DevOps
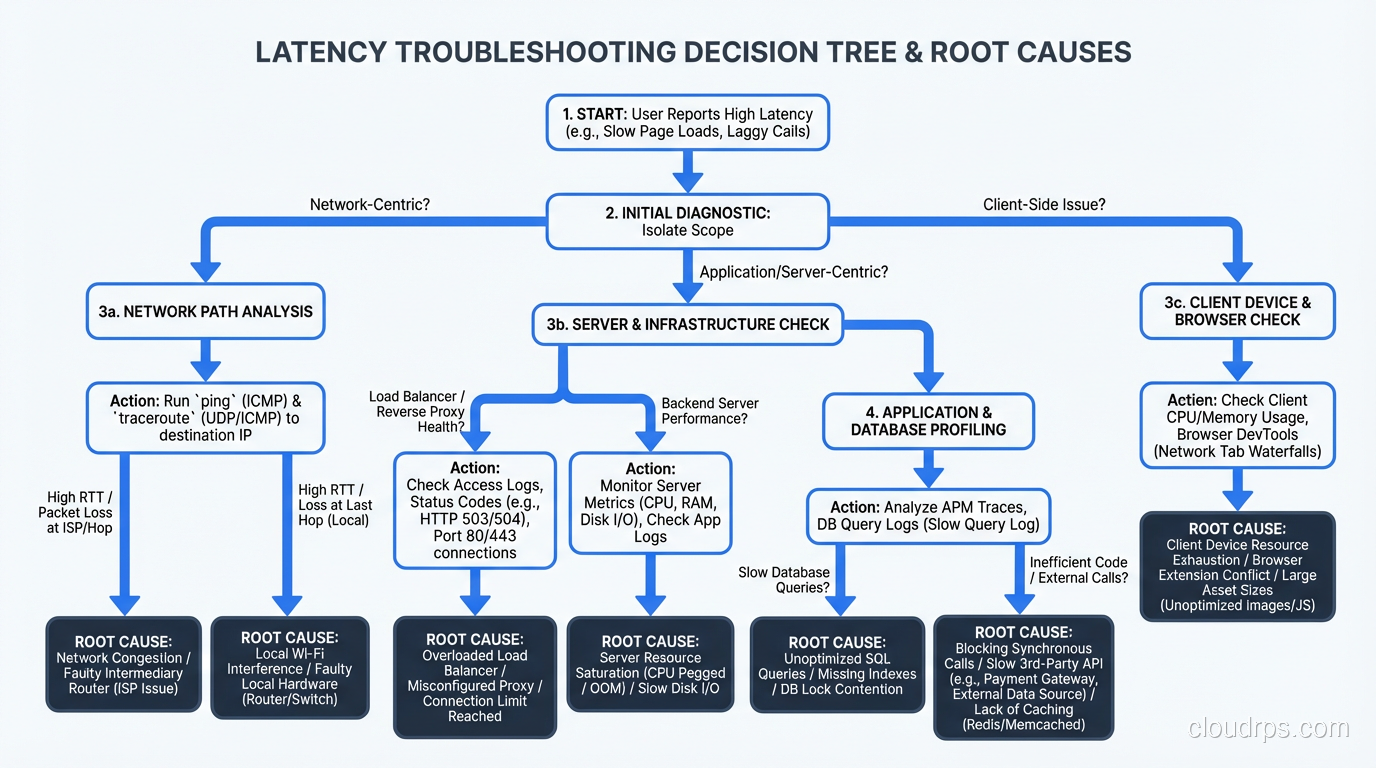
Troubleshooting Latency: A Systematic Approach to Finding the Bottleneck
A systematic method for tracking down latency issues in production systems, from network to application to database, built from decades of war stories.
A systematic method for tracking down latency issues in production systems, from network to application to database, built from decades of war stories.
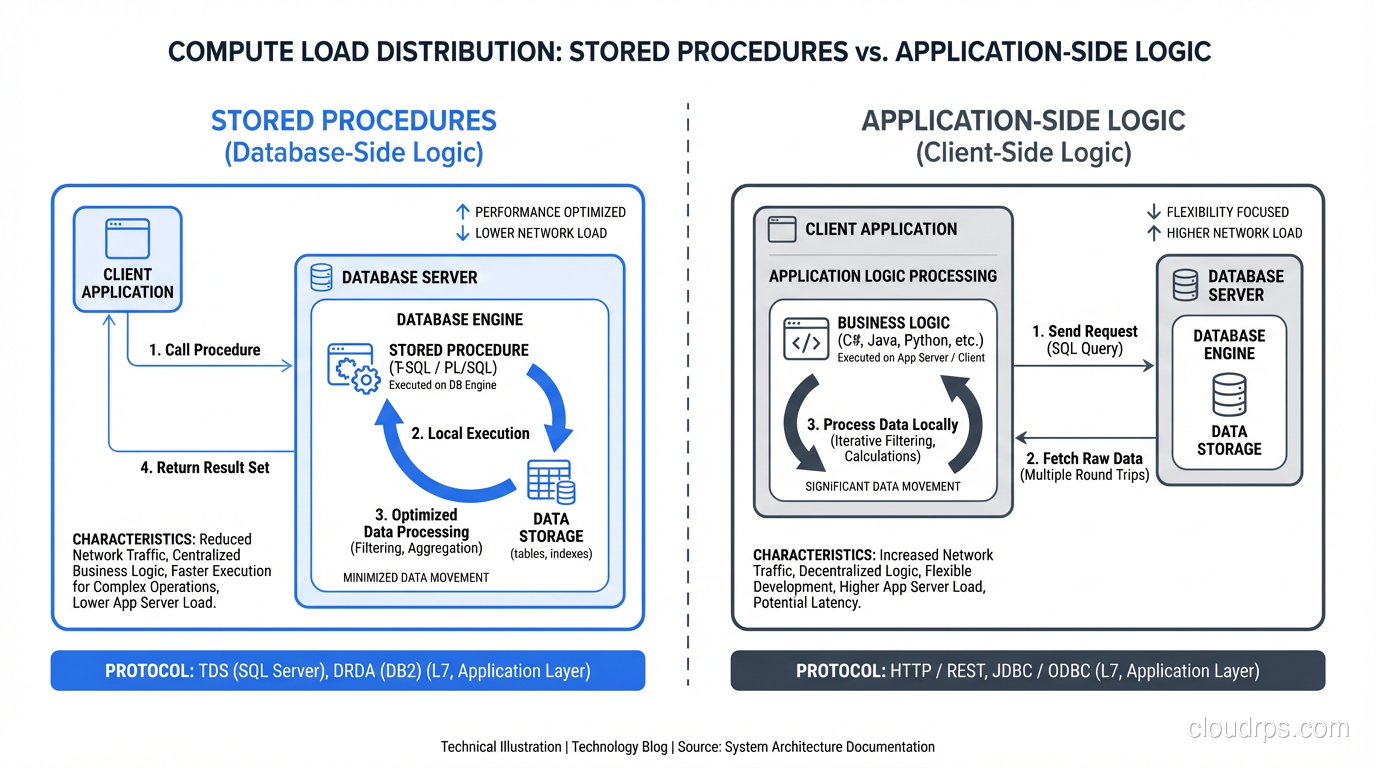
Opinionated guide to stored procedures covering performance benefits, maintainability costs, security implications, and practical guidelines for when they help vs hurt.
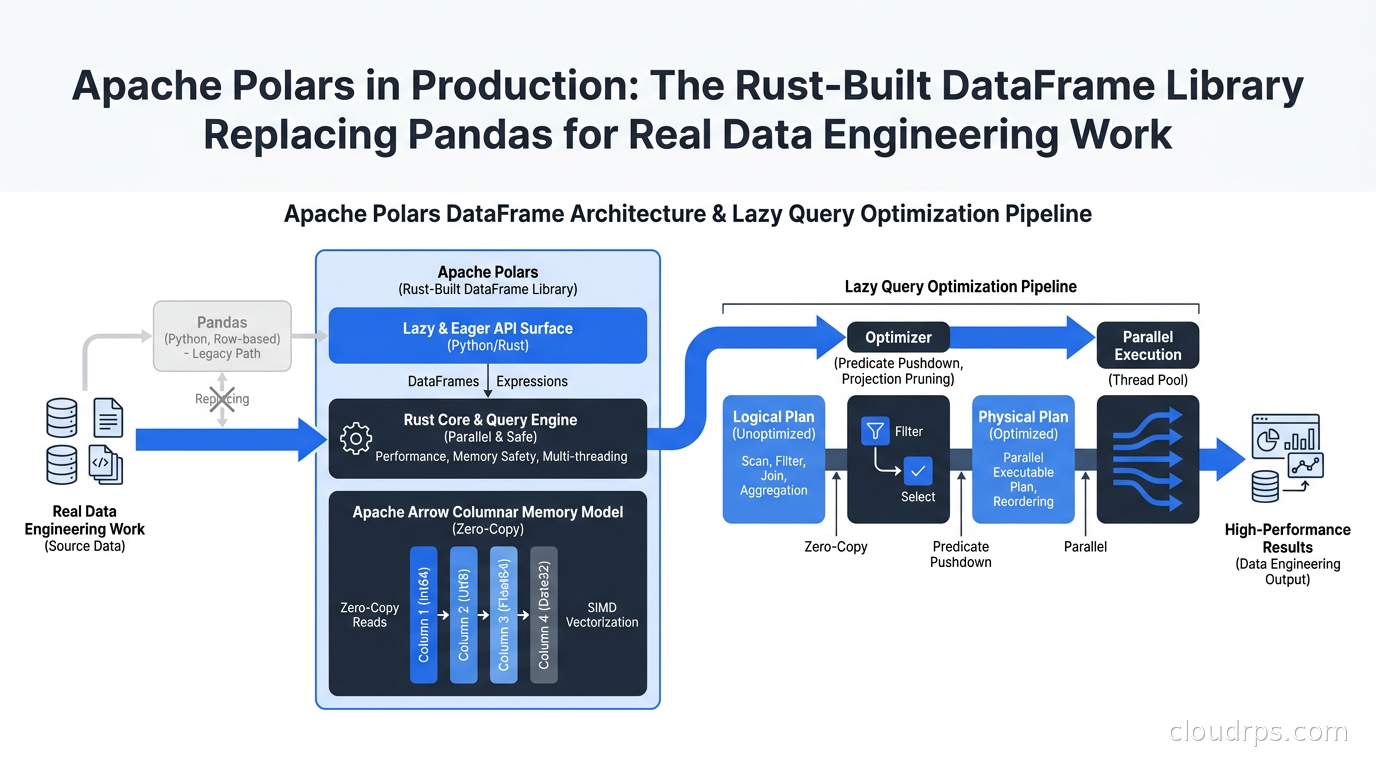
A principal cloud architect's guide to Apache Polars: why this Rust-based DataFrame library is replacing pandas in production pipelines, how lazy evaluation and Apache Arrow make it dramatically faster, and where it fits in the modern data stack alongside DuckDB and Apache Iceberg.
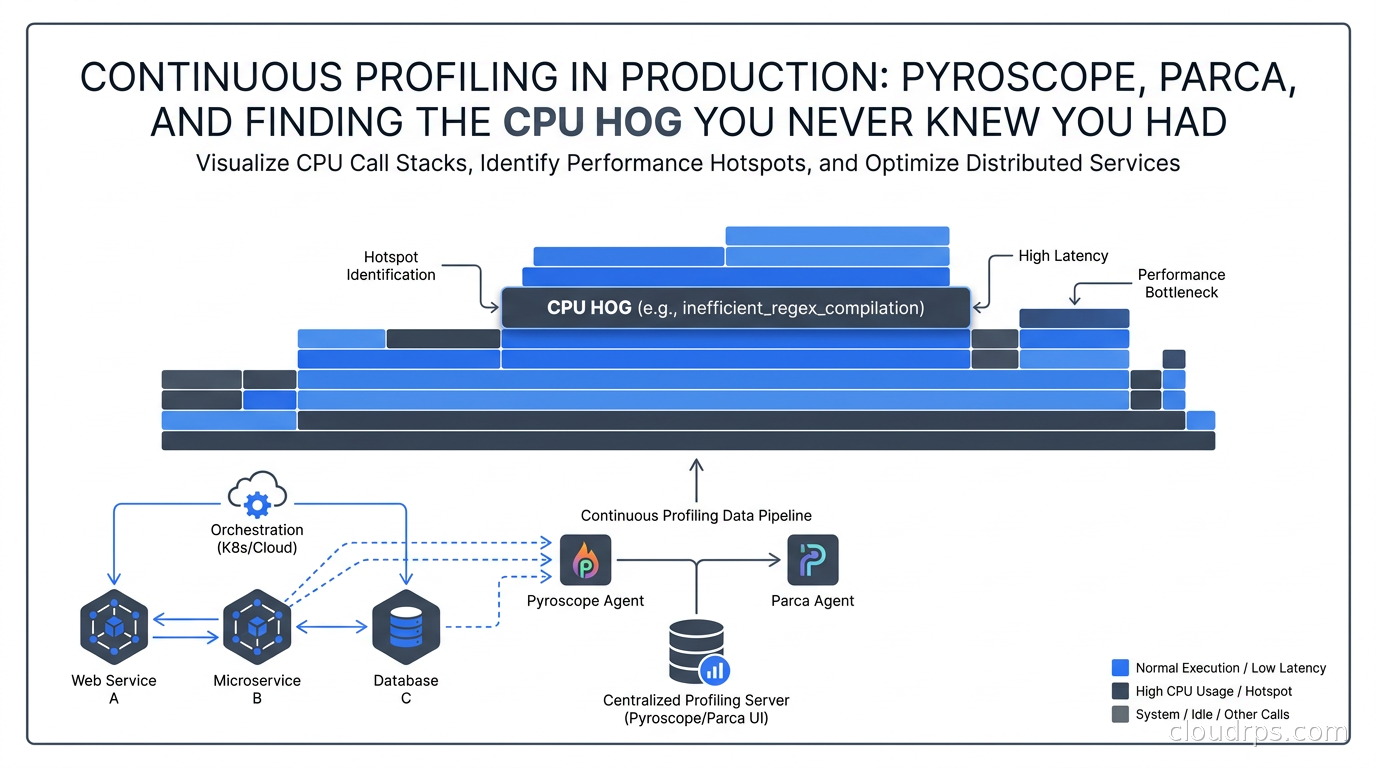
Continuous profiling is the fourth pillar of observability most teams skip. Learn how Pyroscope, Parca, and eBPF-based profilers find CPU and memory bottlenecks that metrics and traces can't.
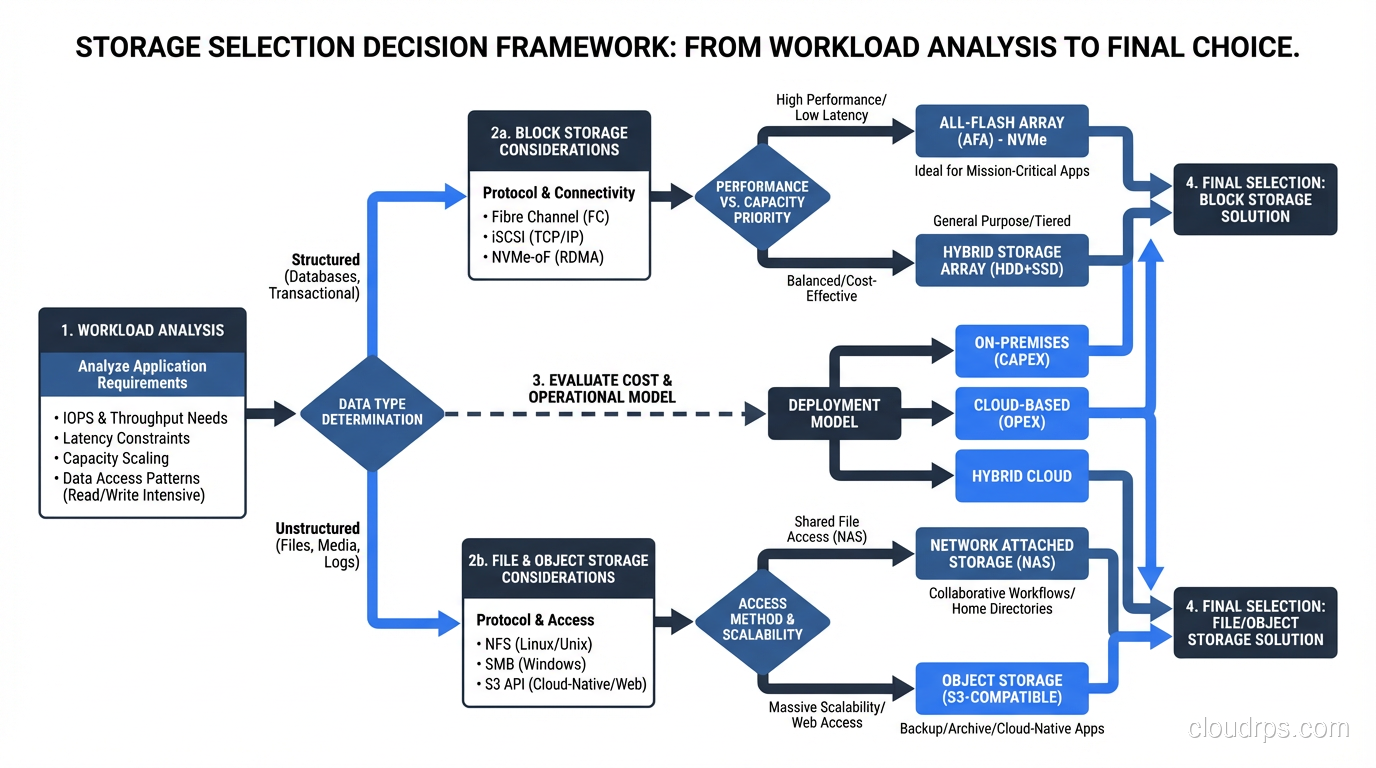
Practical guide to choosing SSD or HDD storage for databases, analytics, and archival workloads based on real-world performance, cost, and endurance tradeoffs.
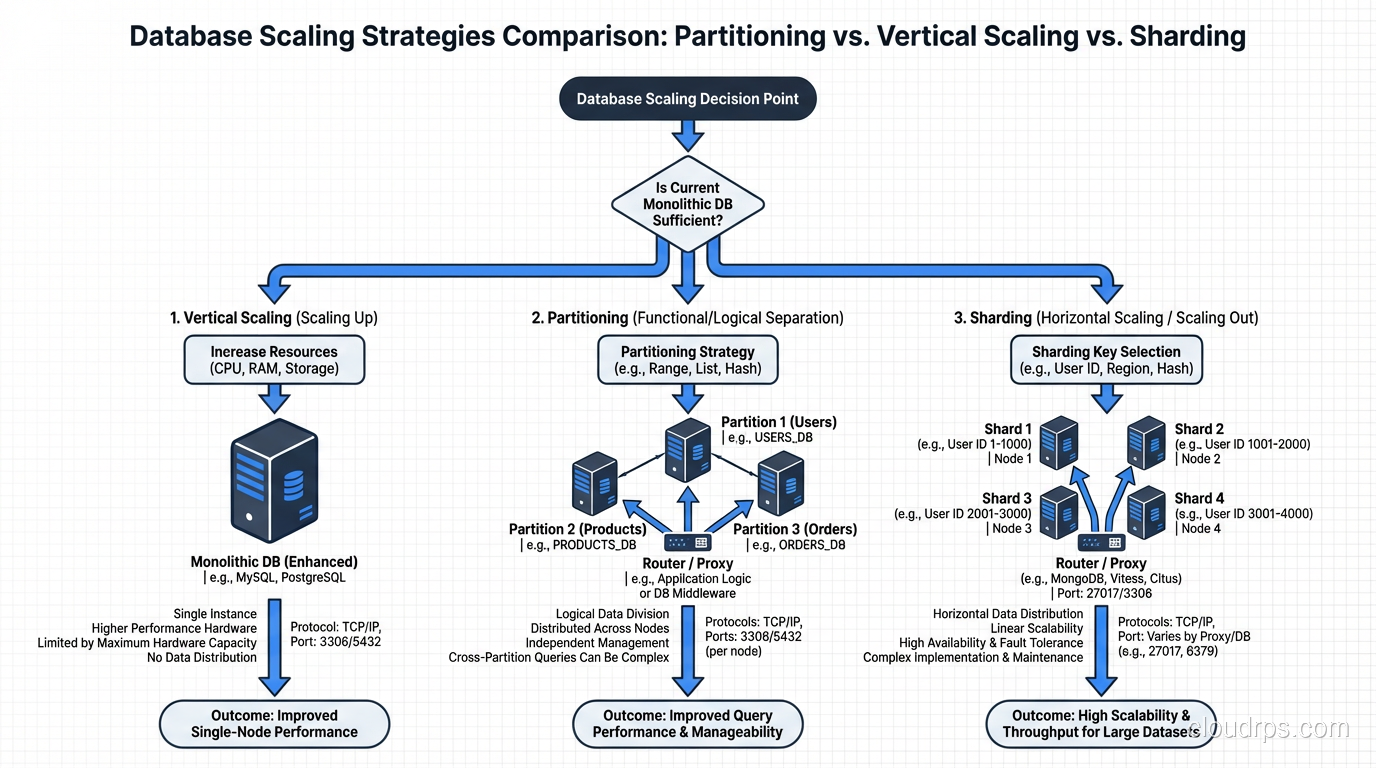
Sharding and partitioning are related but different database scaling strategies. A veteran architect explains both approaches, their trade-offs, and when to use each.
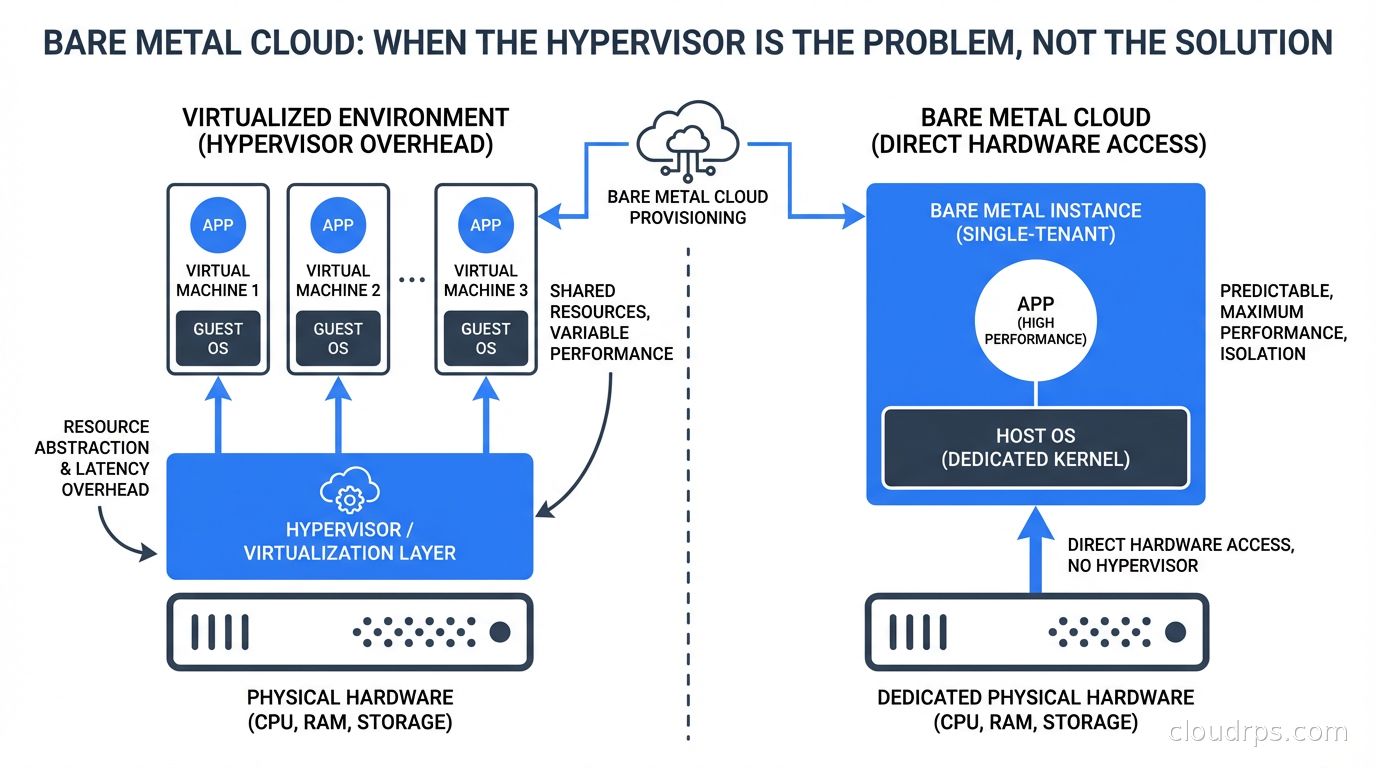
Virtual machines are the default in cloud computing, but for a growing set of workloads, the hypervisor is pure overhead. Bare metal cloud gives you dedicated hardware without the colocation operations burden. Here's when it makes sense.
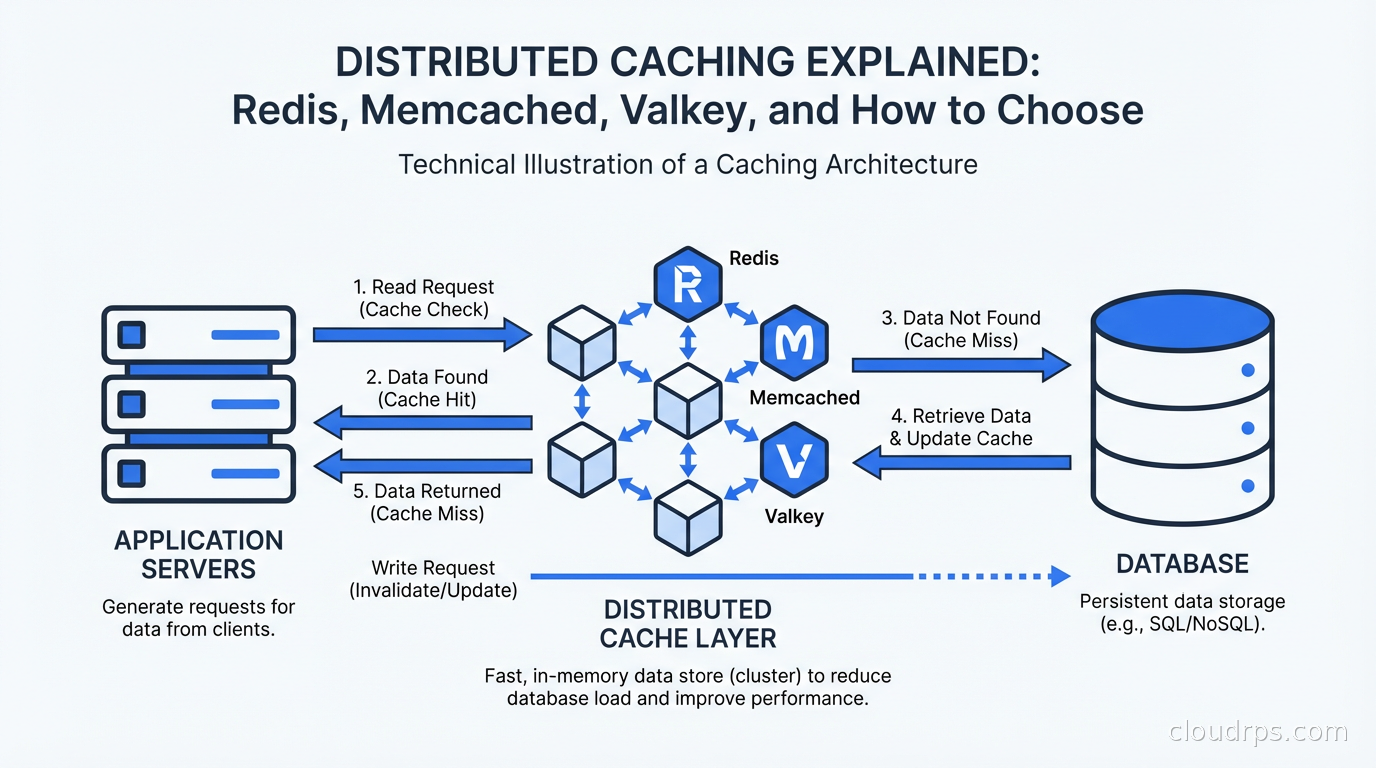
A principal architect's guide to distributed caching: how Redis, Memcached, and Valkey work, when to use each, and lessons from running caches at scale in production.
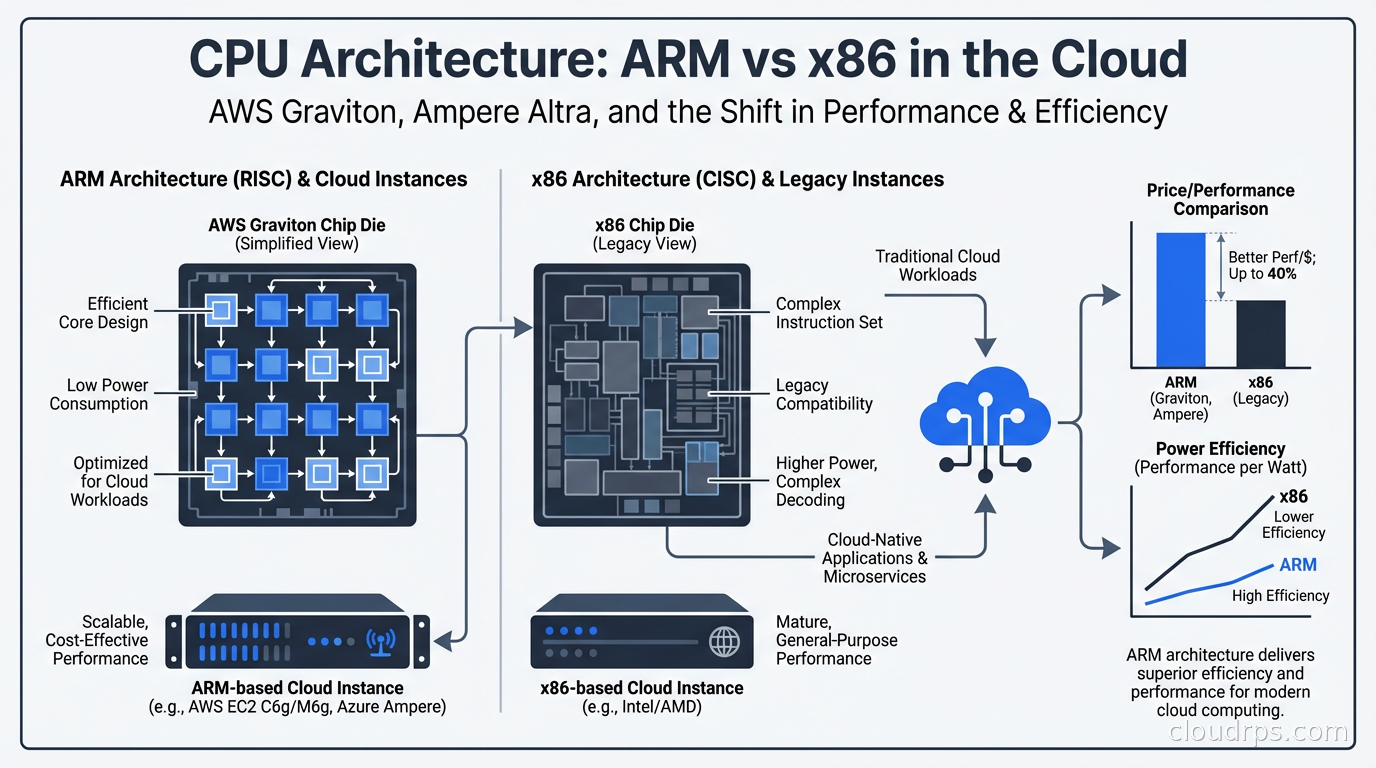
ARM-based cloud instances are delivering 40-60% better price-performance than x86 equivalents. Here's how AWS Graviton and Ampere Altra work, what workloads benefit most, and how to migrate.
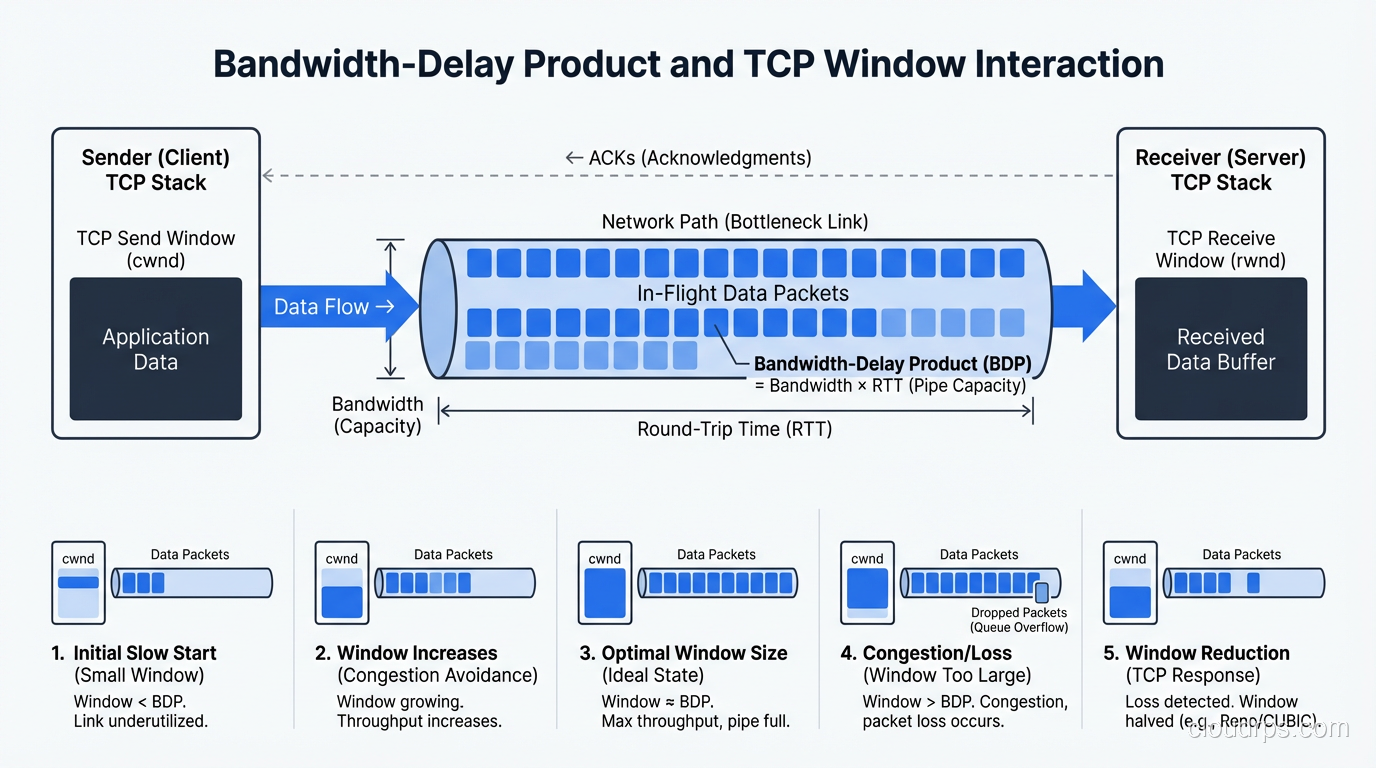
Understand the critical difference between latency and bandwidth, why both matter for performance, and how to optimize each in real-world cloud and network architectures.
Practical deep dives on infrastructure, security, and scaling. No spam, no fluff.
By subscribing, you agree to receive emails. Unsubscribe anytime.