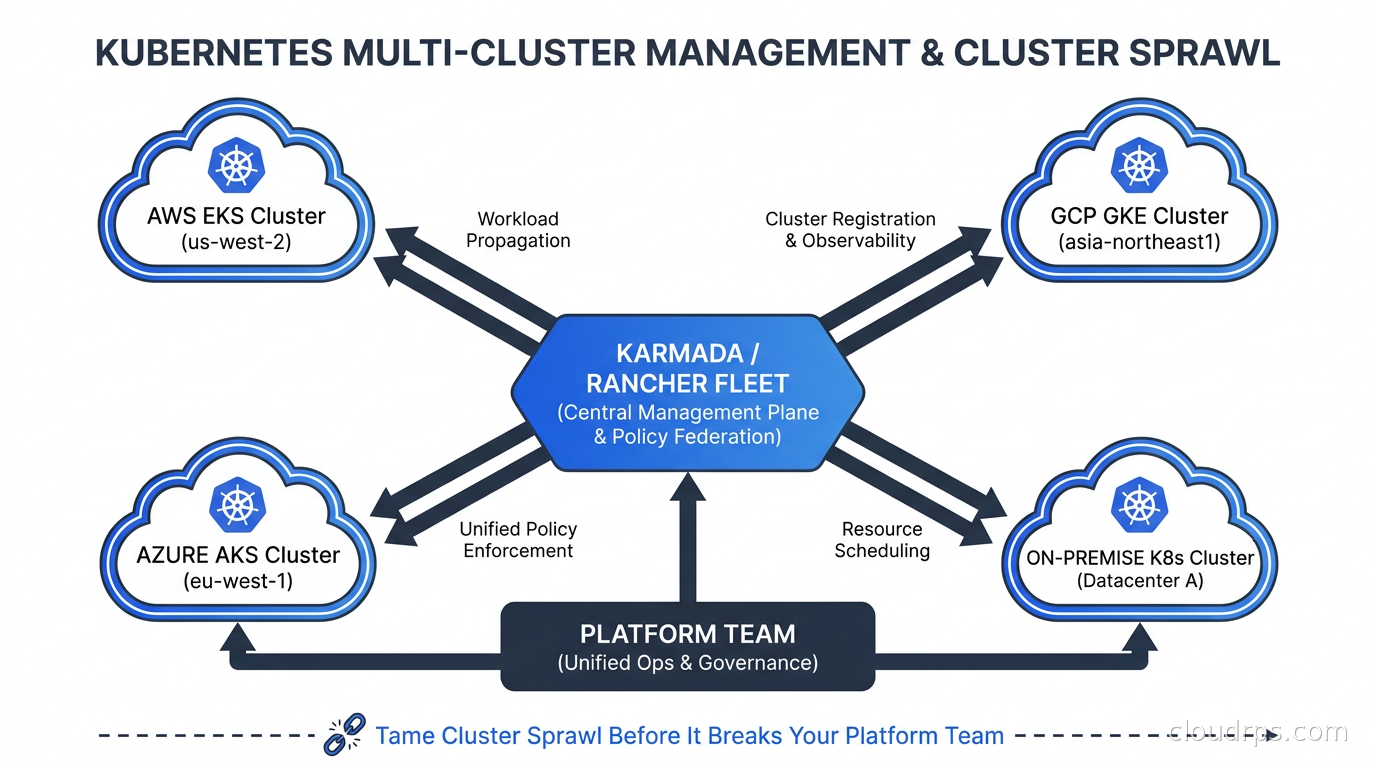
A principal cloud architect's guide to managing fleets of Kubernetes clusters. Covers Karmada, Rancher Fleet, Open Cluster Management, ArgoCD ApplicationSets, policy federation, and the economics of cluster sprawl.
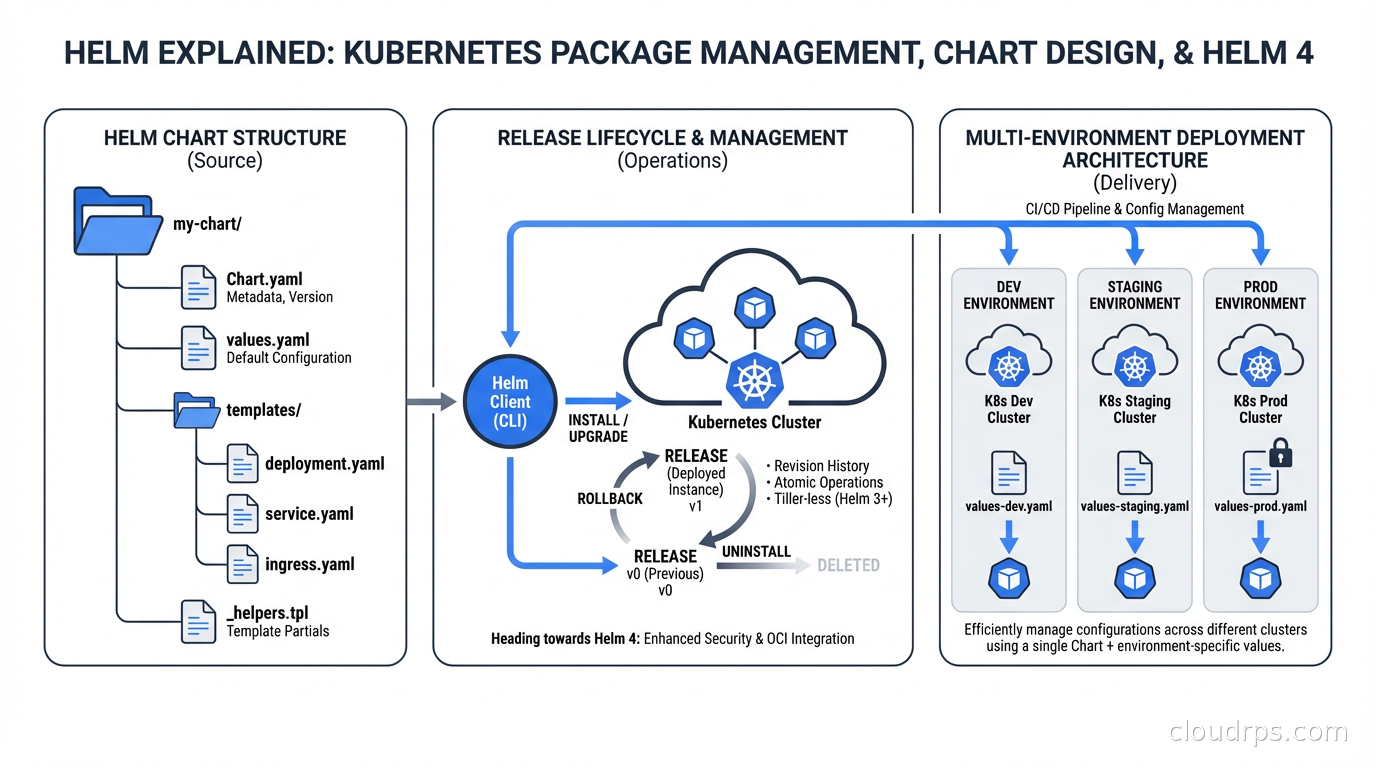
A practical guide to Helm, the de facto Kubernetes package manager: core concepts, chart design patterns, Helmfile for multi-environment management, and what Helm 4's server-side apply changes for your production clusters.
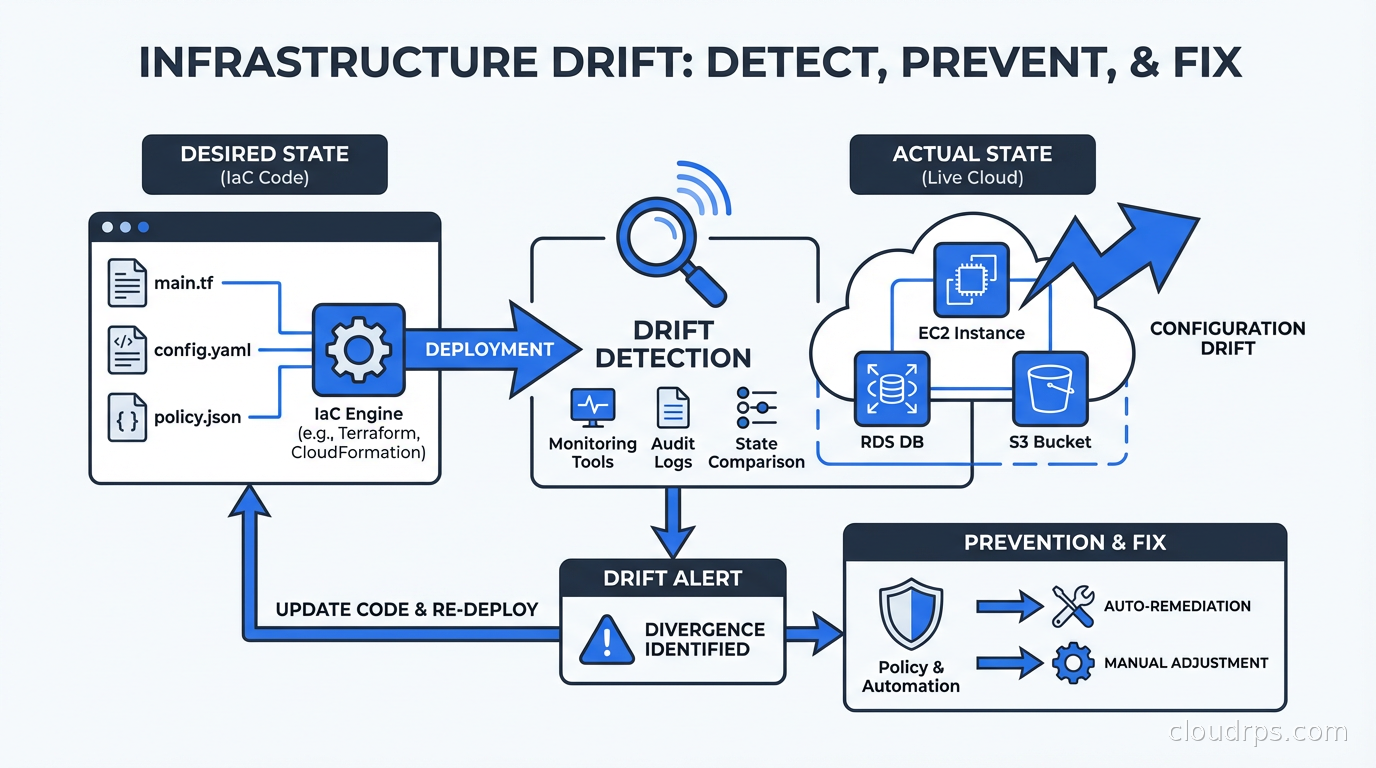
Infrastructure drift is when your live cloud environment diverges from your IaC definitions. Learn how it happens, how to detect it with Terraform and GitOps tools, and how to fix it before it causes an incident.
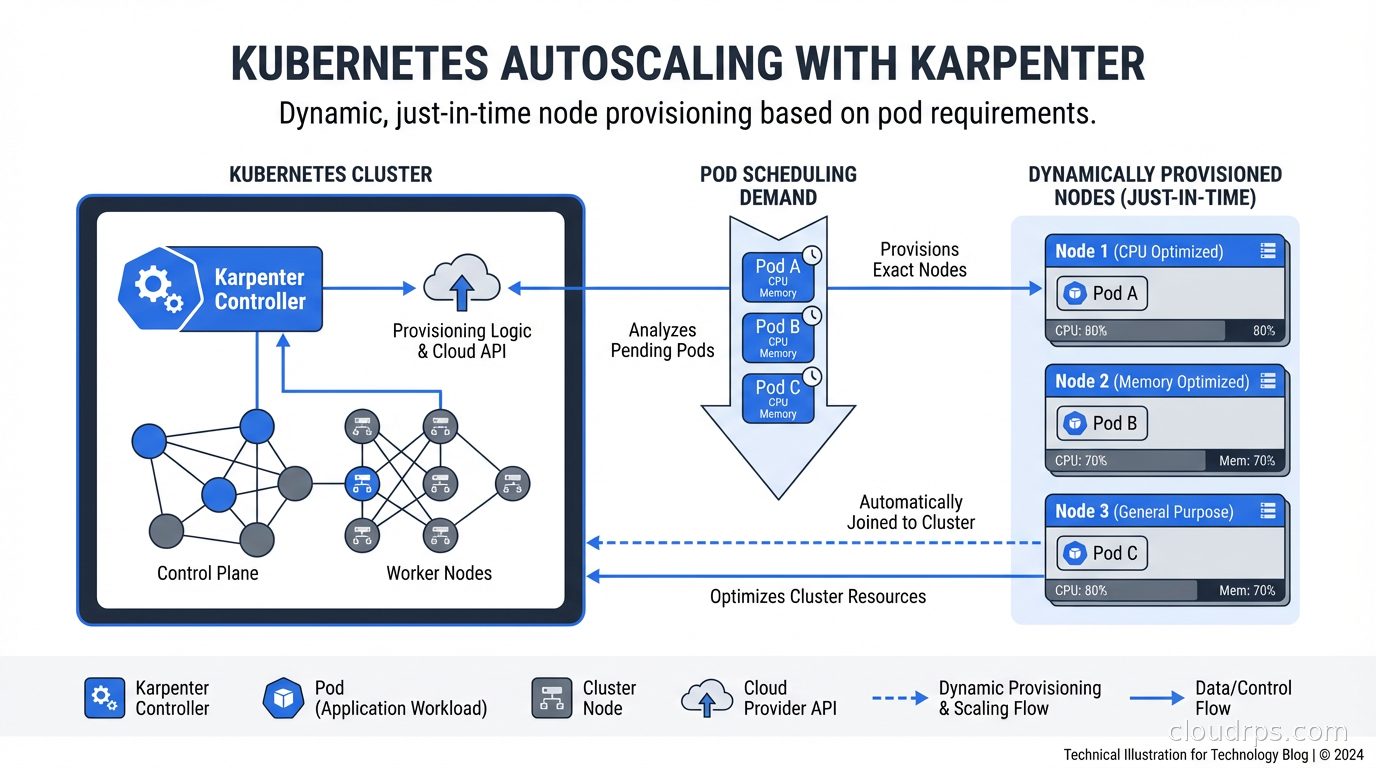
Karpenter replaces the Kubernetes Cluster Autoscaler with a faster, smarter node provisioner that cuts costs and response time. Here's how it works and why it matters.
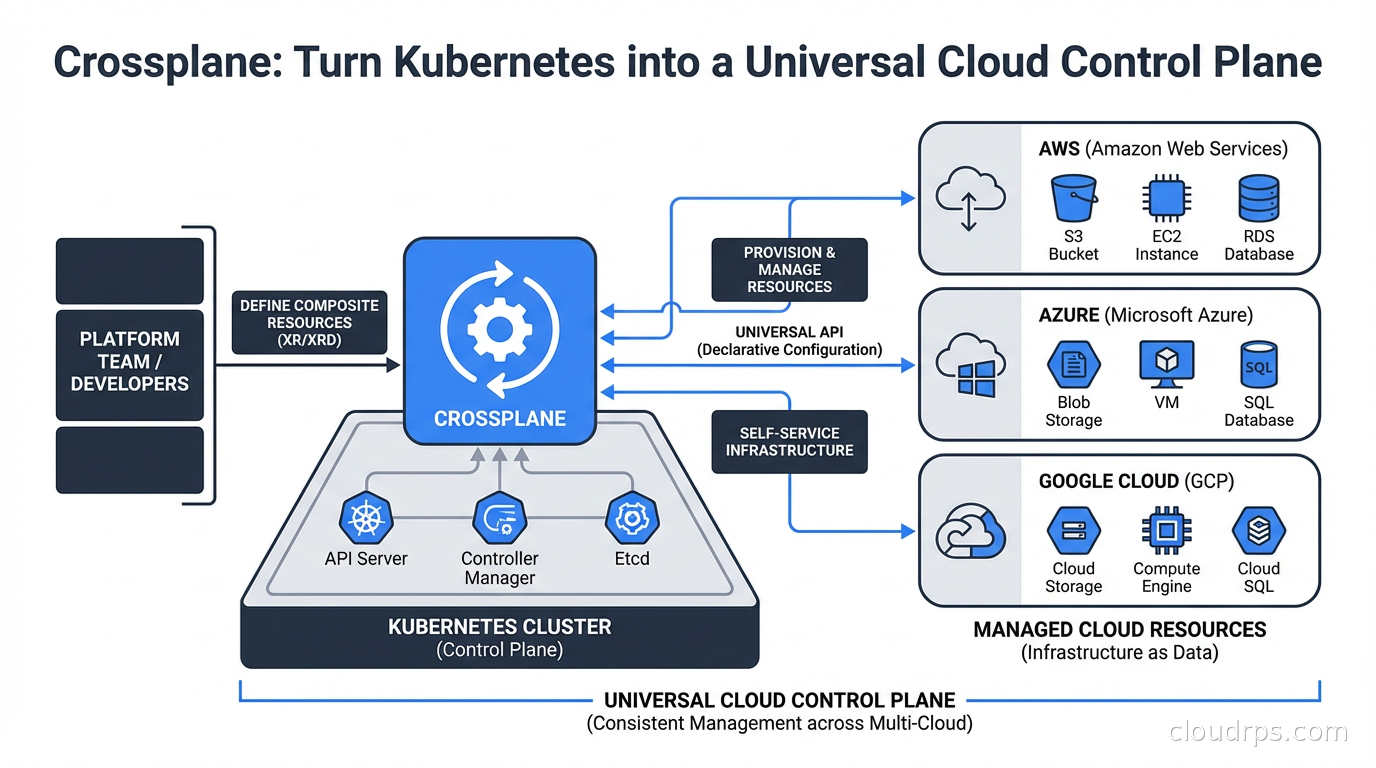
Crossplane transforms Kubernetes into a universal cloud control plane, letting platform teams build self-service infrastructure APIs without writing custom operators. Here's how it works, where it beats Terraform, and when to skip it.
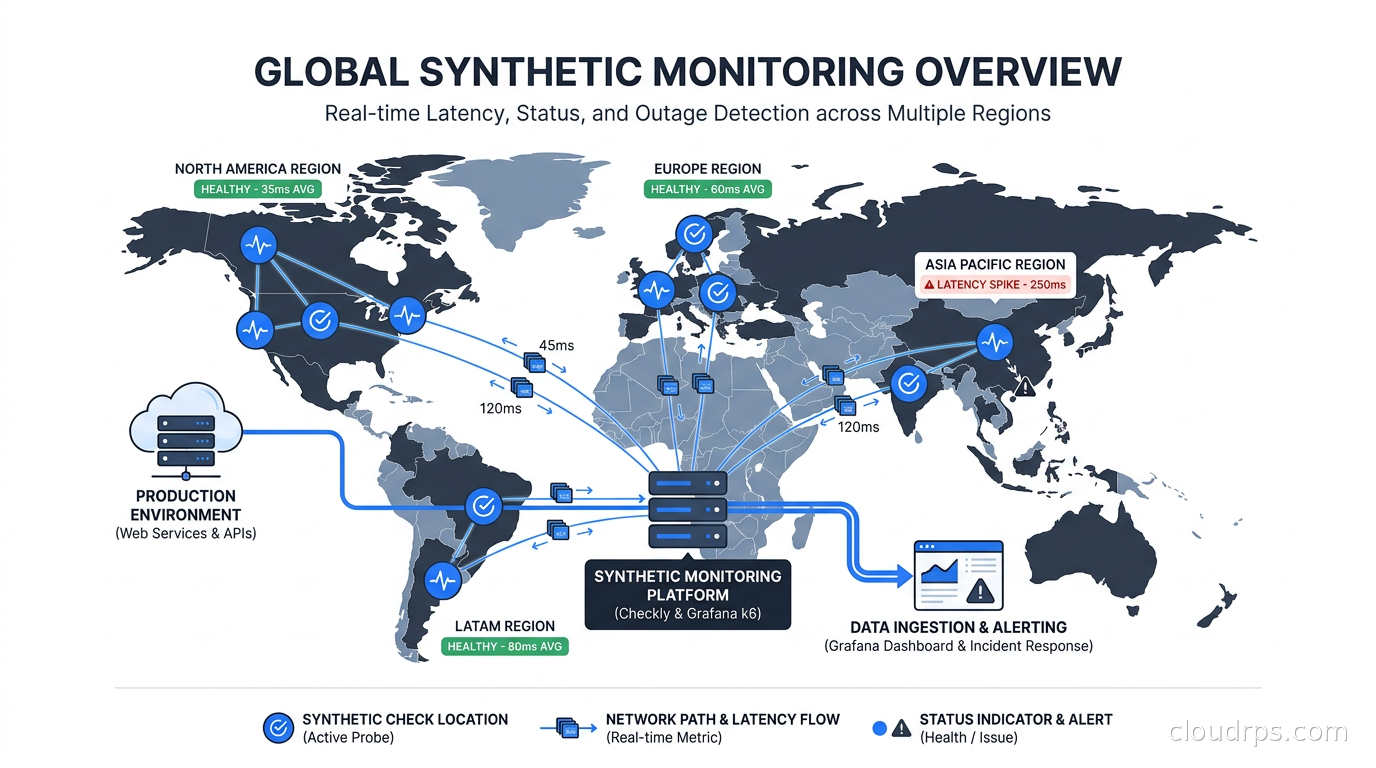
Synthetic monitoring lets you detect outages before users do. Learn how to build production-grade checks with Checkly and Grafana k6, integrate them with your SLOs, and stop finding out about failures from support tickets.
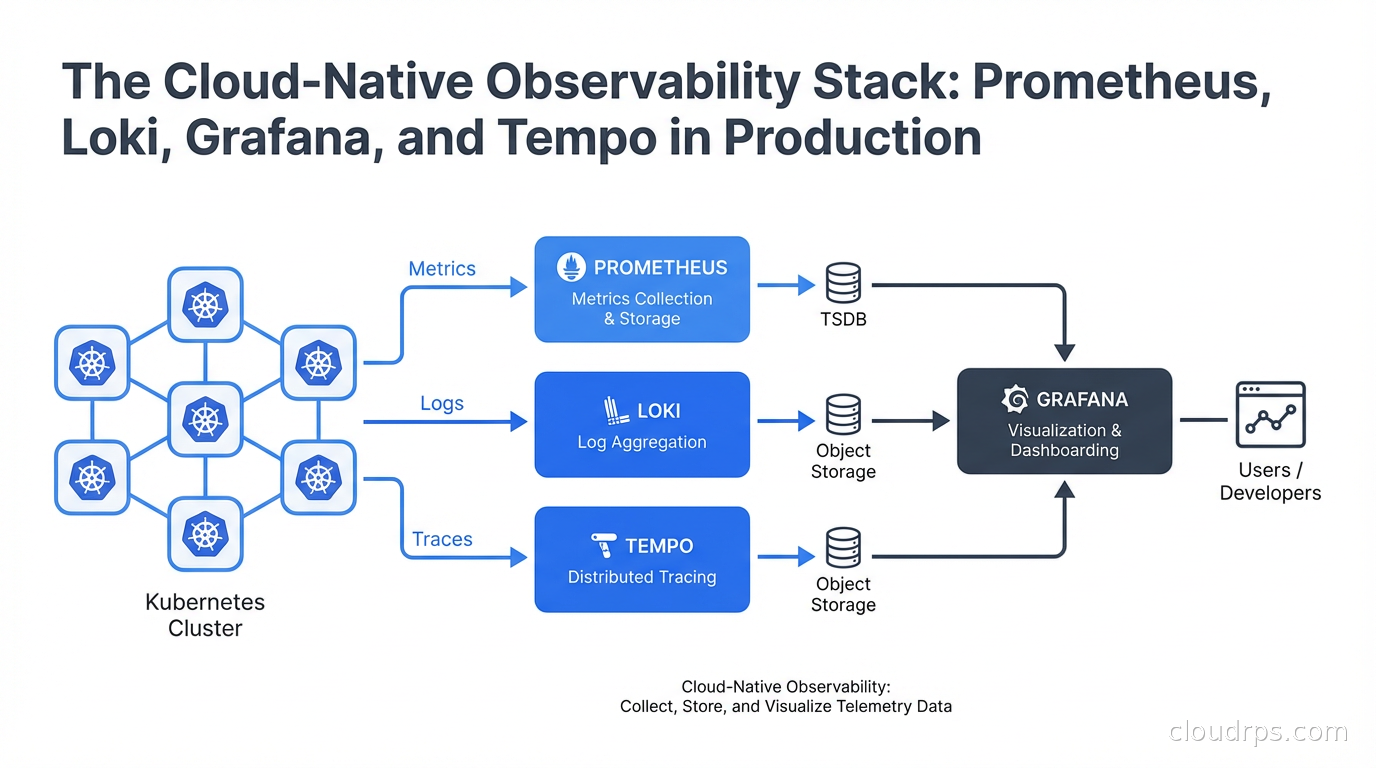
A deep-dive into building a production-grade observability stack with Prometheus, Loki, Grafana, and Tempo. Learn the architecture, scaling trade-offs, cardinality traps, and when the open-source stack beats a $40k/month SaaS bill.

DORA's four key metrics (deployment frequency, lead time, MTTR, change failure rate) are the clearest signal we have for engineering team performance. Here's how to measure them, what they tell you, and how to avoid gaming them.
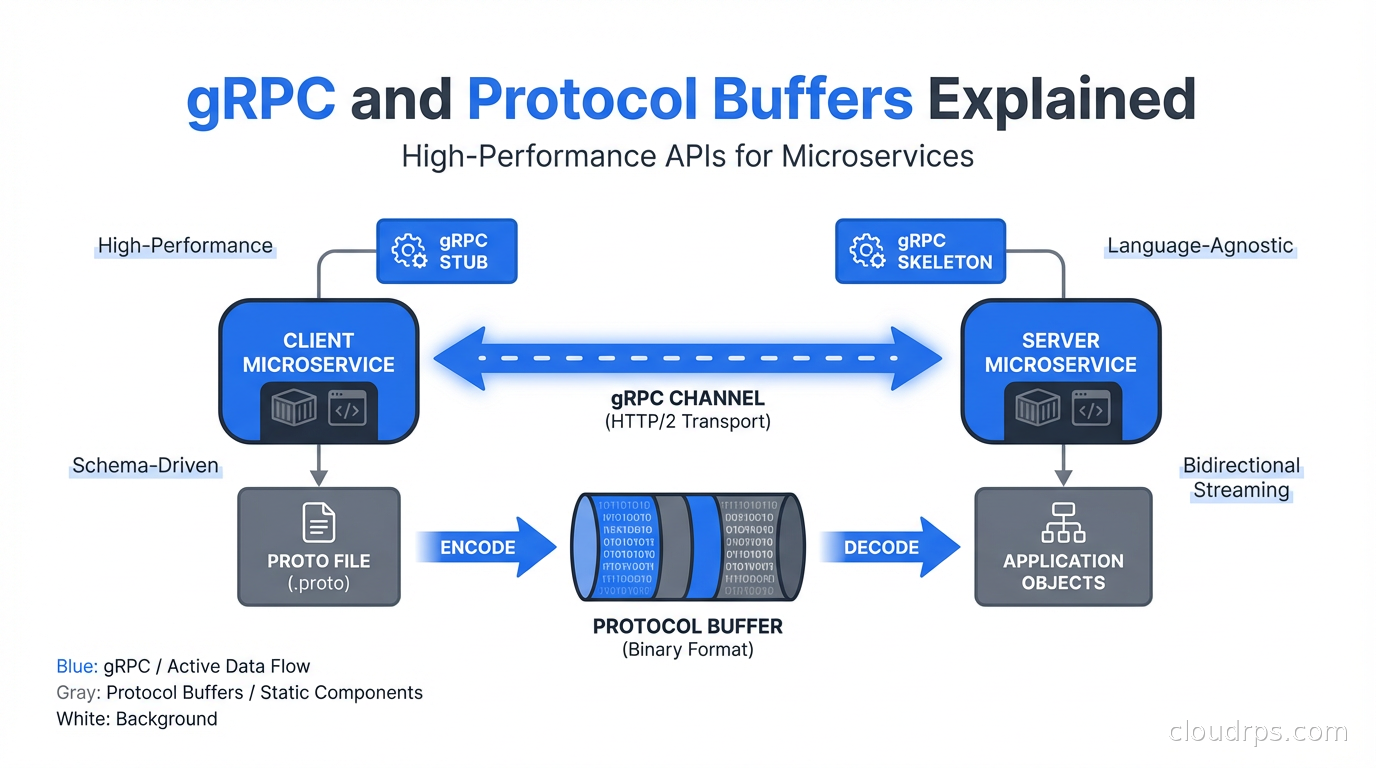
gRPC is not just 'faster REST'. It's a fundamentally different communication model that changes how you design APIs, handle streaming, and think about service contracts. Here's what you actually need to know.

Everything you need to know about Terraform state: how remote backends work, why state locking saves you from concurrent apply disasters, when to use workspaces versus separate state files, and patterns for managing state at scale across multiple teams.
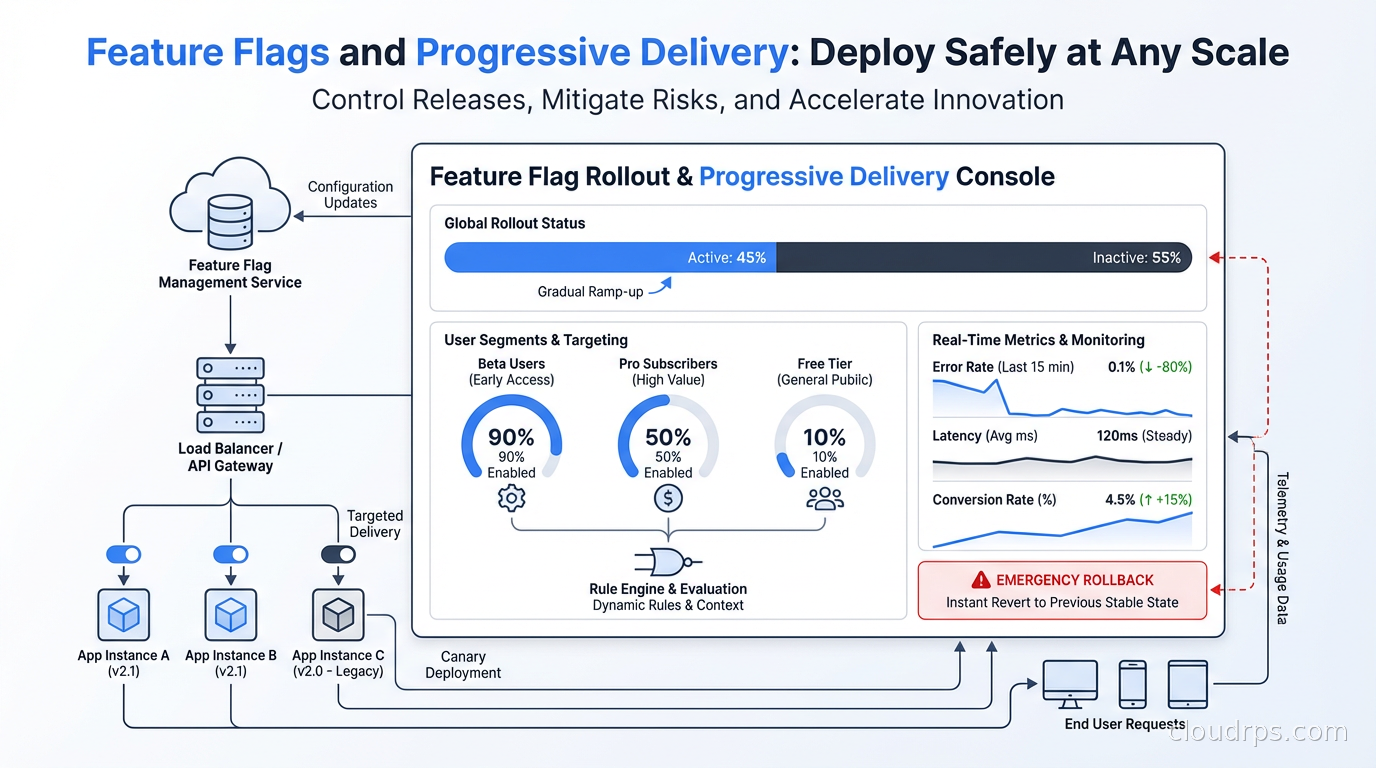
Feature flags decouple deployment from release. Progressive delivery uses them to roll out features safely to 1% of users before 100%. Here's the architecture and tooling that makes it work.
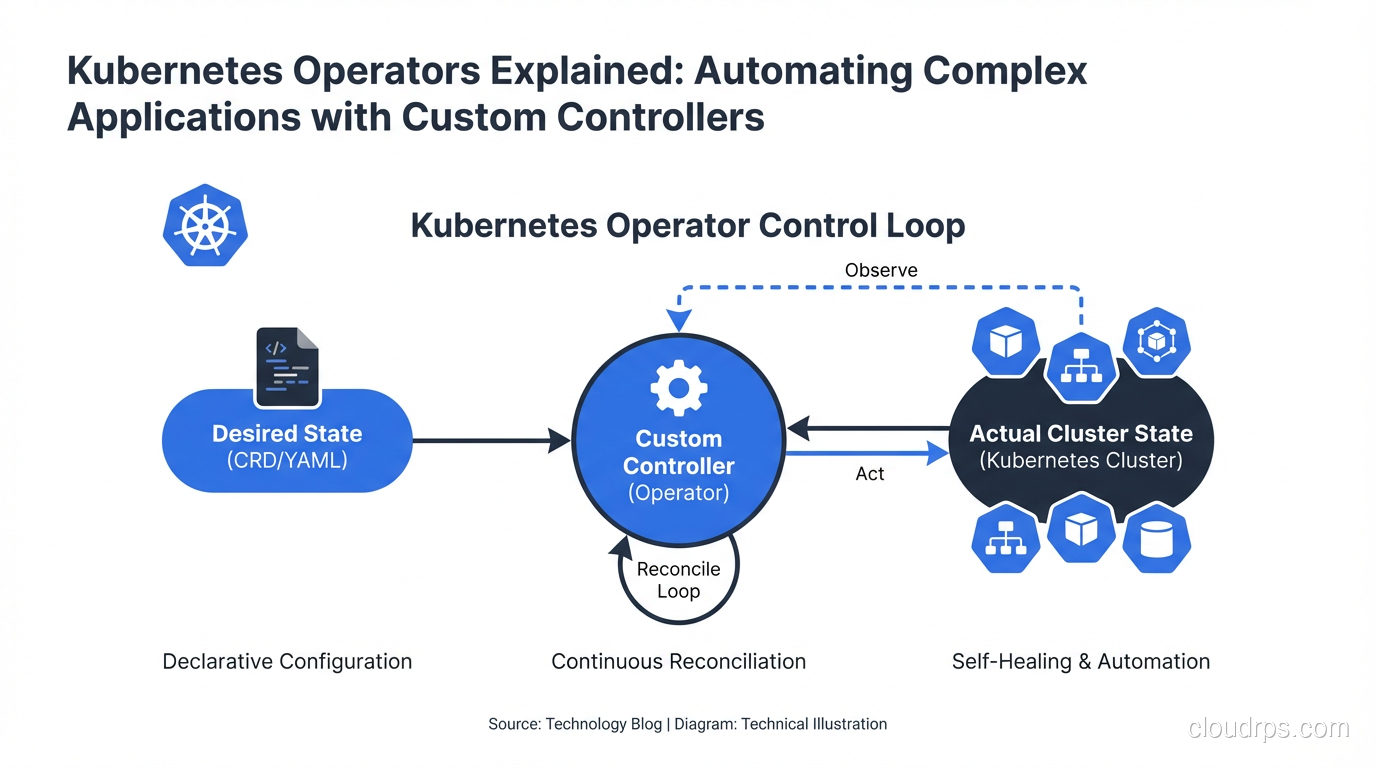
Kubernetes Operators encode operational knowledge into software. Here's how they work, when to write one, and when to use an existing operator instead of building your own.
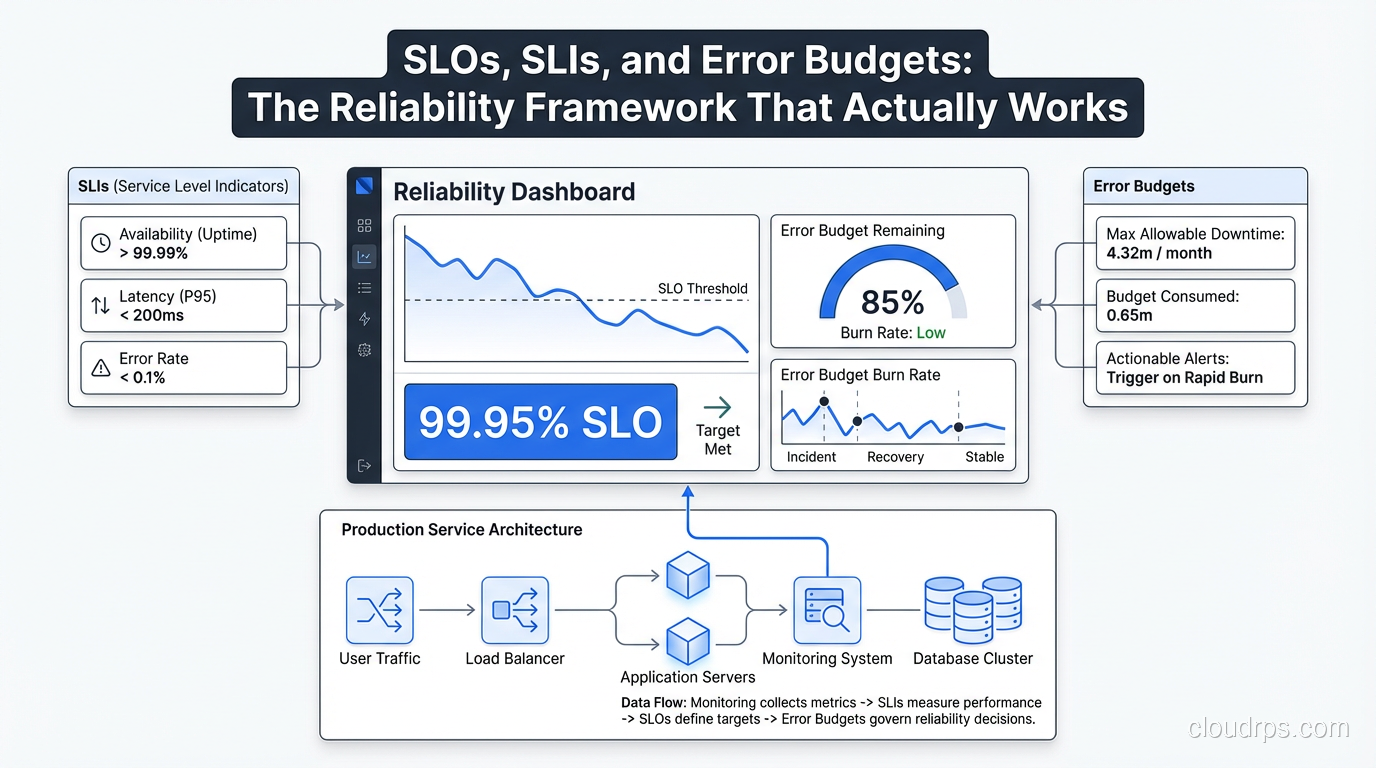
SLAs are for lawyers. SLOs are for engineers. Here's how to define meaningful service level objectives, measure them properly, and use error budgets to make smarter deployment decisions.
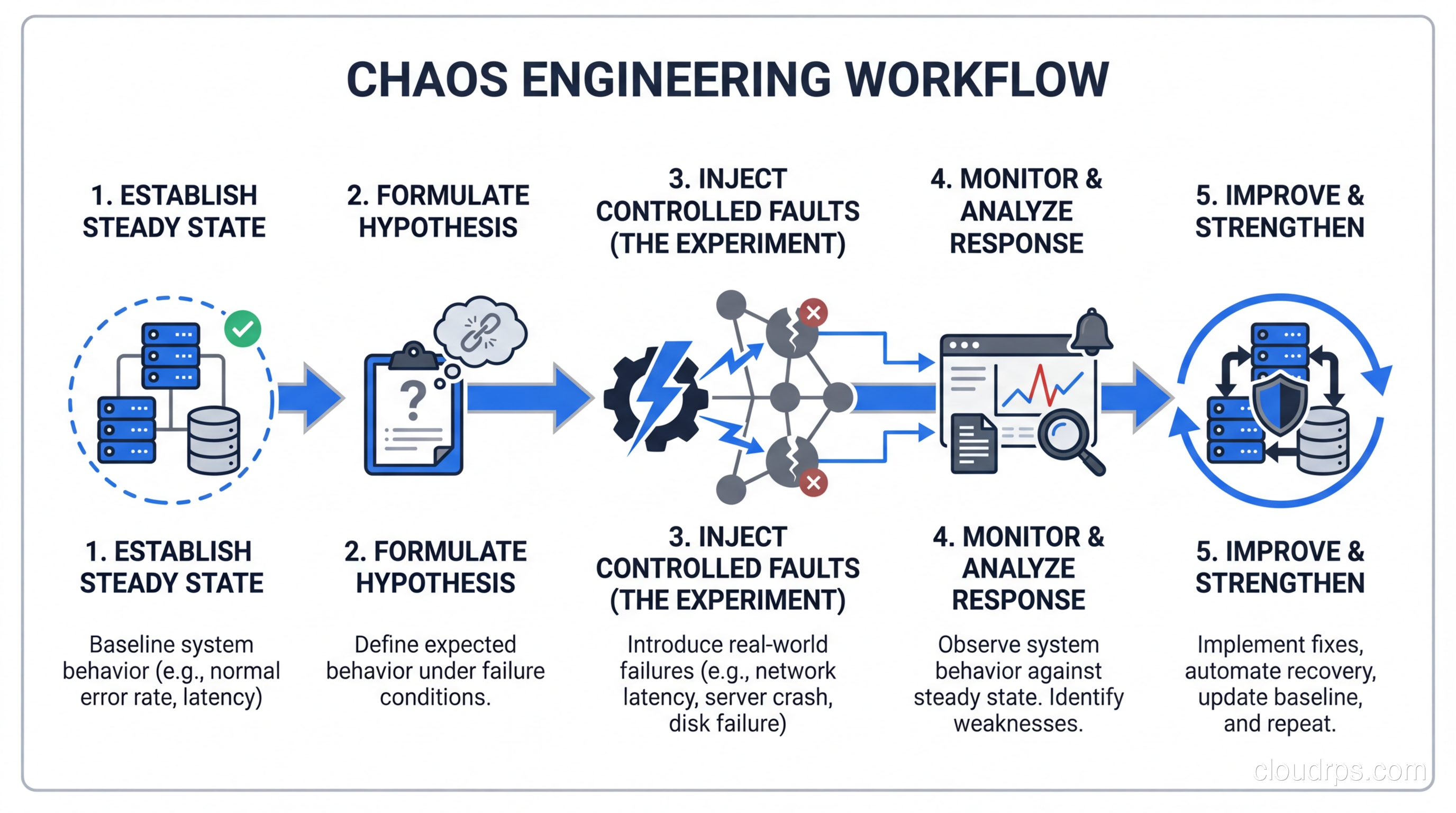
A hands-on guide to chaos engineering: why you should break things in production, tools like Chaos Monkey and Litmus, game day planning, and how to build a culture of resilience testing.
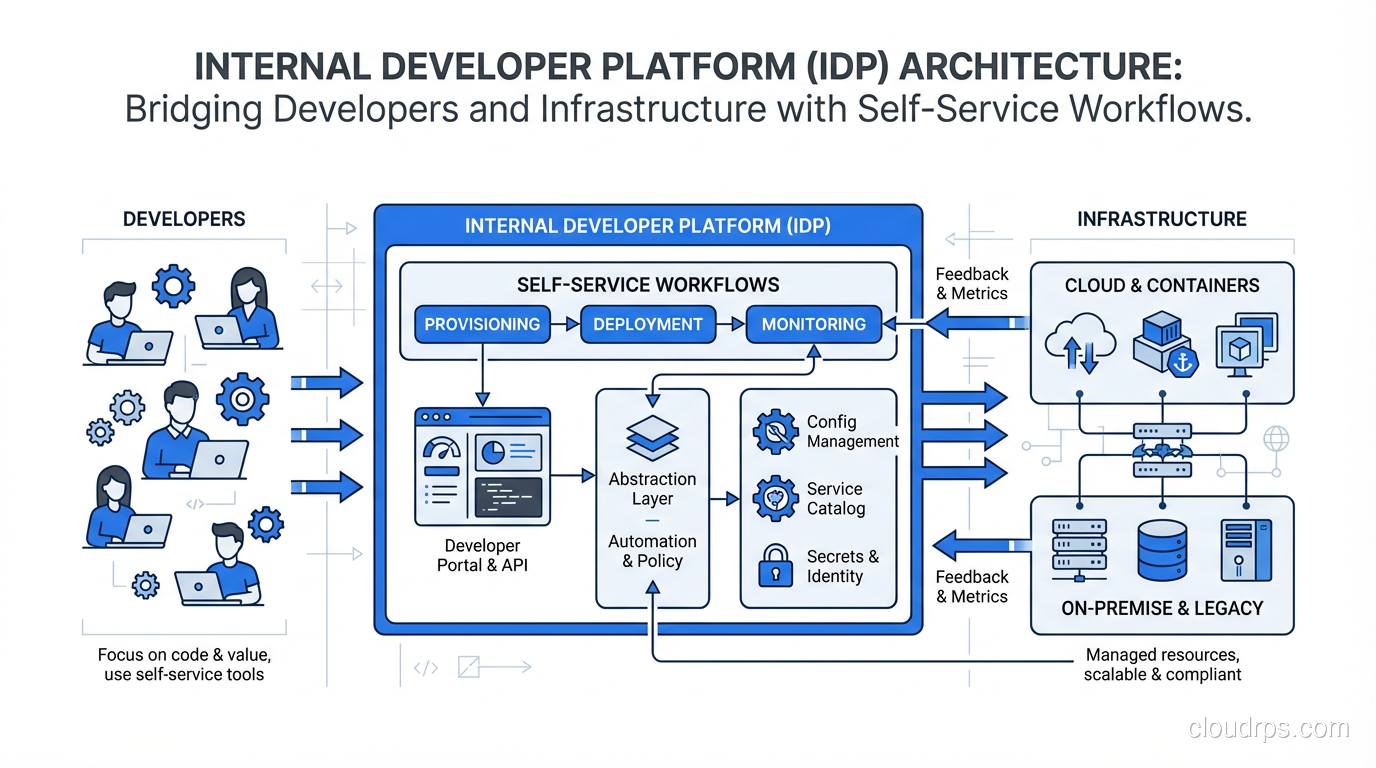
How platform engineering solves DevOps tool sprawl by giving developers self-service infrastructure. What an internal developer platform looks like and how to build one.
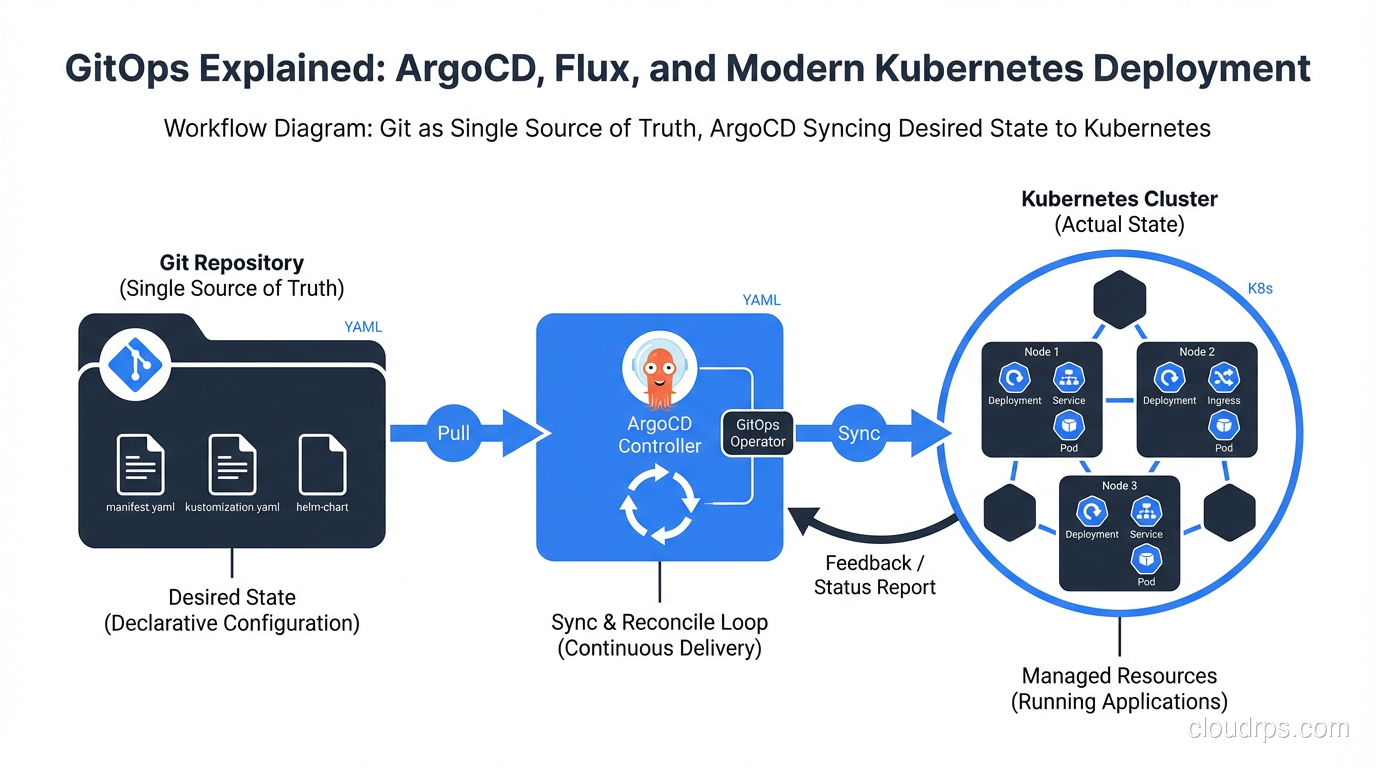
A practitioner's guide to GitOps: how to use Git as the single source of truth for infrastructure and application deployment with ArgoCD and Flux.
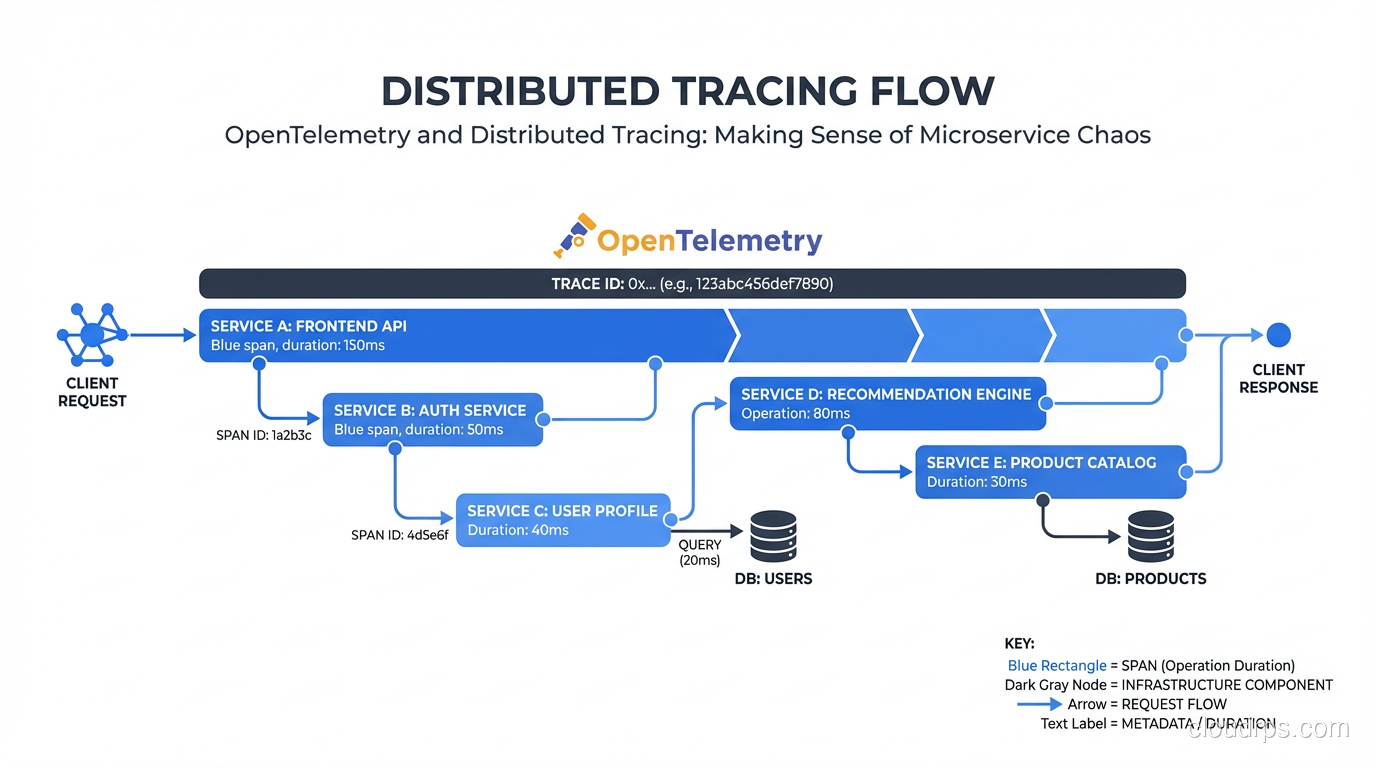
How OpenTelemetry works, why distributed tracing is different from logging and metrics, and how to instrument your services without drowning in overhead and noise.
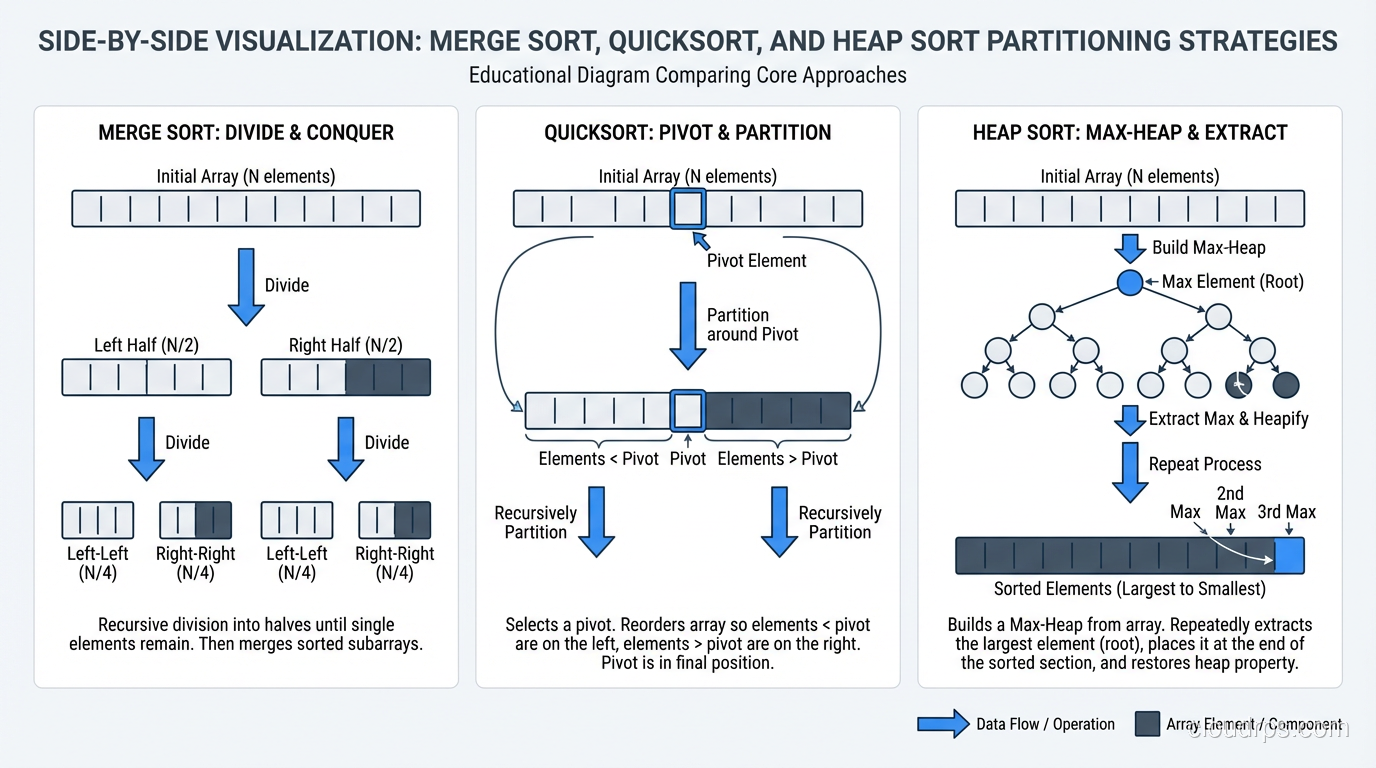
Sorting algorithms explained with real implementations, from bubble sort through Timsort. Big O complexity analysis and when algorithm choice actually matters in production.
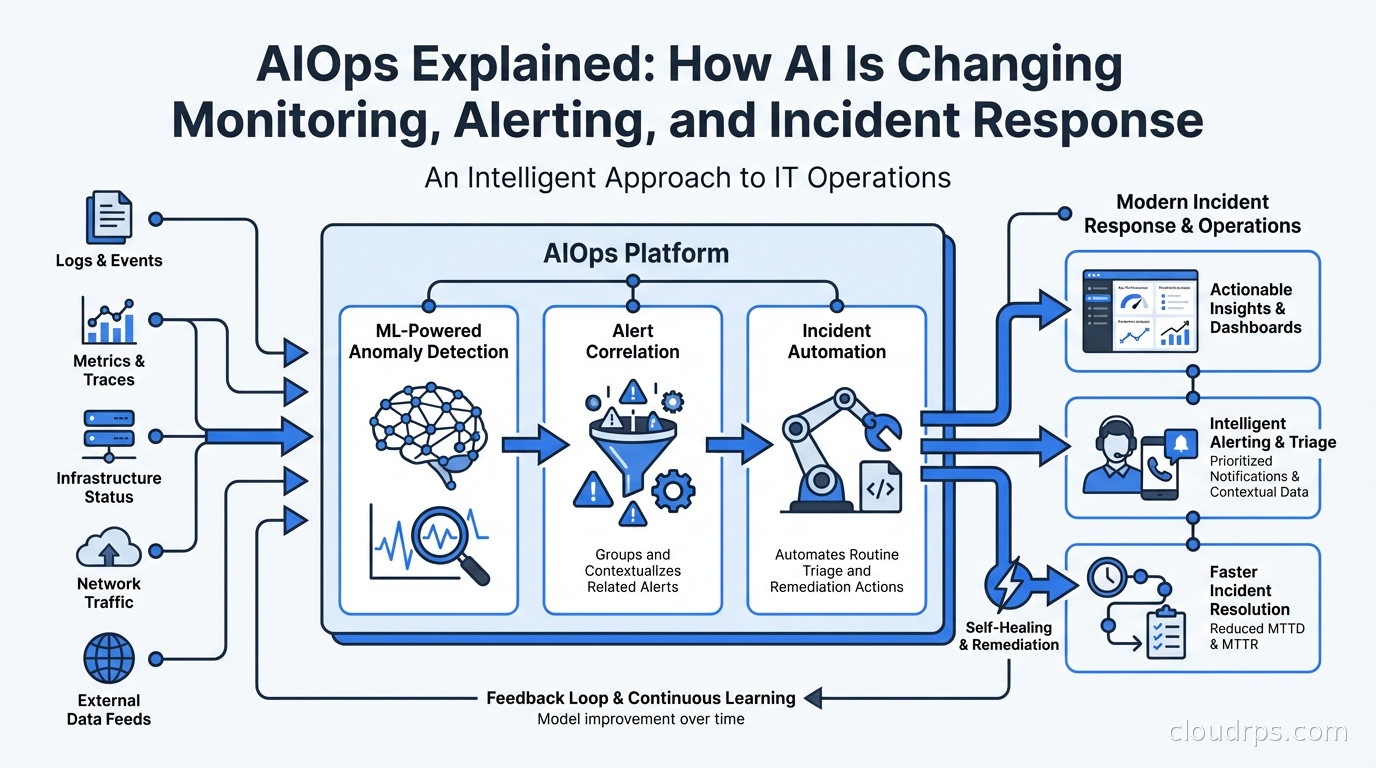
AIOps applies machine learning to operations data to reduce alert noise, detect anomalies, and accelerate incident response. Here's what works in practice and what's still hype.
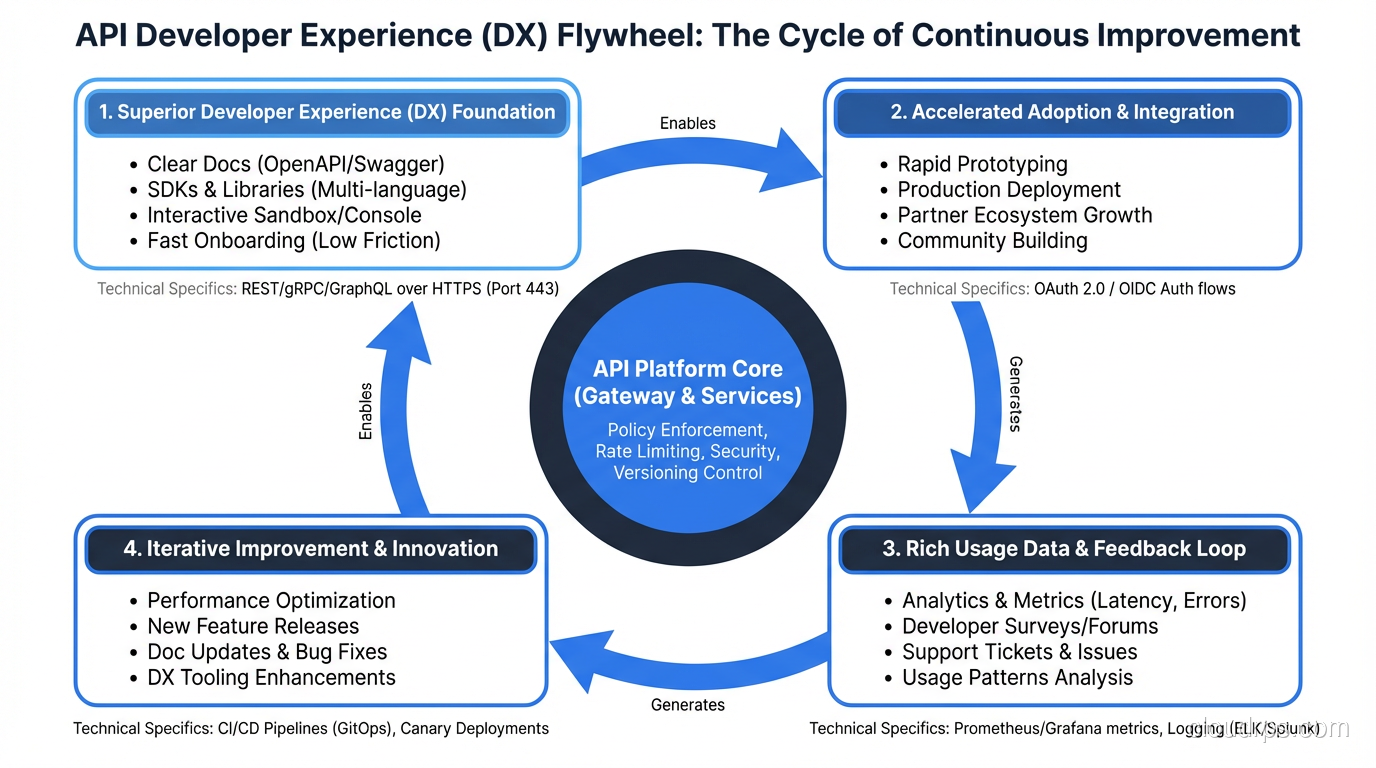
What makes an API developer-friendly: naming conventions, error handling, pagination, versioning, docs, and the design principles that separate great APIs from painful ones.
HTTP methods explained with real-world examples. GET, POST, PUT, PATCH, DELETE, plus HEAD and OPTIONS. When to use each, idempotency, and common mistakes.
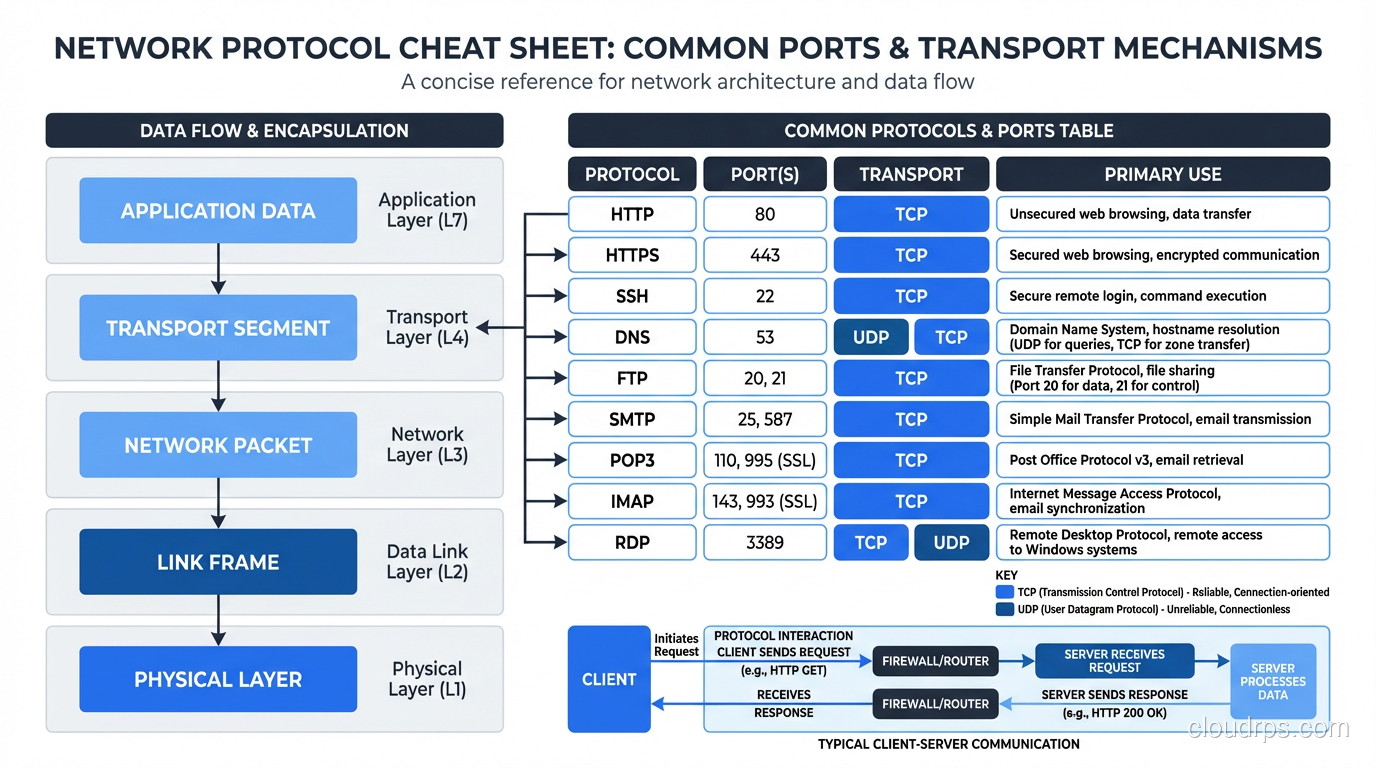
A networking protocols overview for practitioners. TCP, UDP, HTTP, ICMP, FTP, SNMP, and more explained by an architect who's debugged them all in production.
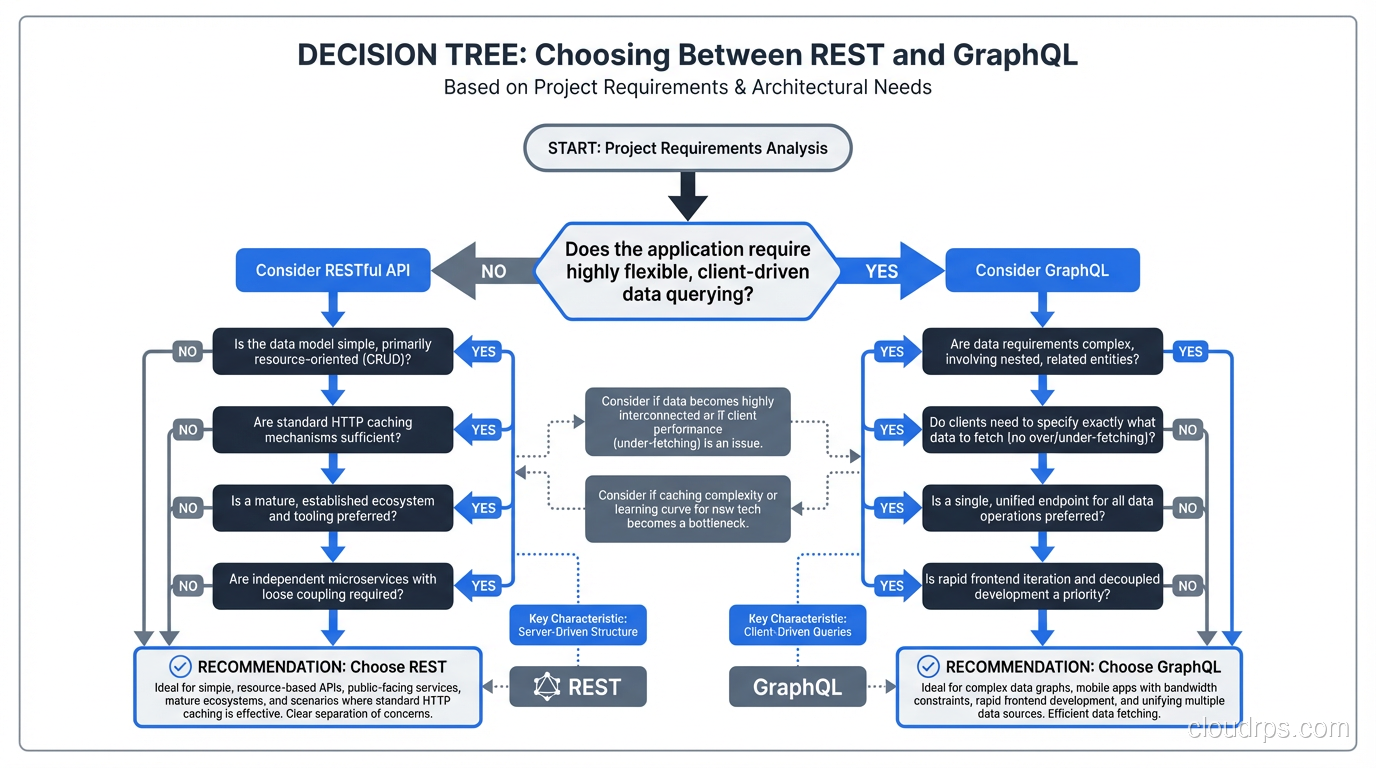
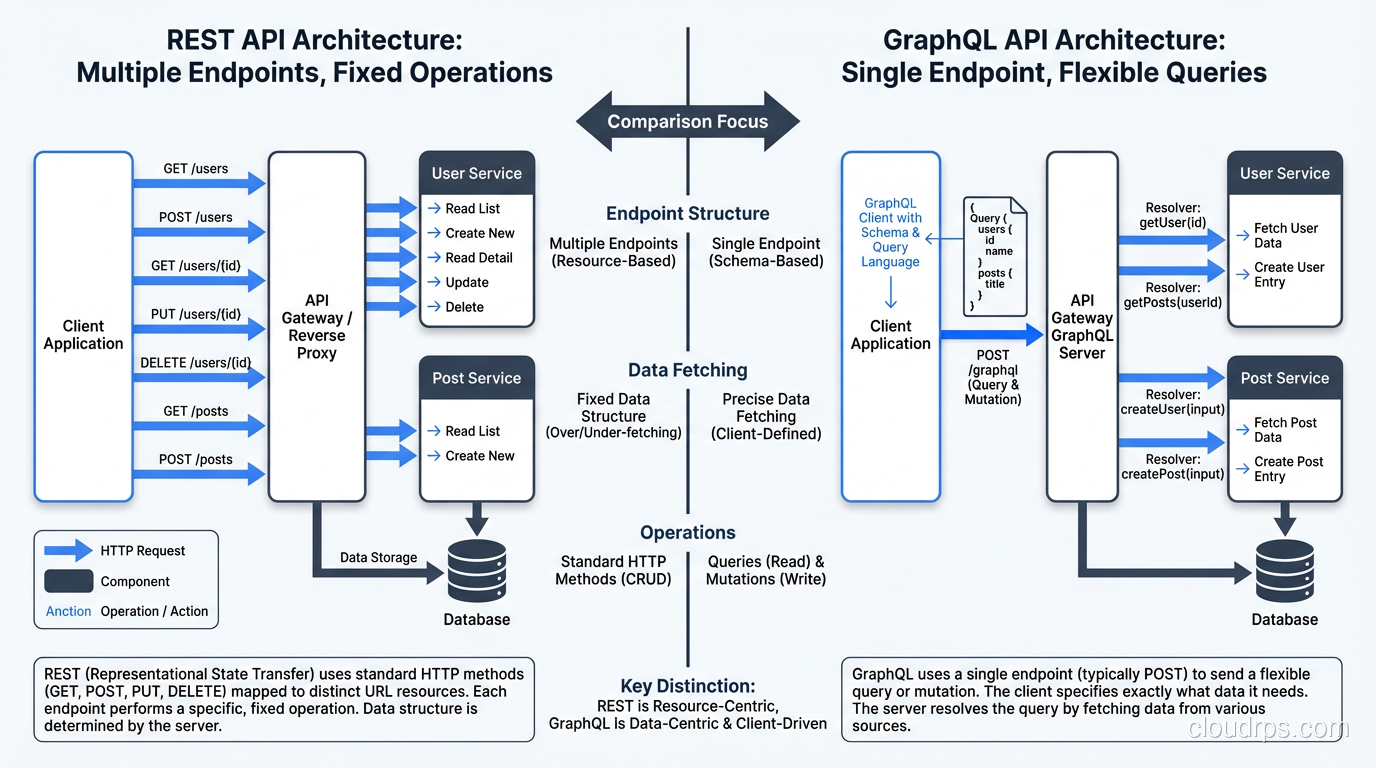
GraphQL vs REST compared honestly: architecture differences, real performance trade-offs, and a practical decision framework for choosing between them.
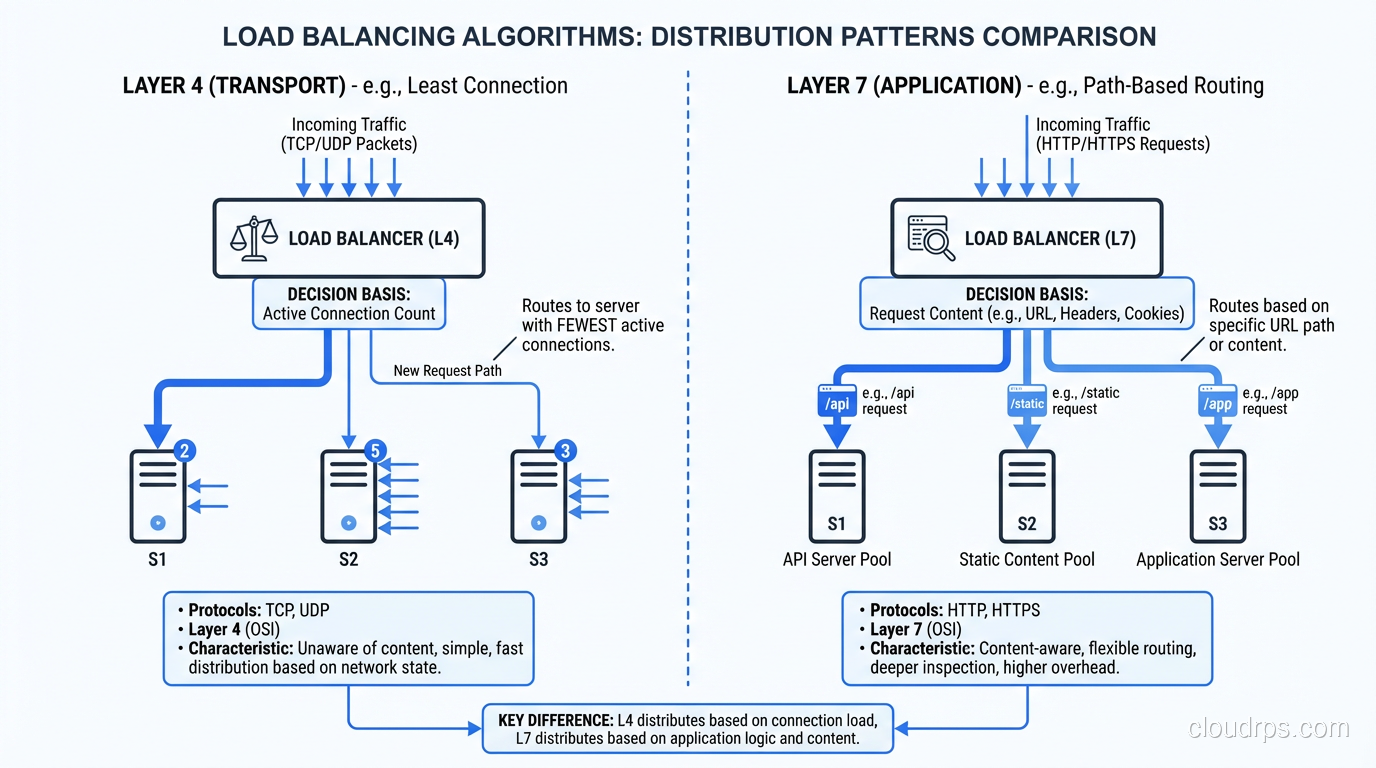
A deep dive into load balancer types from an architect who's configured hundreds. L4, L7, global, and how to pick the right one for your architecture.
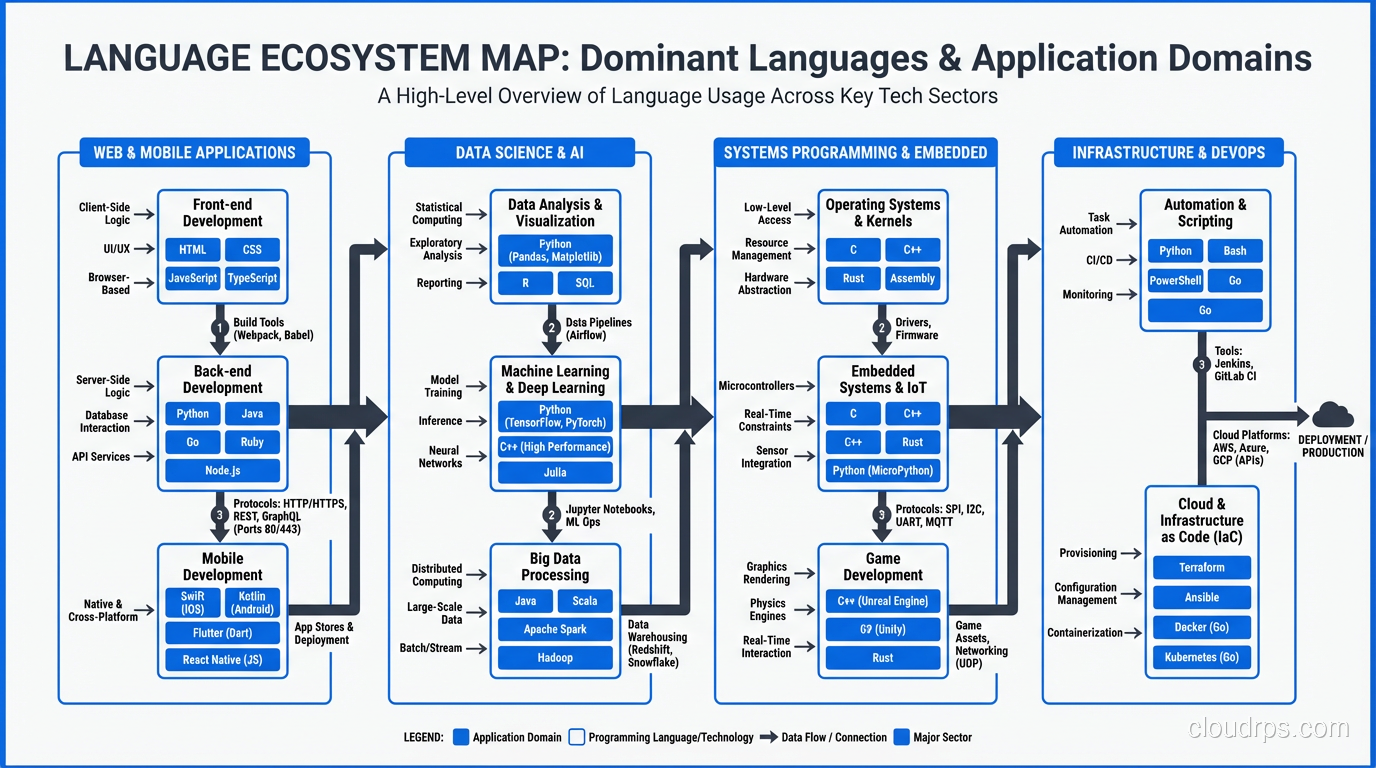
The real differences between scripting and compiled languages: how they work under the hood, performance trade-offs, and when to reach for Python vs Go vs Rust.
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.