DevOps
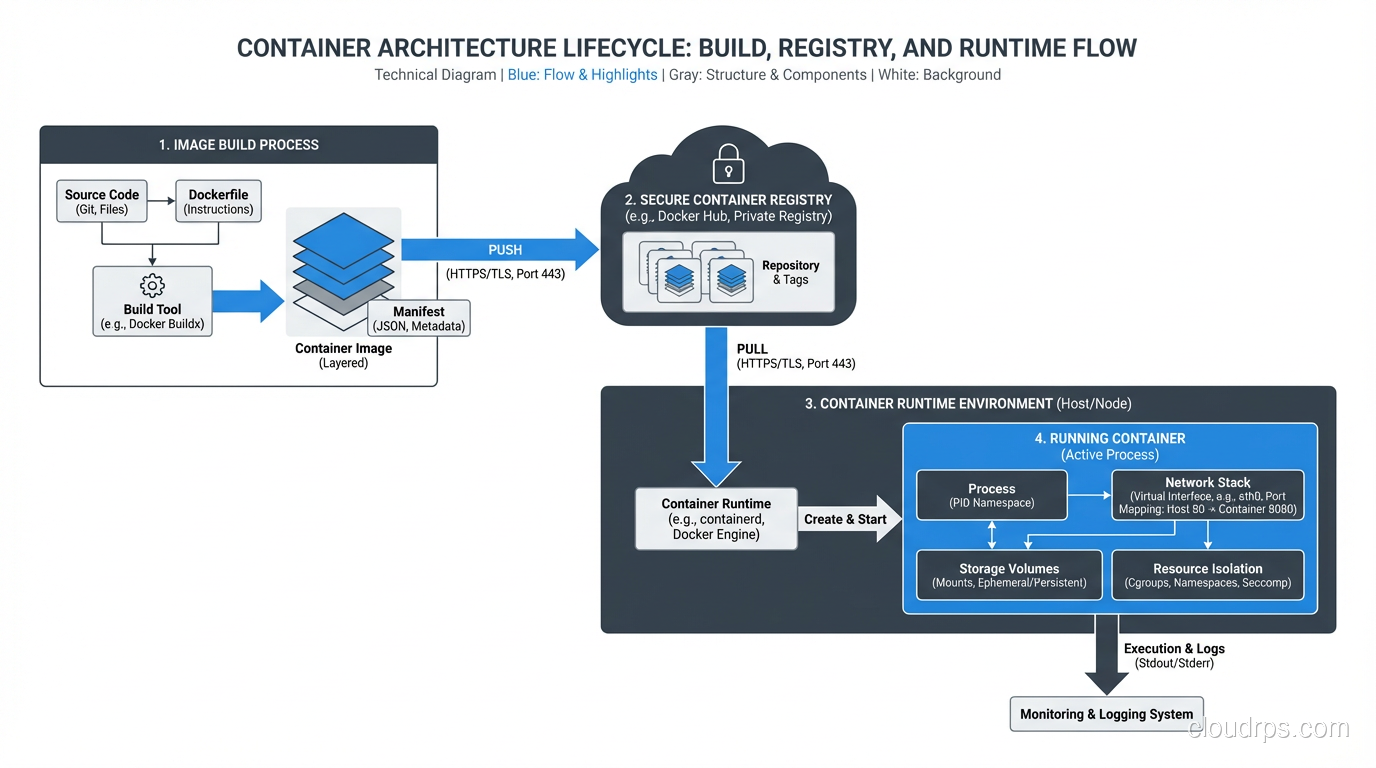
Kubernetes, Docker, and Containers: What You Actually Need to Know
A senior architect's honest take on Kubernetes, Docker, and containers. What they are, when you need them, and when you absolutely don't.
A senior architect's honest take on Kubernetes, Docker, and containers. What they are, when you need them, and when you absolutely don't.
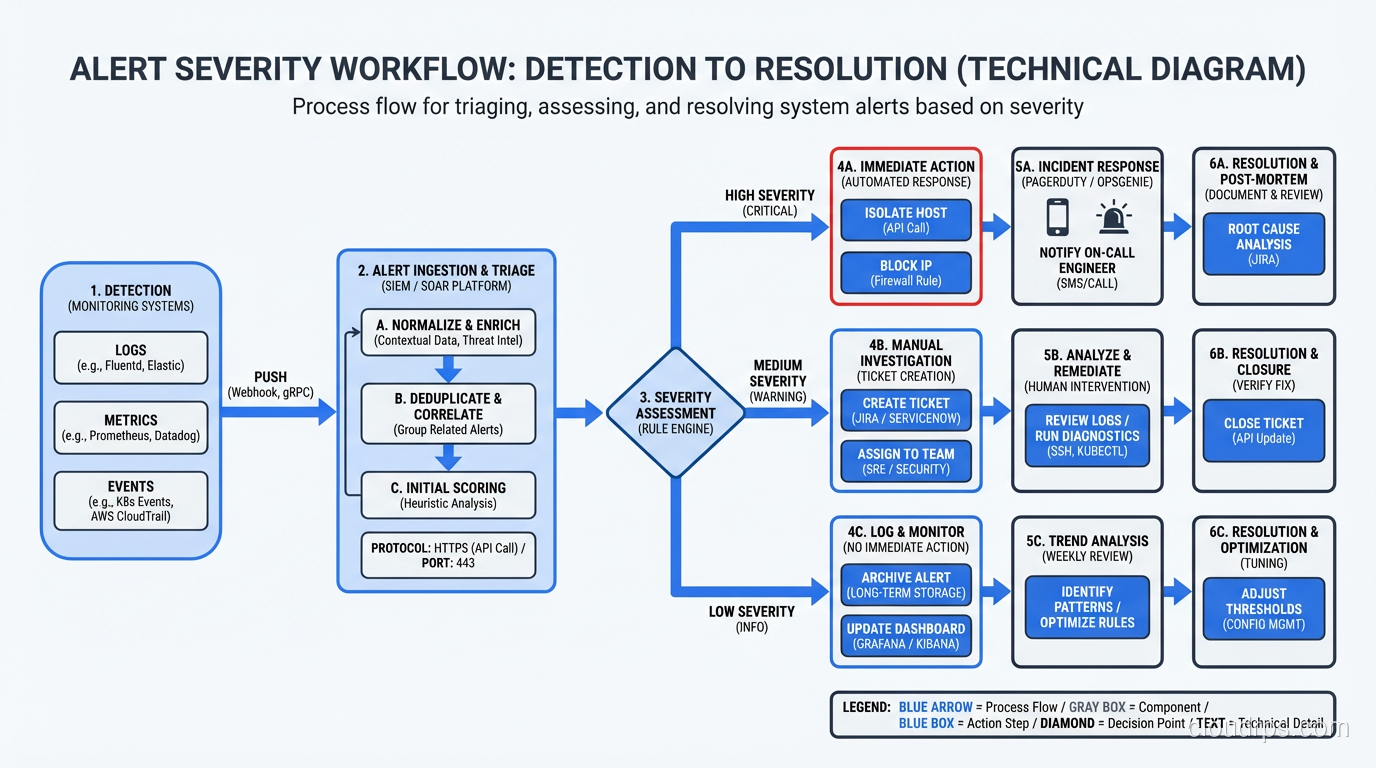
Practical monitoring and logging advice from three decades of production operations. What metrics matter, how to build alerts that work, and tools I trust.
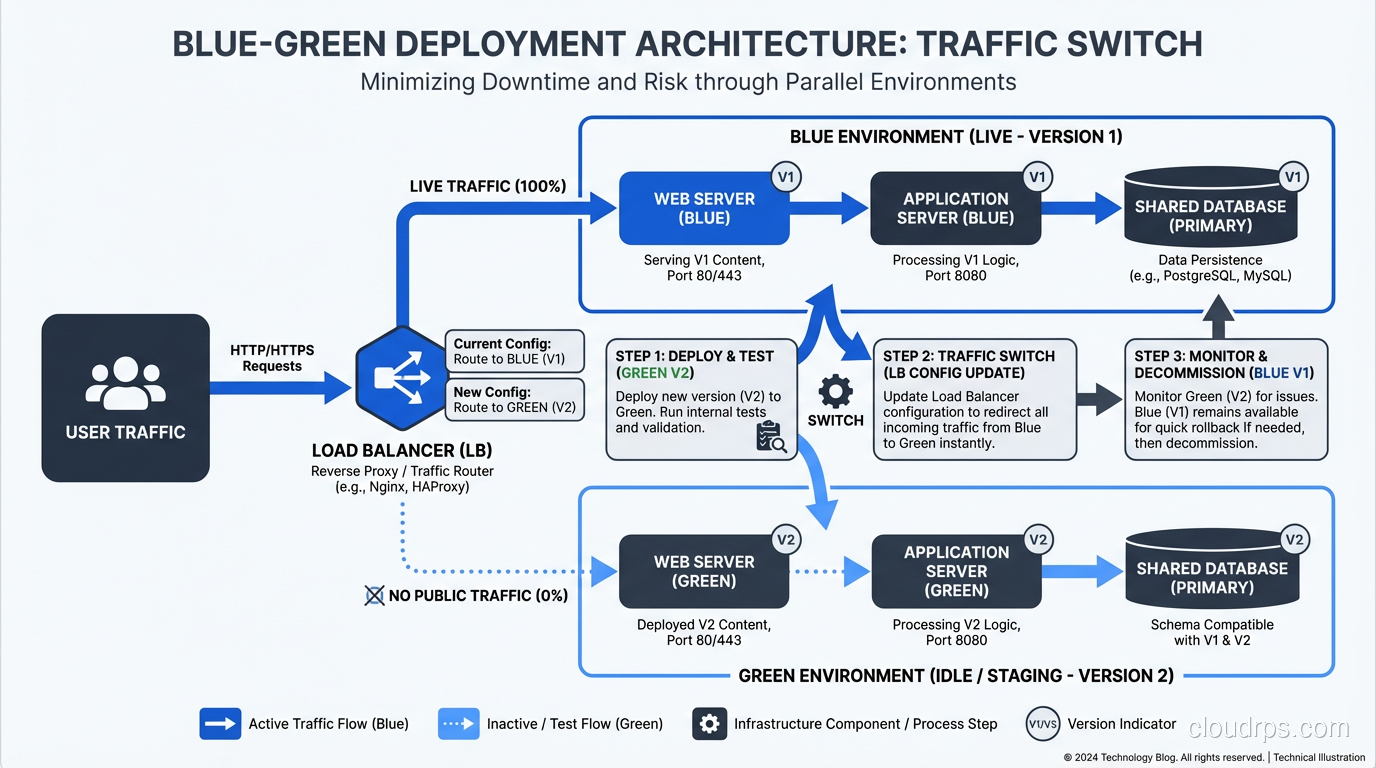
A battle-tested guide to blue-green deployments from an architect who's used them to eliminate downtime across hundreds of releases in production.
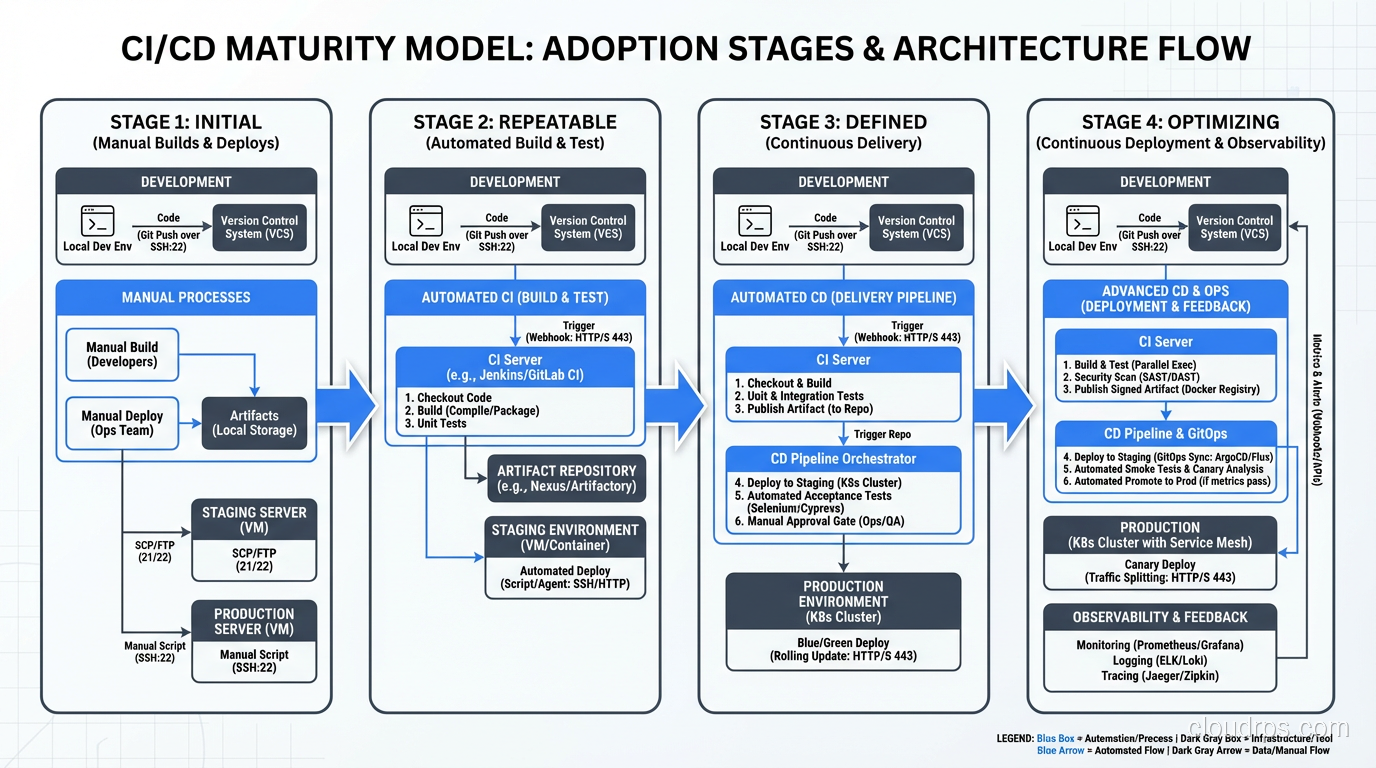
Learn CI/CD from someone who built pipelines before the tools existed. Continuous integration and delivery principles, patterns, and hard-won lessons.
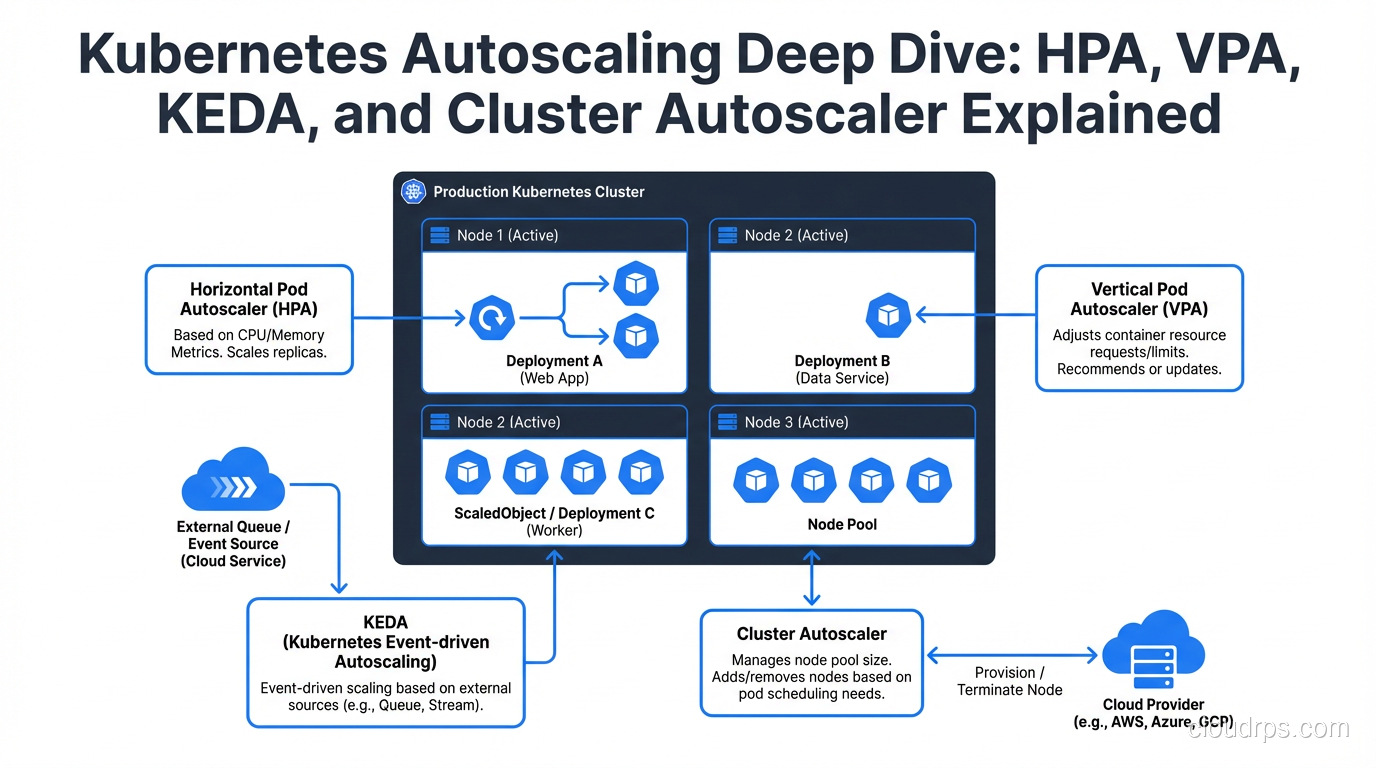
A practical guide to Kubernetes autoscaling: how HPA, VPA, KEDA, and Cluster Autoscaler work, when to use each, and how to avoid the pitfalls that catch most teams.
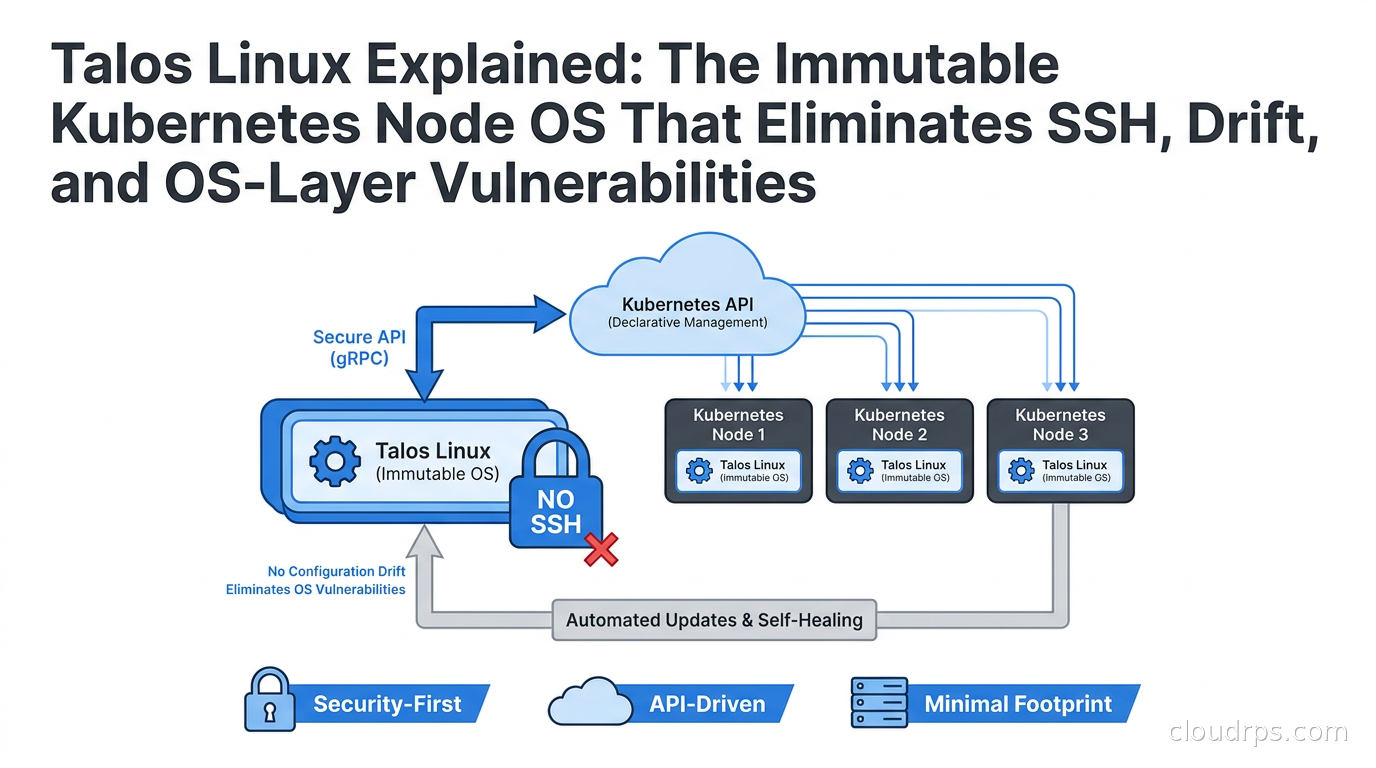
Talos Linux removes SSH, the shell, and mutable state from Kubernetes nodes entirely. Here's how it works, how it compares to Flatcar, Bottlerocket, and Fedora CoreOS, and why it's changing how serious teams run Kubernetes in production.
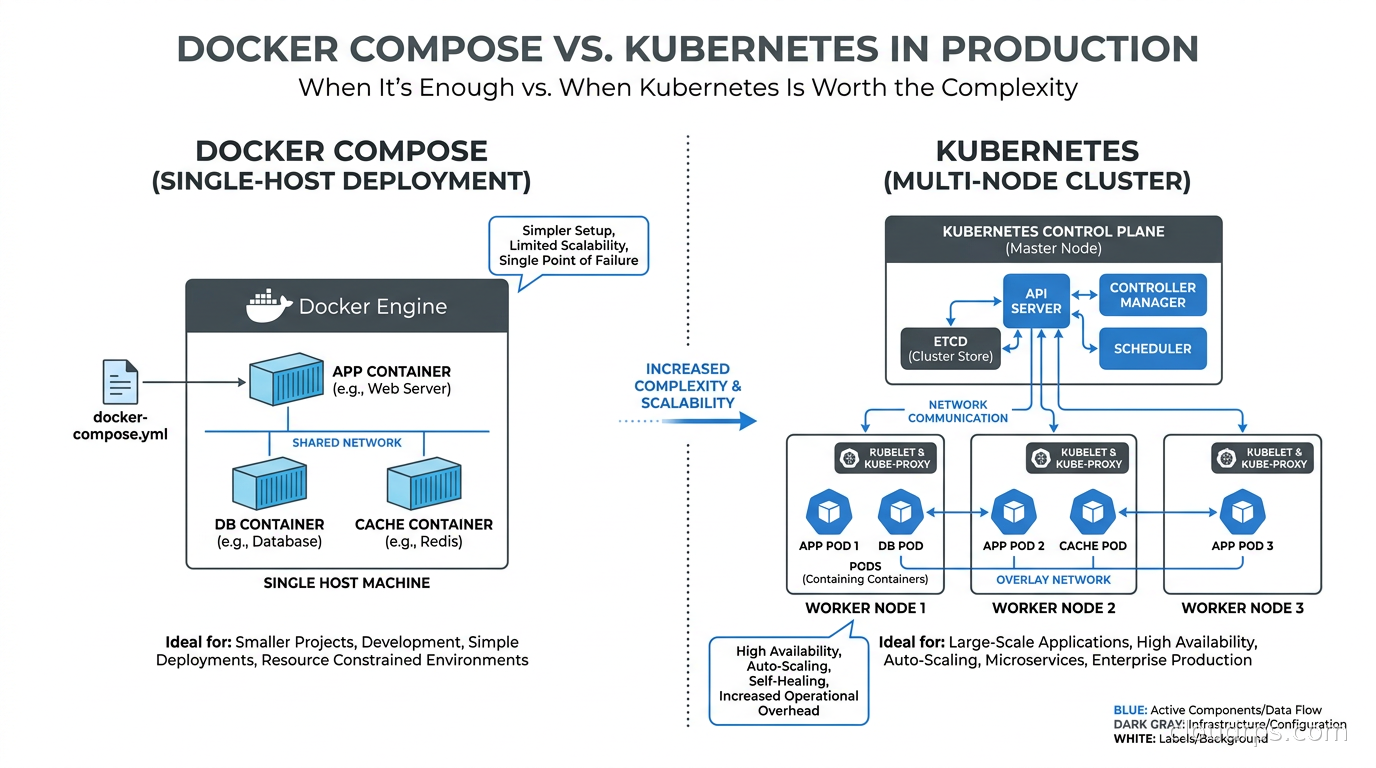
A principal cloud architect's honest take on when Docker Compose is the right production tool and when Kubernetes complexity is genuinely justified. Includes a decision framework, real failure modes, and migration signals.
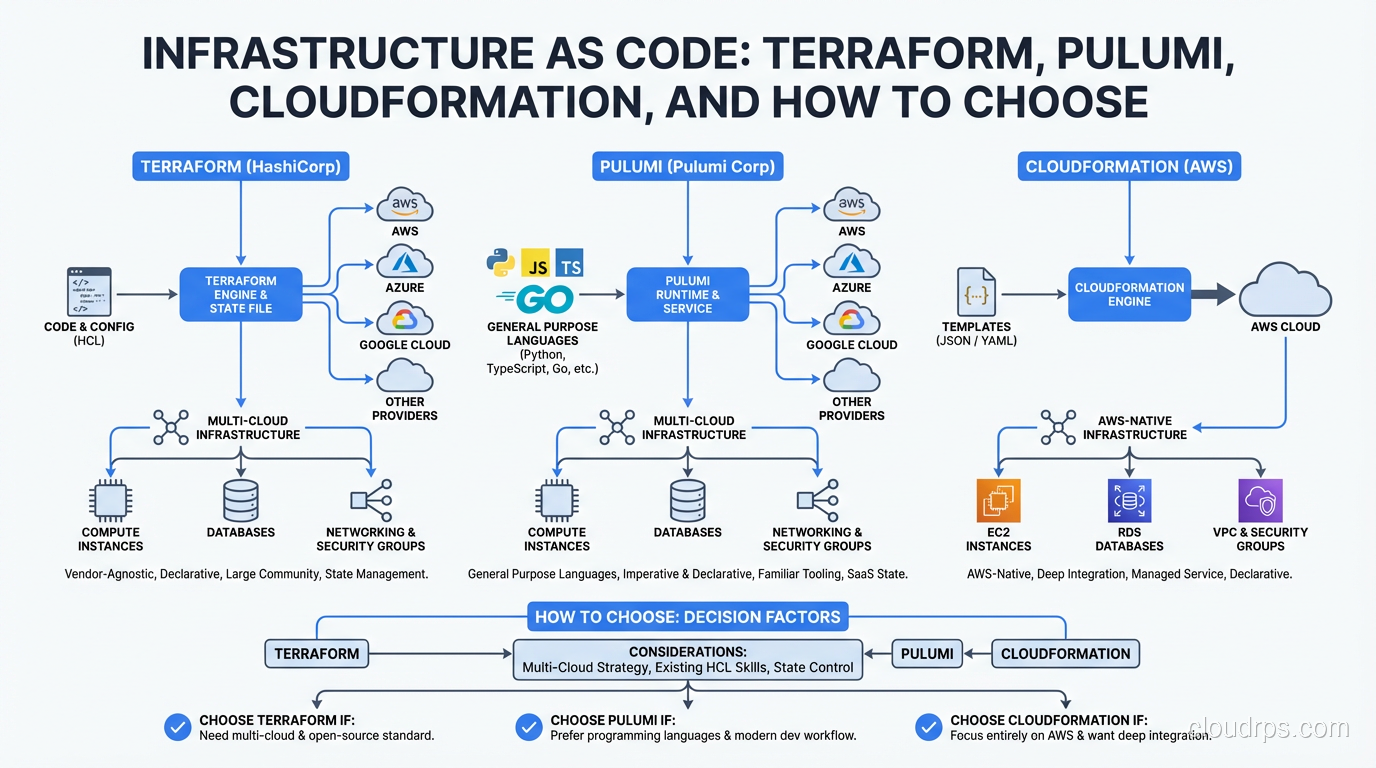
A practical guide to Infrastructure as Code tools. Compare Terraform, Pulumi, CloudFormation, and OpenTofu with real-world examples, trade-offs, and migration stories.
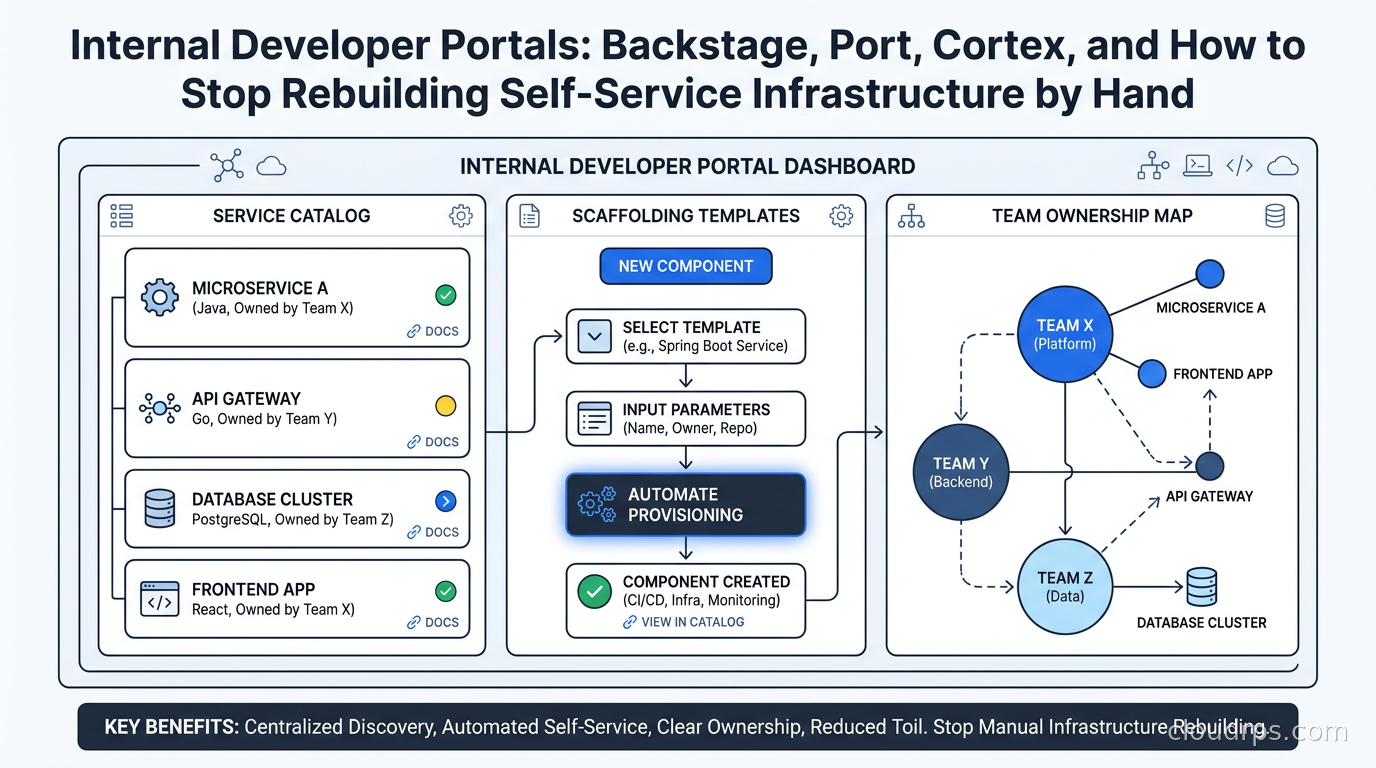
A principal cloud architect's guide to internal developer portals. Compare Backstage, Port, Cortex, and OpsLevel — and learn how to actually get engineers to use one.
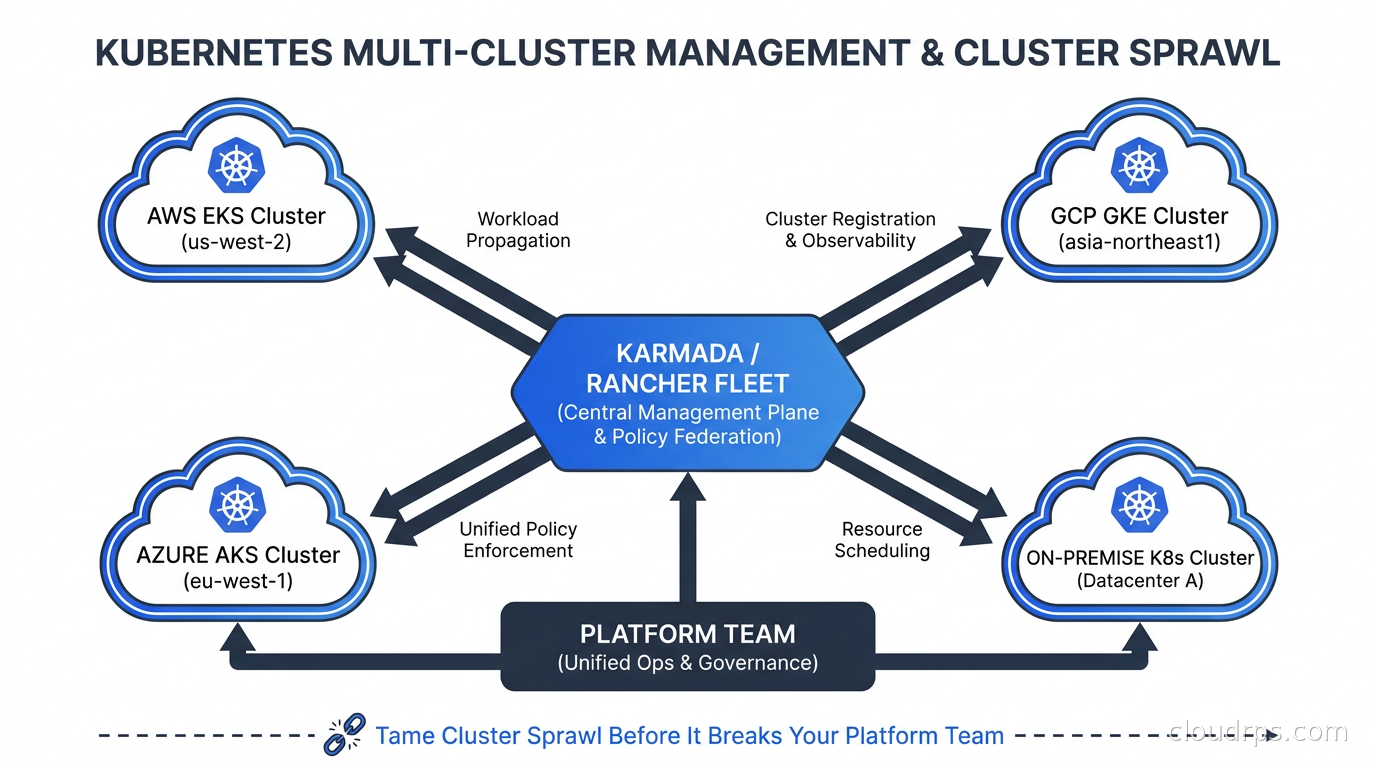
A principal cloud architect's guide to managing fleets of Kubernetes clusters. Covers Karmada, Rancher Fleet, Open Cluster Management, ArgoCD ApplicationSets, policy federation, and the economics of cluster sprawl.
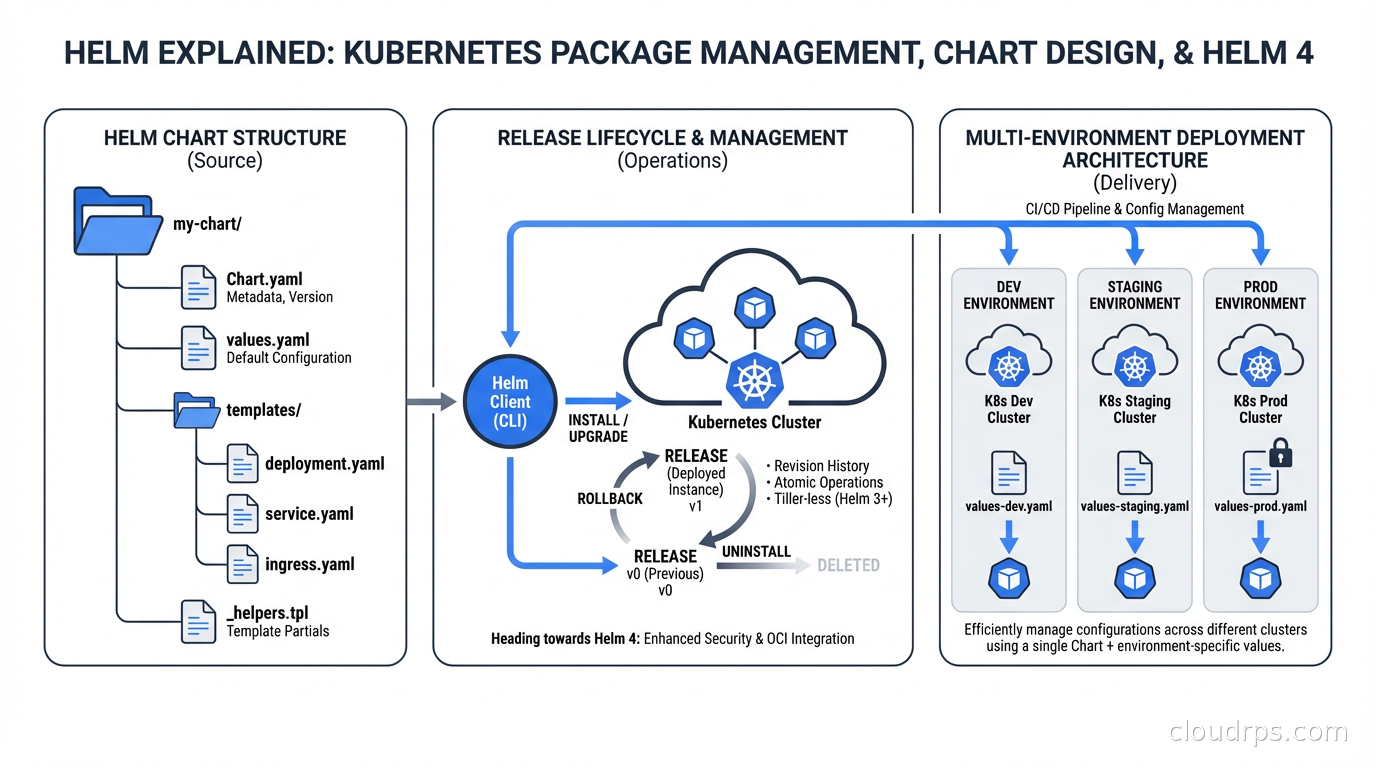
A practical guide to Helm, the de facto Kubernetes package manager: core concepts, chart design patterns, Helmfile for multi-environment management, and what Helm 4's server-side apply changes for your production clusters.
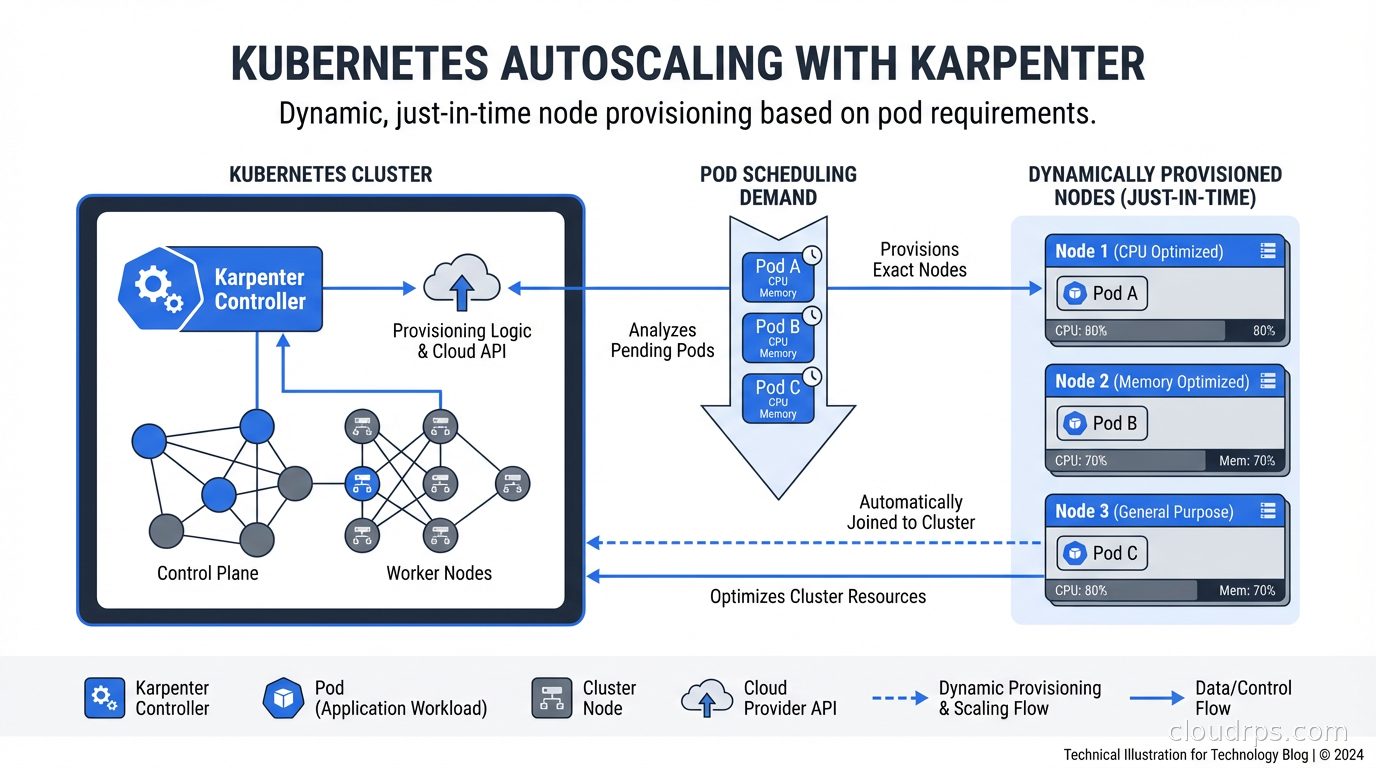
Karpenter replaces the Kubernetes Cluster Autoscaler with a faster, smarter node provisioner that cuts costs and response time. Here's how it works and why it matters.
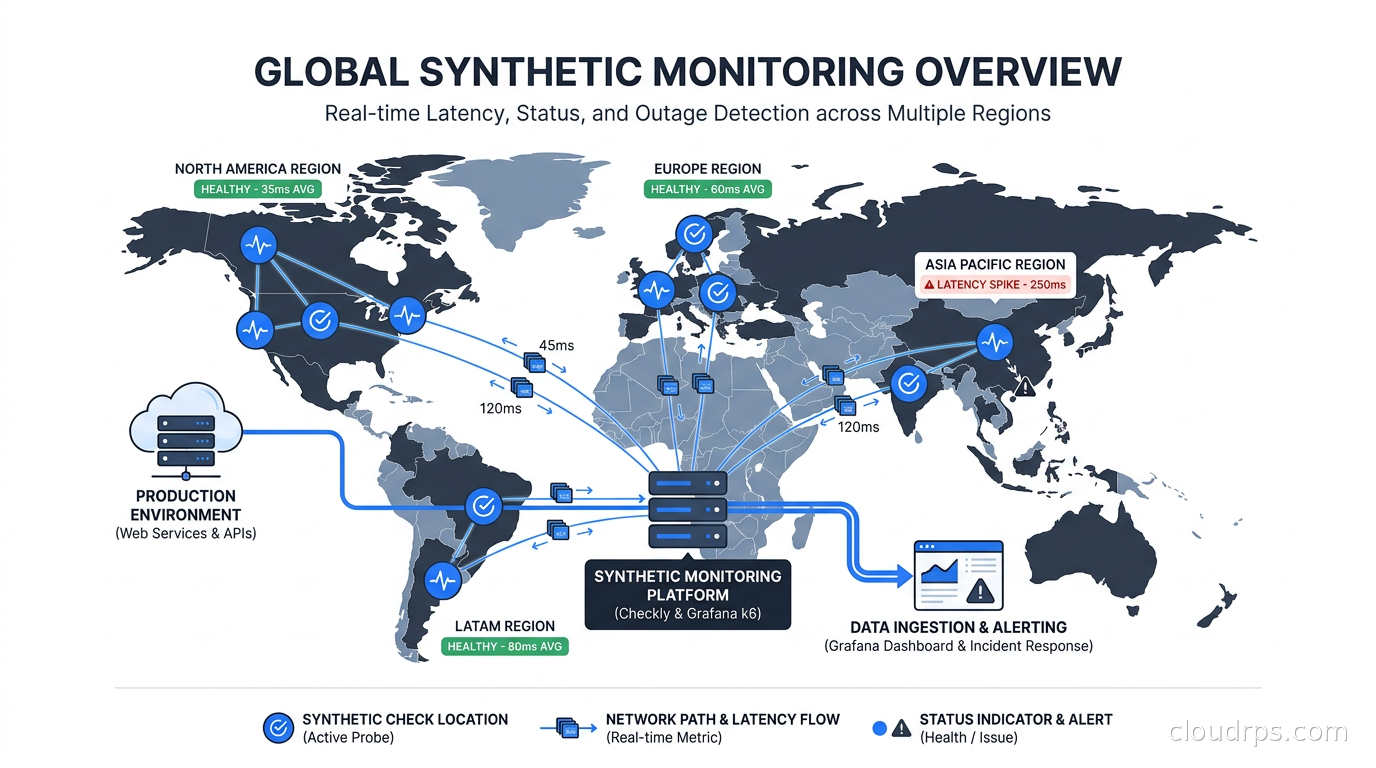
Synthetic monitoring lets you detect outages before users do. Learn how to build production-grade checks with Checkly and Grafana k6, integrate them with your SLOs, and stop finding out about failures from support tickets.
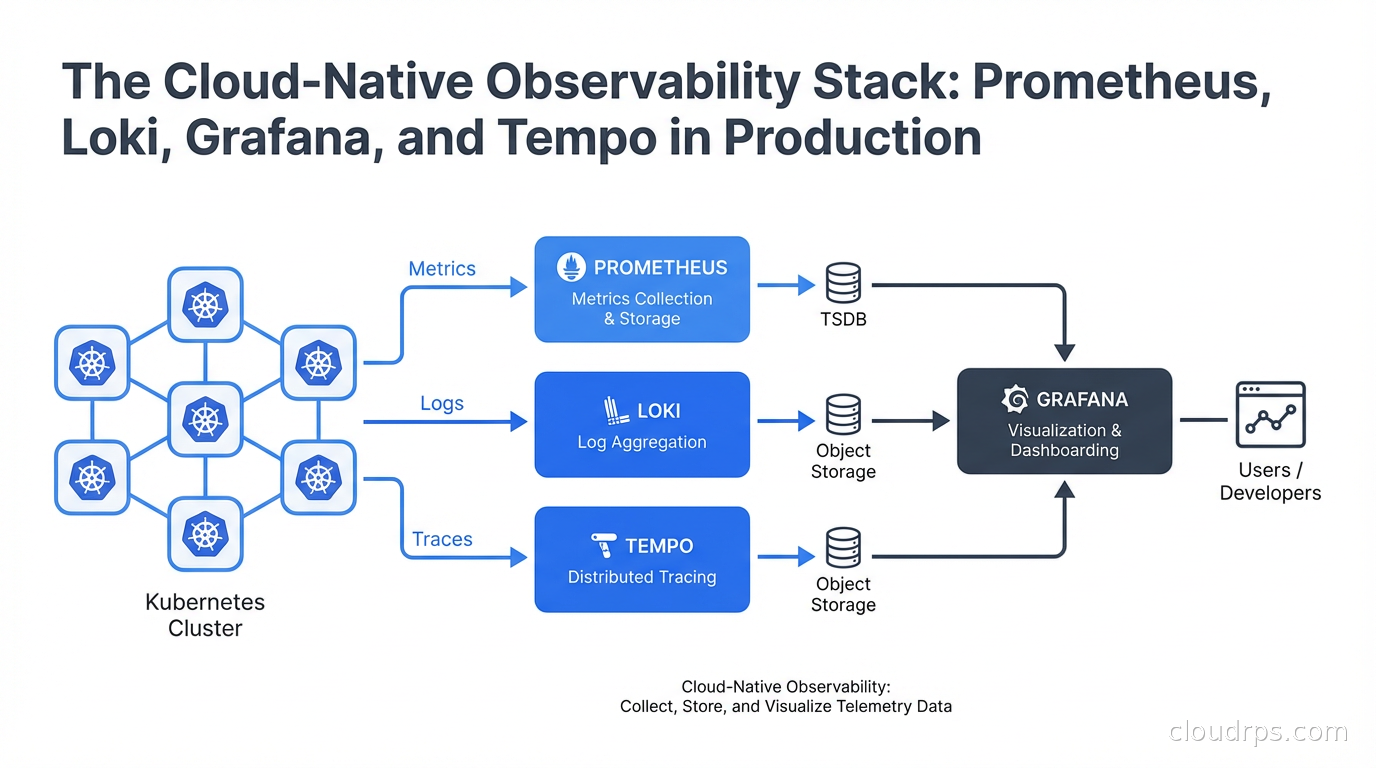
A deep-dive into building a production-grade observability stack with Prometheus, Loki, Grafana, and Tempo. Learn the architecture, scaling trade-offs, cardinality traps, and when the open-source stack beats a $40k/month SaaS bill.

DORA's four key metrics (deployment frequency, lead time, MTTR, change failure rate) are the clearest signal we have for engineering team performance. Here's how to measure them, what they tell you, and how to avoid gaming them.

Everything you need to know about Terraform state: how remote backends work, why state locking saves you from concurrent apply disasters, when to use workspaces versus separate state files, and patterns for managing state at scale across multiple teams.
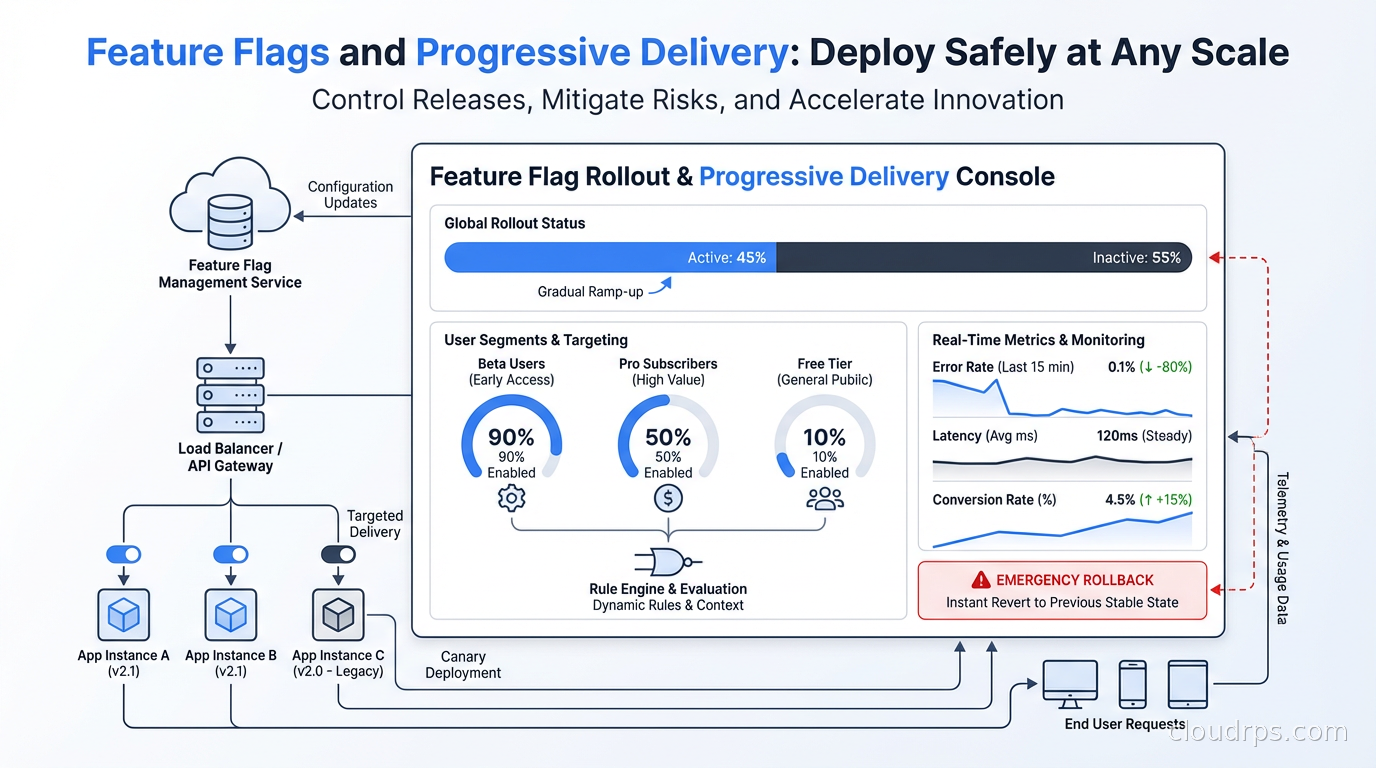
Feature flags decouple deployment from release. Progressive delivery uses them to roll out features safely to 1% of users before 100%. Here's the architecture and tooling that makes it work.
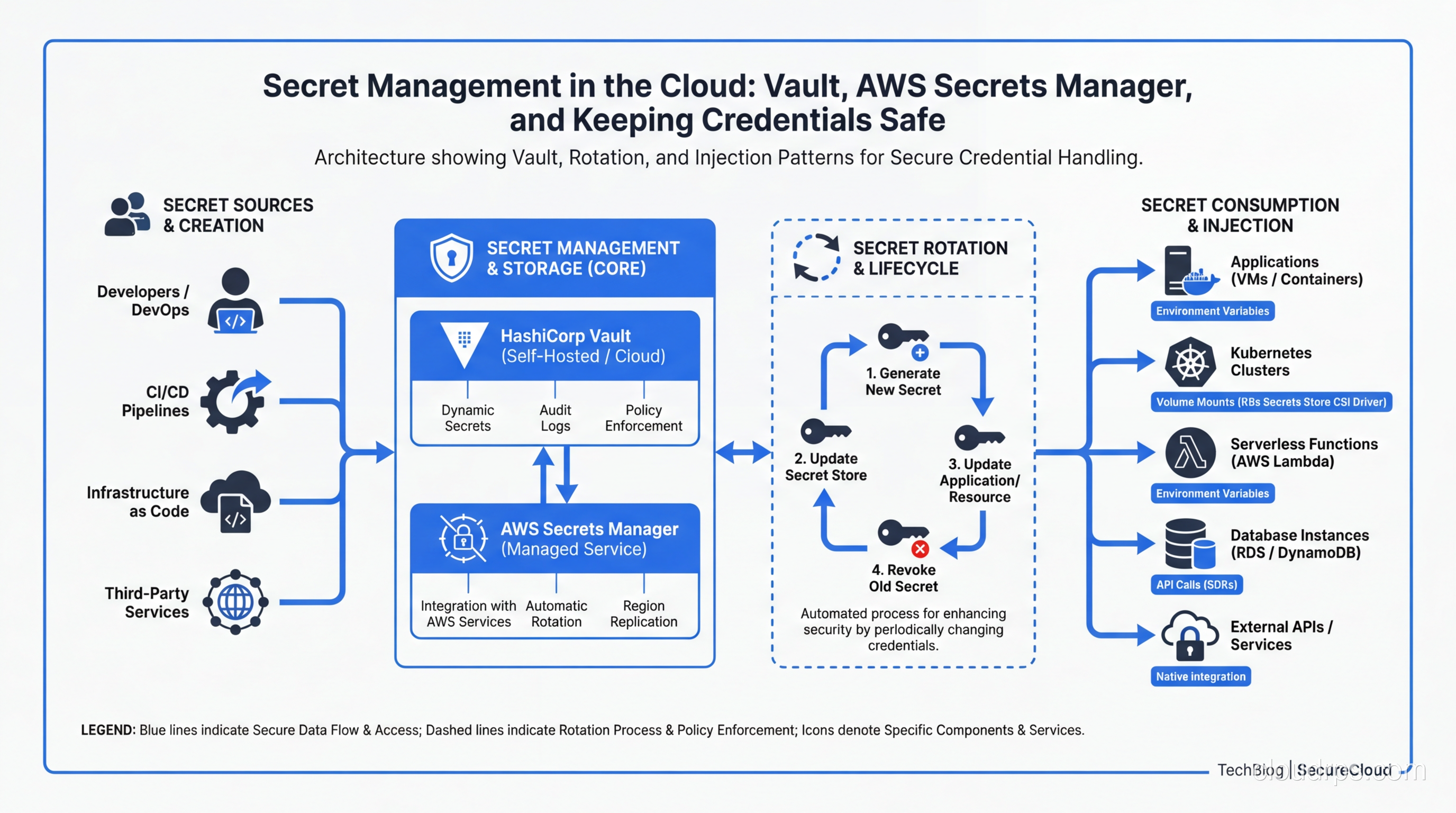
A practical guide to managing secrets in cloud infrastructure: comparing HashiCorp Vault, AWS Secrets Manager, and other tools, with real-world patterns for rotation, injection, and zero-trust secret delivery.
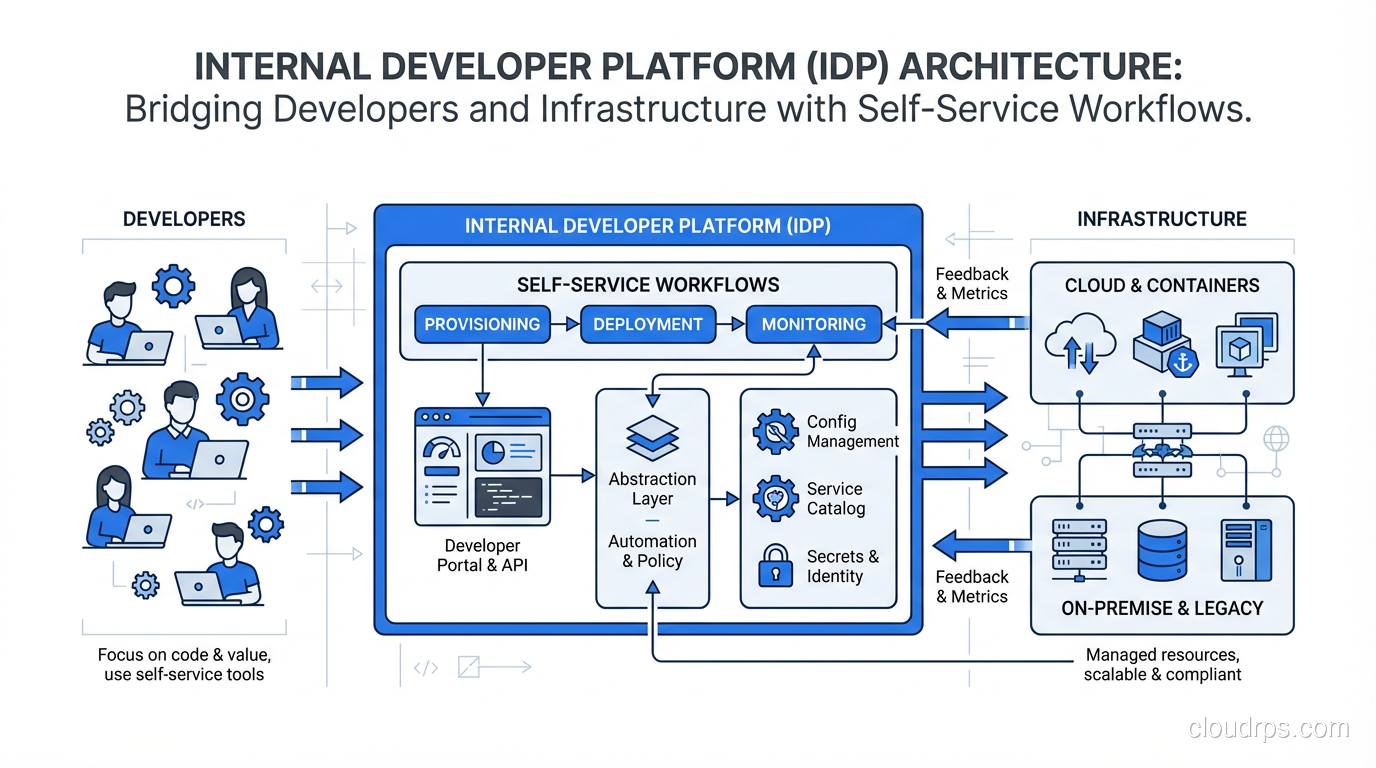
How platform engineering solves DevOps tool sprawl by giving developers self-service infrastructure. What an internal developer platform looks like and how to build one.
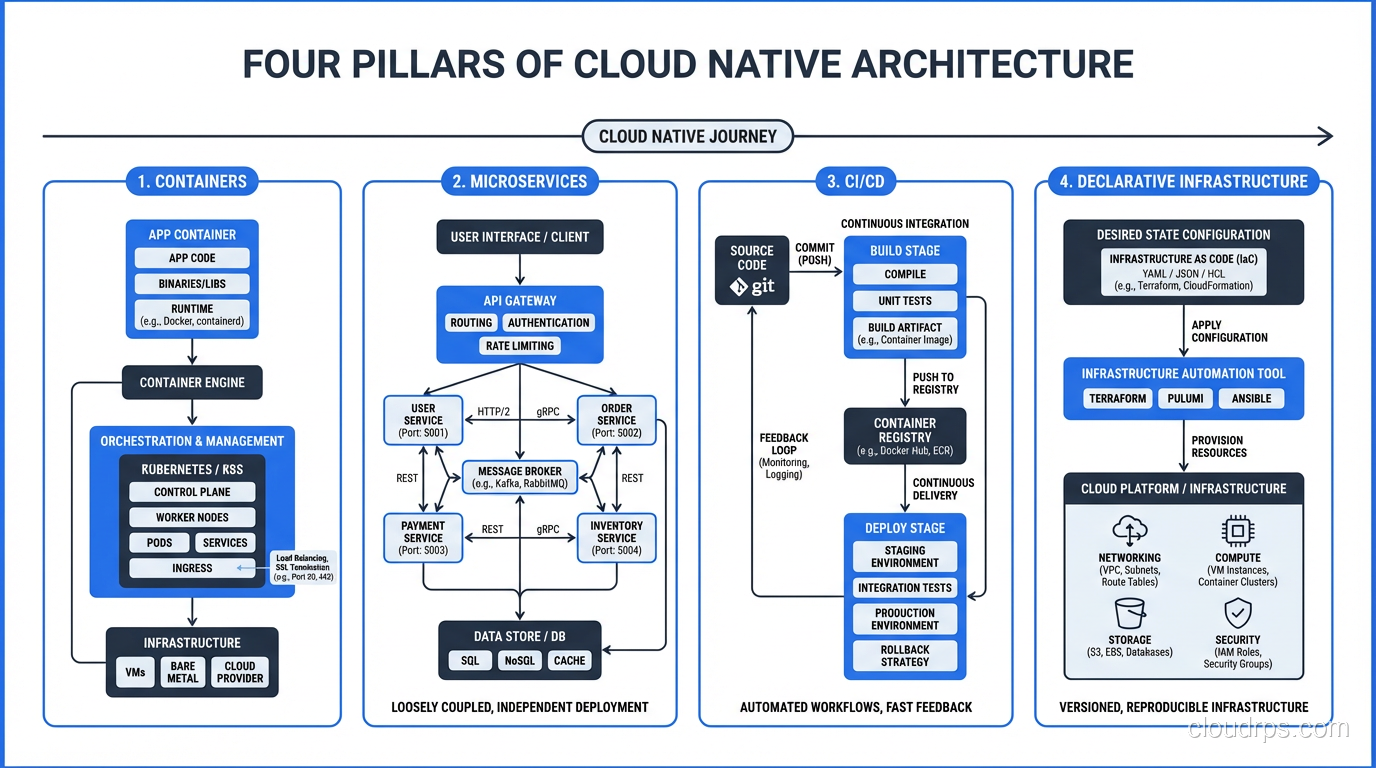
A veteran architect explains what cloud native actually means beyond the buzzwords, covering containers, microservices, CI/CD, and the architectural principles that matter.
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.