DevOps
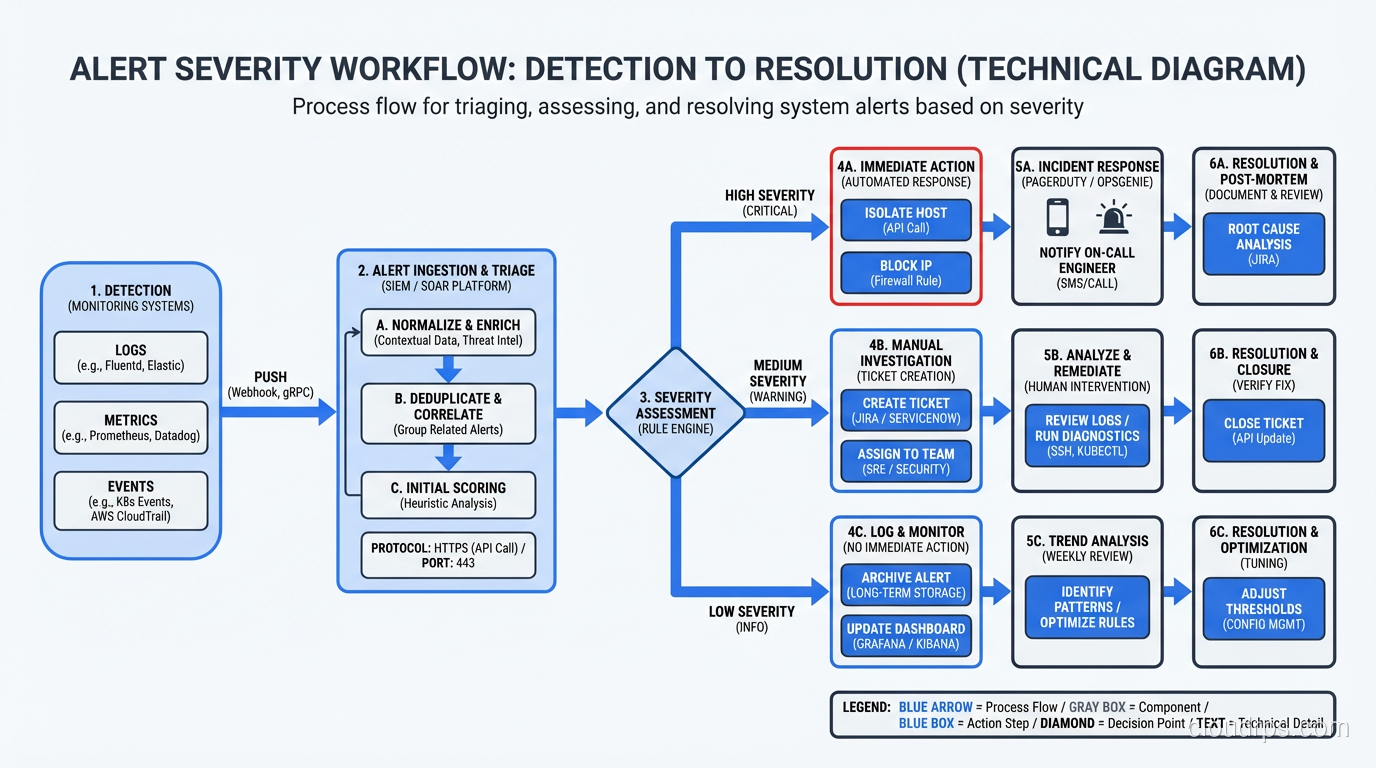
Monitoring and Logging: What to Track, How to Alert, and Tools That Work
Practical monitoring and logging advice from three decades of production operations. What metrics matter, how to build alerts that work, and tools I trust.
Practical monitoring and logging advice from three decades of production operations. What metrics matter, how to build alerts that work, and tools I trust.
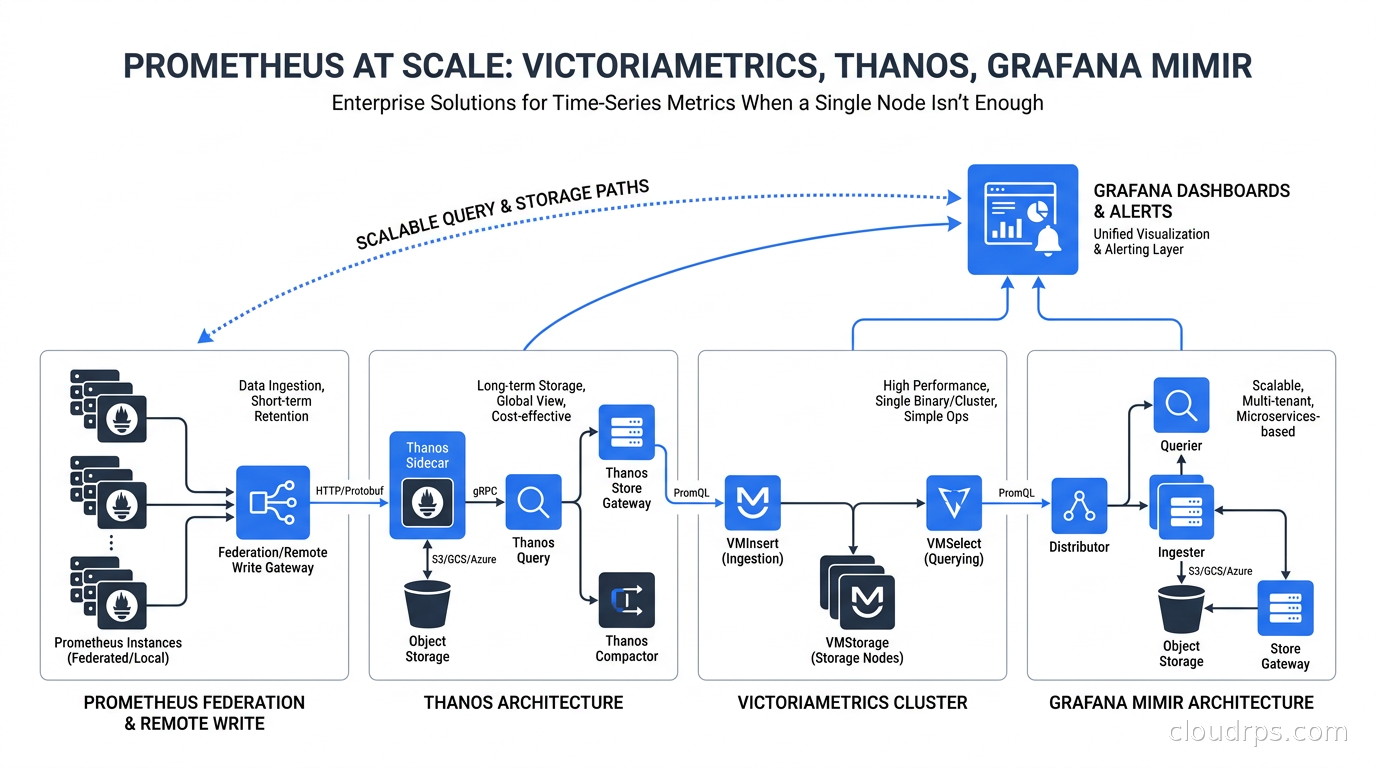
Single-node Prometheus breaks down at scale. Here's how VictoriaMetrics, Thanos, and Grafana Mimir solve long-term storage, high availability, and multi-cluster metrics at petabyte scale.
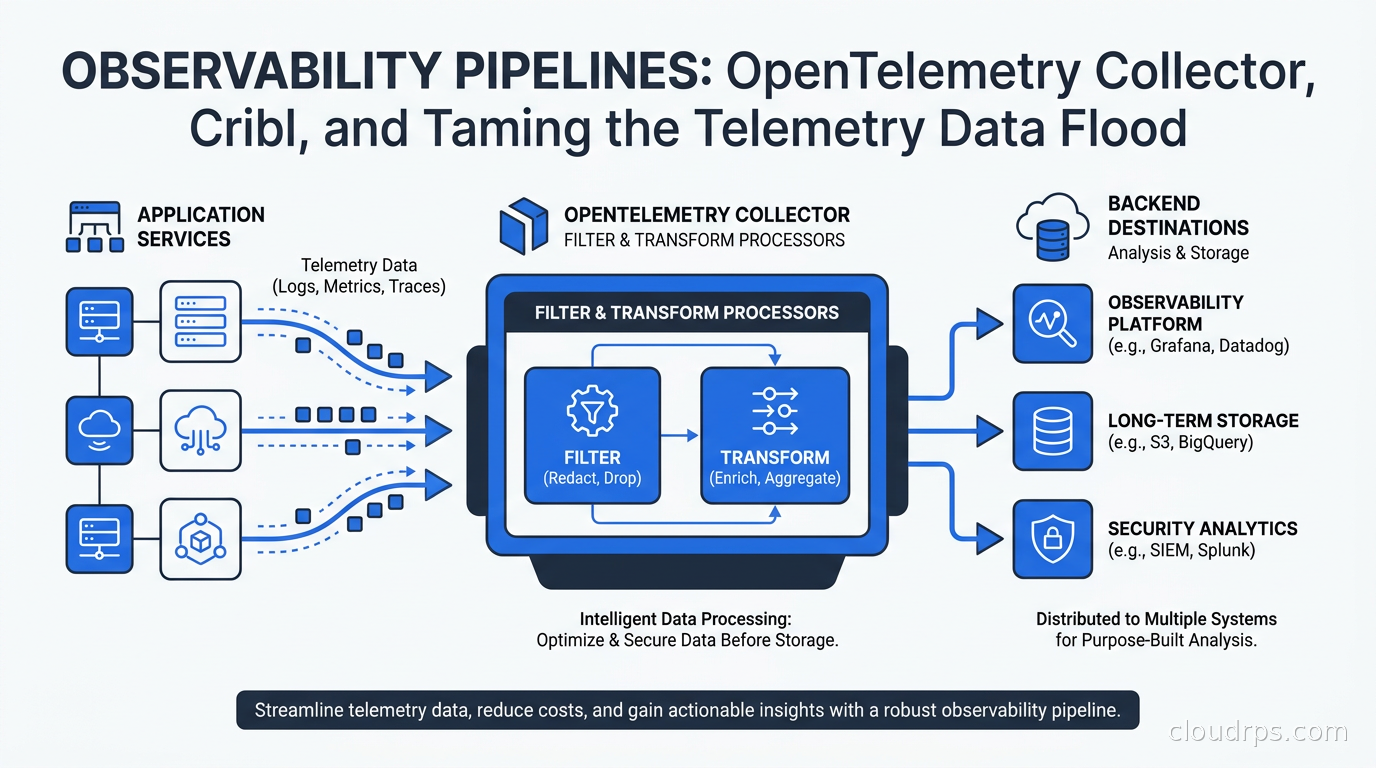
How to build observability pipelines with the OpenTelemetry Collector, Cribl, and Vector to cut telemetry costs 60-80% without losing diagnostic visibility.
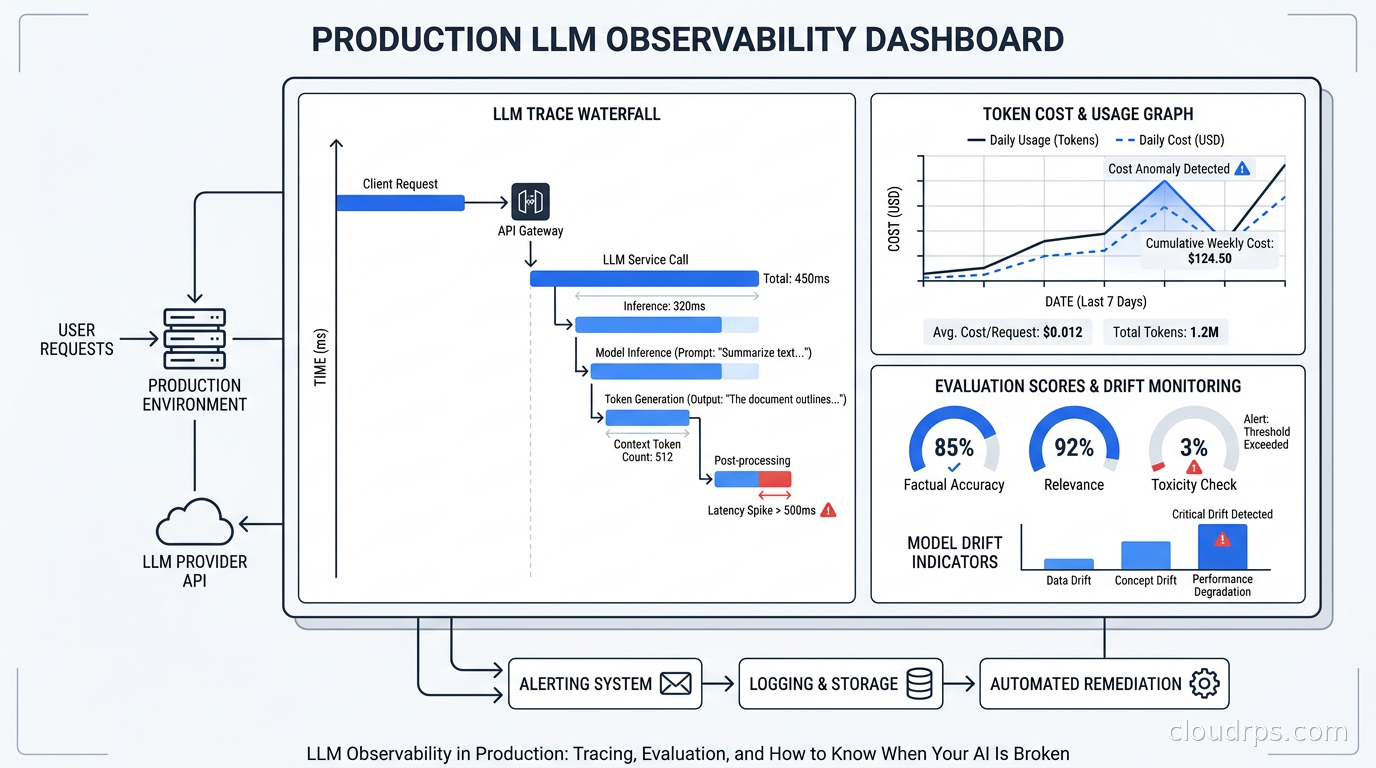
A practical guide to instrumenting LLM applications with OpenTelemetry GenAI semantic conventions, choosing between Langfuse, LangSmith, and Arize Phoenix, tracking token costs, and running evaluation in production.
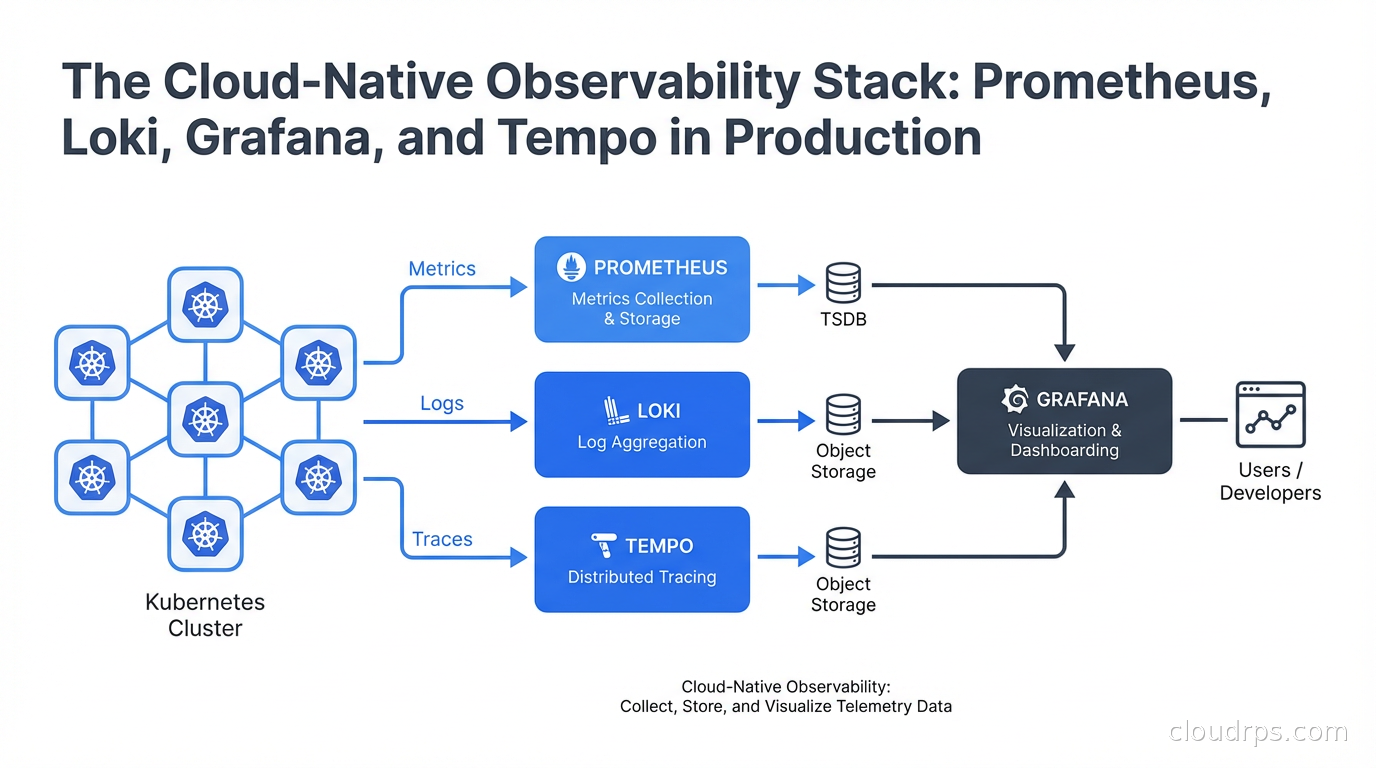
A deep-dive into building a production-grade observability stack with Prometheus, Loki, Grafana, and Tempo. Learn the architecture, scaling trade-offs, cardinality traps, and when the open-source stack beats a $40k/month SaaS bill.
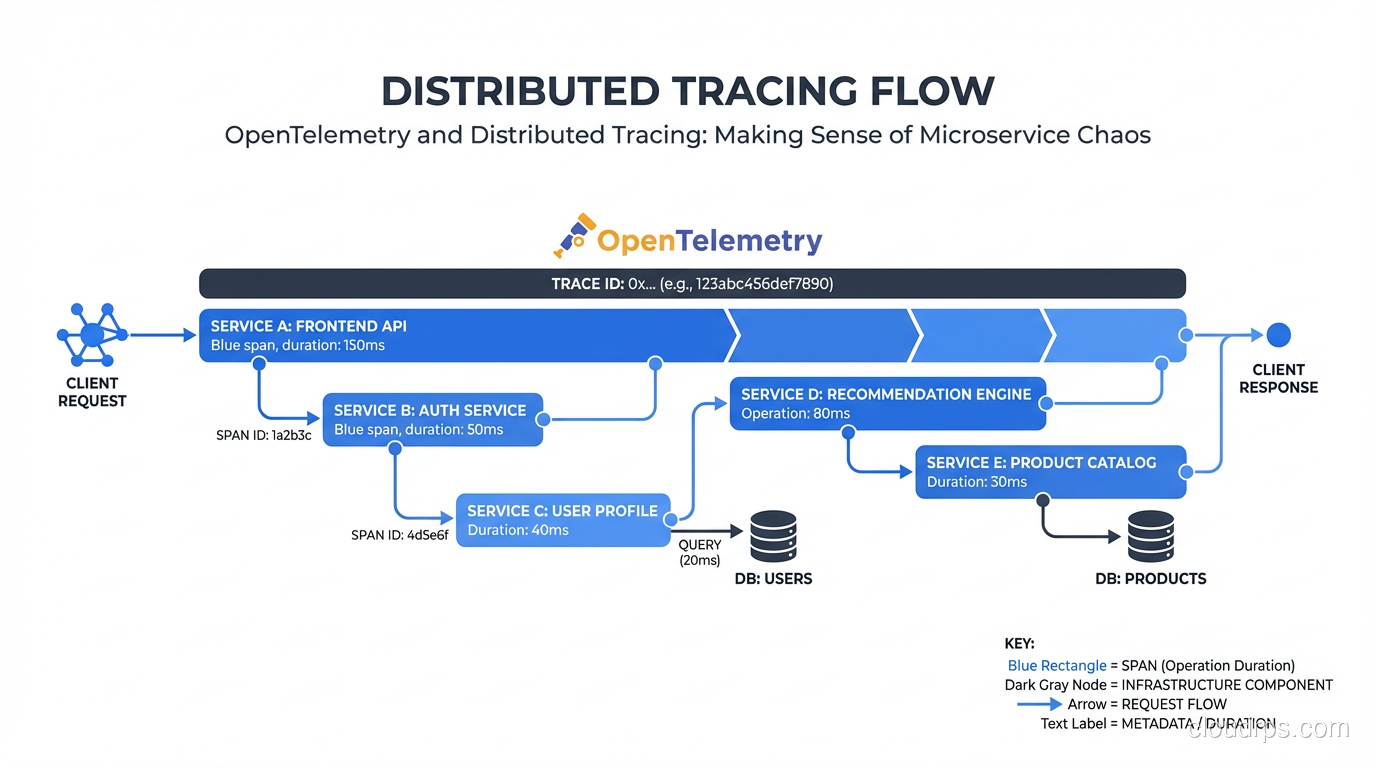
How OpenTelemetry works, why distributed tracing is different from logging and metrics, and how to instrument your services without drowning in overhead and noise.
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.